
ArrayBuffer
ArrayBuffer 是用来表示通用的原始二进制数据缓冲区,本质是一个字节数组
const buffer = new ArrayBuffer(16) // 创建一个长度为 16 Byte 的 buffer
console.log(buffer.byteLength) // 16注意:创建后长度固定,不可调整
它会分配一个 16 字节的连续内存空间,并用 0 进行预填充
ArrayBuffer不是Array
ArrayBuffer是对固定长度的连续内存空间的引用,不同与Array:
- 它的长度是固定的,无法增加或减少它的长度
- 它正好占用了内存中的那么多空间
- 要访问单个字节,需要另一个“视图”对象,而不是
buffer[index]- 没有
Array.prototype上push、pop等方法
ArrayBuffer 本身不能直接读写,需要借助数据视图:
TypedArray视图:如Uint8Array、Float32ArrayDataView视图:更灵活,支持任意偏移和字节长度
类型化数组(TypedArray)
ArrayBuffer 是一个内存区域,它里面存储了什么无从判断,只是一个原始的字节序列。想要操作 ArrayBuffer,需要使用“视图”对象。视图对象本身并不存储任何东西,它是一副“眼镜”,透过它来解释存储在 ArrayBuffer 中的字节
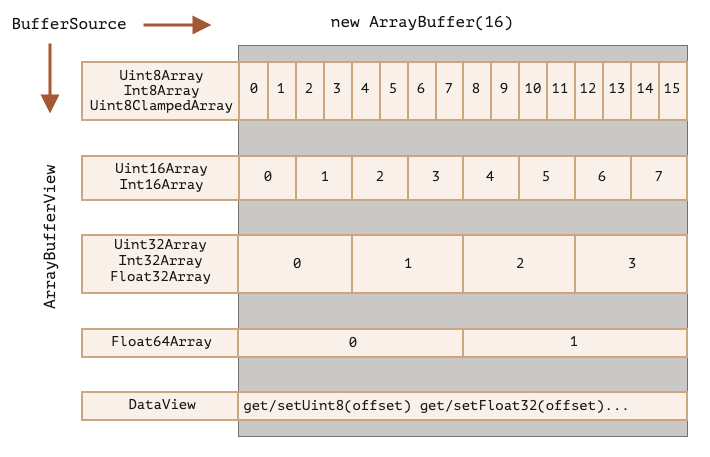
| 类型化数组 | 每个元素所占字节数 | 描述(C 语言中的数据类型) |
|---|---|---|
Int8Array | 1 | 8 位整型数(signed char) |
UInt8Array | 1 | 8 位无符号整型数(unsigned char) |
Uint8ClampedArray | 1 | 8 位无符号整型数,溢出时有特殊处理 |
Int16Array | 2 | 16 位整型数(signed short) |
UInt16Array | 2 | 16 位无符号整型数(unsigned short) |
Int32Array | 4 | 32 位整型数(signed int) |
UInt32Array | 4 | 32 位无符号整型数(unsigned int) |
BigInt64Array | 8 | 64 位整型数(signed long / long long) |
BigUint64Array | 8 | 64 位整型数(unsigned long / long long) |
Float32Array | 4 | 单精度 32 位浮点数(float) |
Float64Array | 8 | 双精度 64 位浮点数(double) |
构造器
书写
TypedArray的说明没有名为
TypedArray的构造器,它只是表示ArrayBuffer上的视图之一的通用总称术语当你看到
new TypedArray之类的内容时,它表示new Int8Array、new Uint8Array及其他中之一
new TypedArray(buffer, byteOffset?, length?)buffer:ArrayBuffer或SharedArrayBufferbyteOffset:视图的起始字节位置(即:跳过几个字节长度的数据),默认为 0length:视图的字节长度,默认至buffer的末尾
new TypedArray(object)- 给定的是
Array,或类数组对象,或可迭代对象,则会创建一个相同长度的类型化数组,并复制其内容 - 如:
new Uint8Array([0, 1, 2, 3])
- 给定的是
new TypedArray(typedArray)- 创建一个相同长度的类型化数组,并复制其内容(复制底层
ArrayBuffer)
- 创建一个相同长度的类型化数组,并复制其内容(复制底层
new TypedArray(length?)- 创建类型化数组以包含这么多元素,默认为 0
- 它的字节长度将是
length乘以单个TypedArray.BYTES_PER_ELEMENT中的字节数
可以直接创建一个 TypedArray,而无需提及 ArrayBuffer。但是,视图离不开底层的 ArrayBuffer,因此,除第一种情况(已提供 ArrayBuffer)外,其他所有情况都会自动创建底层 ArrayBuffer
属性
如要访问底层的 ArrayBuffer,在 TypedArray 中有如下的属性:
buffer:引用底层ArrayBufferbyteLength:底层ArrayBuffer的长度(即:数据占用字节数)byteOffset:当前视图相对底层ArrayBuffer的偏移值
其他属性:
length:包含多少元素BYTES_PER_ELEMENT:每个元素占用的字节数
方法 ^1
TypedArray 具有和 Array 相同的方法设计,可以设置获取元素(arr[i]、set、get)、查找(indexOf、lastIndexOf)、填充(fill)、切片(slice)、反转(reverse)、排序(sort)、拼接字符串(join)、遍历(forEach、map、find、reduce )等
但没有 push、pop、shift、unshift、splice、concat 等会改变数组长度的方法
还有两种 Array 没有的方法:
arr.set(fromArr, offset?):从offset(默认为 0)开始,将fromArr中的所有元素复制到arrarr.subarray(begin?, end?):创建一个从begin到end(包头不包尾)相同类型的新视图。这类似于slice方法,但不复制任何内容(只是创建一个新视图,以对给定片段的数据进行操作)
溢出处理
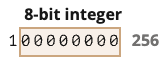
如果尝试将越界值写入类型化数组,多余的高位数据将会被忽略
如尝试将 256 放入 Uint8Array,则超出的最高位的 1 会被忽略,因此结果是 0:
Uint8ClampedArray 在这方面比较特殊,它的表现不太一样。对于大于 255 的任何数字,它将保存为 255,对于任何负数,它将保存为 0。此行为对于图像或颜色处理很有用
数据视图(DataView)
类型化数组限制了数据每个元素的字节大小,而 DataView 是在 ArrayBuffer 上的一种超灵活的“未类型化”视图,它允许以任何格式访问任何偏移量(offset)的数据
- 类型化的数组:构造器决定了其格式,整个数组是统一的,第
i个元素是arr[i] DataView:可以使用.getUint8(offset)或.getUint16(offset)之类的方法访问数据。在调用方法时选择格式,而不是在构造的时候
构造器
new DataView(buffer, byteOffset?, byteLength?)buffer:ArrayBuffer或SharedArrayBufferbyteOffset:视图的起始字节位置(即:跳过几个字节长度的数据),默认为 0length:视图的字节长度,默认至buffer的末尾
DataView 与类型化数组不同,只有这一个构造器,即 DataView 不会自行创建缓冲区,需要事先准备好
属性
buffer:引用底层ArrayBufferbyteLength:底层ArrayBuffer的长度(即:数据占用字节数)byteOffset:当前视图相对底层ArrayBuffer的偏移值
方法
没有与 Array 或 TypedArray 相类型的方法,只有对不同偏移量读写的方法:
getXxx(byteOffset, littleEndian?):获取指定字节偏移量处的数据setXxx(byteOffset, value, littleEndian?):设置指定字节偏移量处的数据Xxx:Int8|Uint8|Int16|Uint16|Int32|Uint32|BigInt64|BigUint64|Float32|Float64之一littleEndian:采用何种字节序false或者未指定(undefined):大端序true:小端序
字节序
字节序或字节顺序描述了计算机如何组织构成数字的字节
- 小端序:从最低有效位到最高有效位的顺序存储字节(即:低位字节排放在内存的低地址端,高位字节排放在内存的高地址端)
- 形象类比:31 December 2050
- 现代电脑大部分使用小端序,所有的英特尔处理器都使用小端序
- 大端序:从最高有效位到最低有效位的顺序存储字节(即:高位字节排放在内存的低地址端,低位字节排放在内存的高地址端)
- 形象类比:2050-12-31
- 互联网标准,从标准 Unix 套接字层开始,一直到标准化网络的二进制数据结构,通常要求数据使用大端序存储。此外,老式 Mac 计算机的 68000 系列和 PowerPC 微处理器曾使用大端序
例如,用不同字节序存储数字 0x12345678:
- 小端序:
0x78 0x56 0x34 0x12 - 大端序:
0x12 0x34 0x56 0x78 - 混合序(曾经的做法,非常罕见):
0x34 0x12 0x78 0x56
Blob
Blob 全称 Binary Large Object,表示一个不可变的原始数据块,支持文本和二进制数据
特点:
- 不可变性:一旦创建,内容不能修改
- 可封装任意类型的数据:字符串、
ArrayBuffer、TypedArray等 - 支持 MIME 类型描述,方便浏览器识别用途
创建方式:
const blob = new Blob(
["Hello World"],
{ type: "text/plain" }
);切片操作:
const slicedBlob = blob.slice(0, 5, "text/plain");核心功能与应用场景
| 功能 | 说明 |
|---|---|
| 分片上传 | .slice(start, end) 方法可用于大文件切片上传 |
| 本地预览 | canvas.toBlob() 导出图像,配合 URL.createObjectURL 预览 |
| 文件下载 | 使用 a 标签 + createObjectURL 实现无刷新下载 |
| 缓存资源 | Service Worker 中缓存 Blob 数据提升性能 |
| 处理用户上传 | 结合 FileReader 和 File API 操作用户文件 |
File
File 对象继承自 Blob,额外包含:文件名 name ,最后修改时间 lastModified ,可以理解为:带有元数据的 Blob
创建方式:
const file = new File(
["Hello World"],
"example.txt",
{ type: "text/plain" }
);获取方式
一般通过用户上传的文件获取
示例:
// <input type="file">
const input = document.getElementById("input");
input.onchange = (event) => {
const files = event.target.files;
console.log("Files:", files); // FileList
};FileReader
FileReader 是一个用于异步读取 Blob 或 File 内容的接口
常用实例方法
| 方法 | 说明 |
|---|---|
readAsArrayBuffer() | 读取为 ArrayBuffer,适合二进制 |
readAsText() | 读取为字符串 |
readAsDataURL() | 读取为 Base64 编码 |
常用属性
readyState: 当前读取状态result: 读取完成后的数据(异步获取)
示例:读取 Blob 并输出文本
let blob = new Blob(["Hello World!"], { type: "text/plain" });
blob = blob.slice(0, 5, "text/plain");
const fileReader = new FileReader();
fileReader.readAsText(blob);
fileReader.onload = function() {
console.log(fileReader.result); // Hello
};ObjectURL
ObjectURL 用于为 Blob 或 File 对象生成一个临时 URL,可直接在 <img>、<a>、iframe 等 标签中使用
示例:文件选择并预览
const input = document.getElementById("input");
const image = document.getElementById("image");
input.onchange = (event) => {
const file = event.target.files[0];
const url = URL.createObjectURL(file);
image.src = url;
};