大语言模型训练的三个阶段
- 预训练 (Pre-train):自我学习,累积实力
- 指令微调 (Instruction Fine-tuning):名师指点,激发潜力
- 强化学习 (Reinforcement Learning from Human Feedback, RLHF):参与实战,打磨技巧
背景知识:文字接龙
我们在之前了解到语言模型就是就是做文字接龙,将原本无穷无尽可能性答案的目标拆解成答案有限的一连串文字接龙
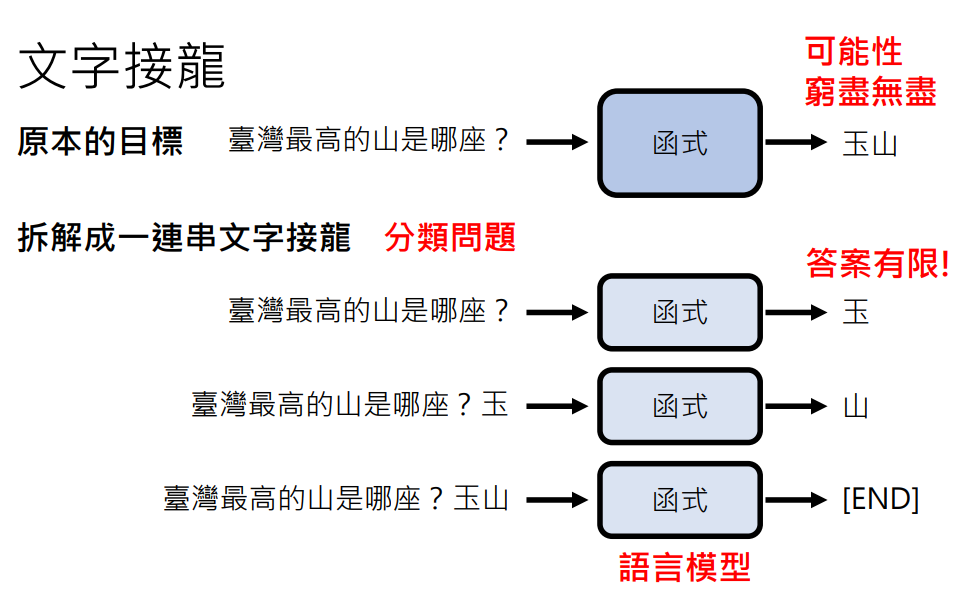
语言模型是通过深度学习的方法学会文字接龙的:
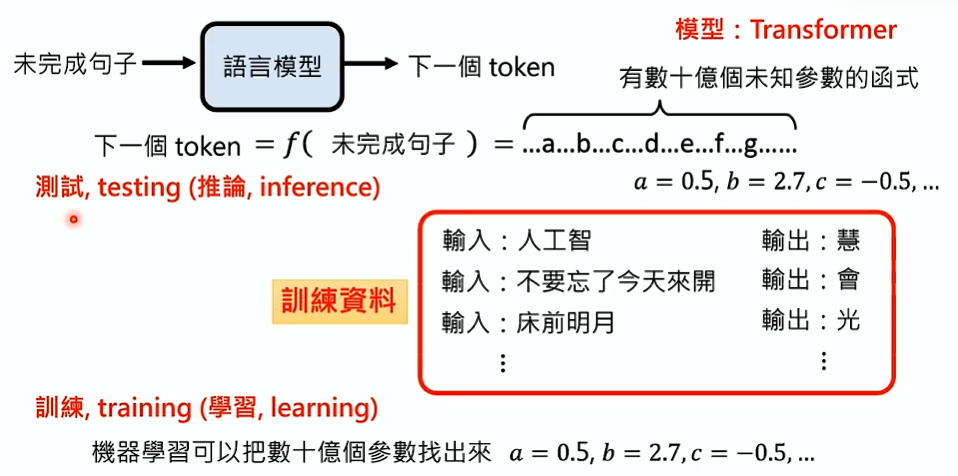
- 语言模型是有数十亿个未知参数的函式,这个函式就叫做模型
- 为了找出这数十亿个未知参数,给它很多有输入输出的训练资料进行训练
- 模型通过机器学习把这数十亿个未知参数找出来的过程叫做训练 (training) 或学习 (learning)
- 参数找出来后,就可以使用这个函式,给它一个新的句子输入让它输出下一个 token 的过程叫做测试 (testing) 或推论 (inference)
==上述的三个阶段都是通过这个方法在学文字接龙,只是训练资料不同而已==
找参数的挑战
训练
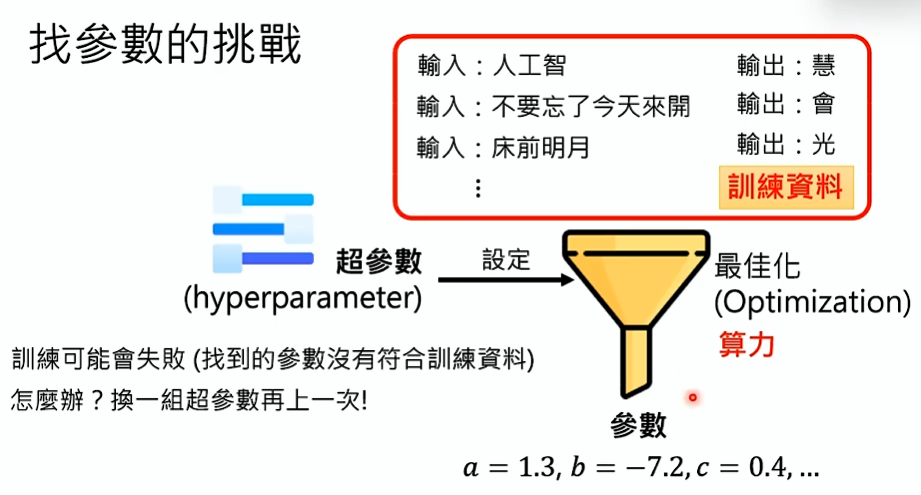
- 机器学习通过训练资料找出符合这个训练资料的数十亿个未知参数的过程叫做最佳化 (optimization)
- 实际上最佳化是如何进行的,在本课程不会详谈
- 现在只需要把最佳化想成一个机器,这个机器使用之前需要设定一些超参数 (hyperparameter)
- 设定这些超参数就决定了最佳化的方法,最佳化的方法固定下来后将训练资料丢到这个机器里进行一番运作,就找出了这数十亿未知参数
- 值得注意的是这个训练的过程不是每次都能成功,训练是有随机性的,有时候可能成功,有时候可能失败
- 失败是指:找到的参数没有符合训练资料。训练失败怎么办?换一组超参数再试一次!
- 这个训练过程十分消耗算力
- 训练模型常说的“调参数”指的是超参数,而不是数十亿未知参数,未知参数是机器自动找出来的
训练成功但测试失败
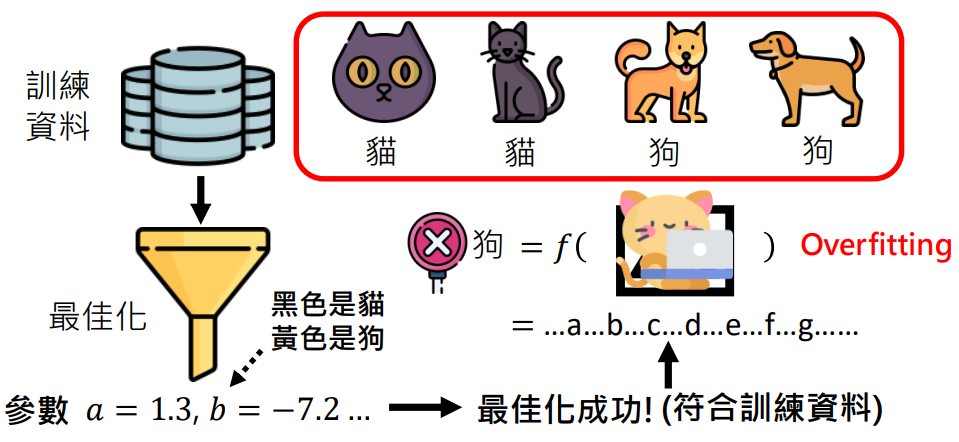
- 训练成功后,给一张训练资料中没有的图片进行测试,结果发现模型给出的结果是错的
- 这种训练成功但测试失败的情况就叫做过拟合 (overfitting)
- 这个例子是因为训练资料中的猫都是黑色、狗都是黄色,最佳化找到的参数以颜色认定
- 机器学习只管找到的参数有没有「符合」训练资料,不管有没有道理
如何让机器找到比较「合理」的参数
增加训练资料的多样性
上例中就是训练资料不够多样,导致过拟合
如果在训练资料中加入黄色的猫和黑色的狗,最佳化过程中机器就知道靠颜色的参数是不对的,迫使它找新的参数以符合训练资料
设置初始化参数
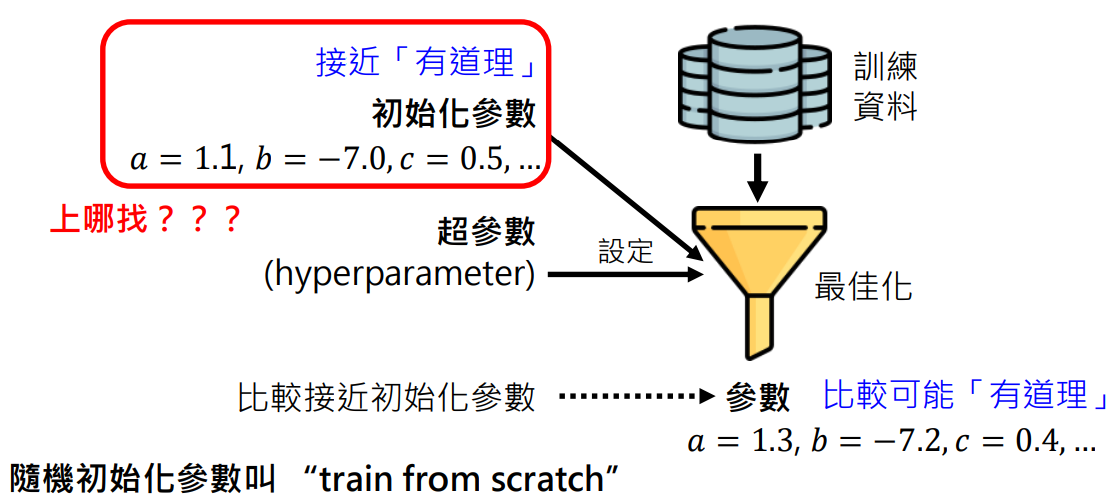
- 在最佳化过程中除了设定超参数外,还可以设定初始化参数
- 设定了初始化参数,那么机器学习找出来的参数会比较接近初始化参数。因为它会从初始化参数开始找起
- 怎么知道初始化参数怎么设置呢?通常是不知道!所以常见的作法是随机一些初始化参数,这种方法叫做 train from scratch
第一阶段:预训练
需要多少文字才够学会文字接龙
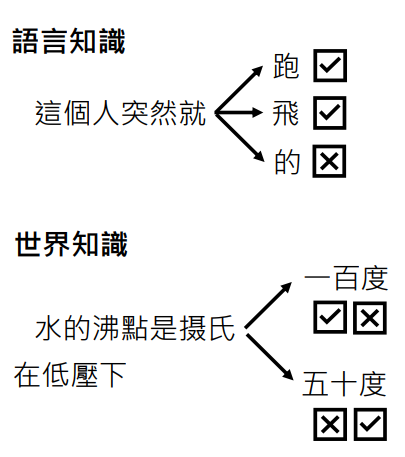
要正确的接出下一个 token,需要两方面的知识:
- 语言知识:人类语言的词法、语法
- 世界知识:物理、人文、……
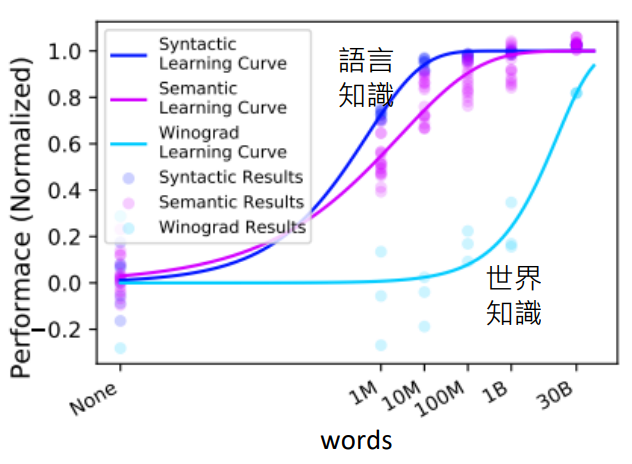
- 语言知识:1 亿 (10M) 个词汇就够了
- 世界知识:300 亿 (30B) 个词汇都不够
世界知识是非常复杂,而且有很多层次的,需要真正非常大量的资料才能让语言模型学会
比如上面的例子,对于小学生来说水的沸点是一百摄氏度是对的;但是对于中学生,知道水的沸点是和大气压相关的,在低压情况下水的沸点是有可能五十摄氏度,而非一百
从任何文字资料学习
网络上的资料可以说是无穷无尽的
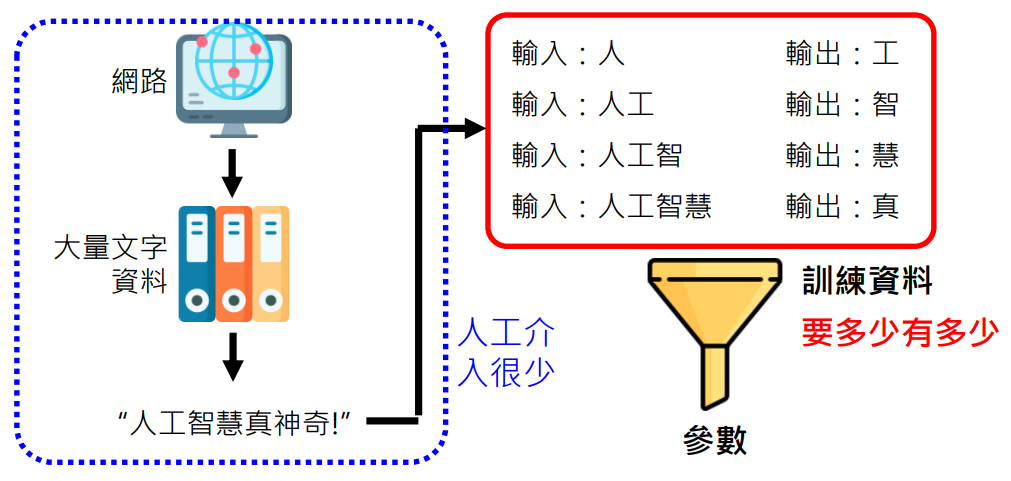
这种人工介入很少,就可以训练的方式叫做自督导式学习 (Self-supervised Learning)
资料清洗
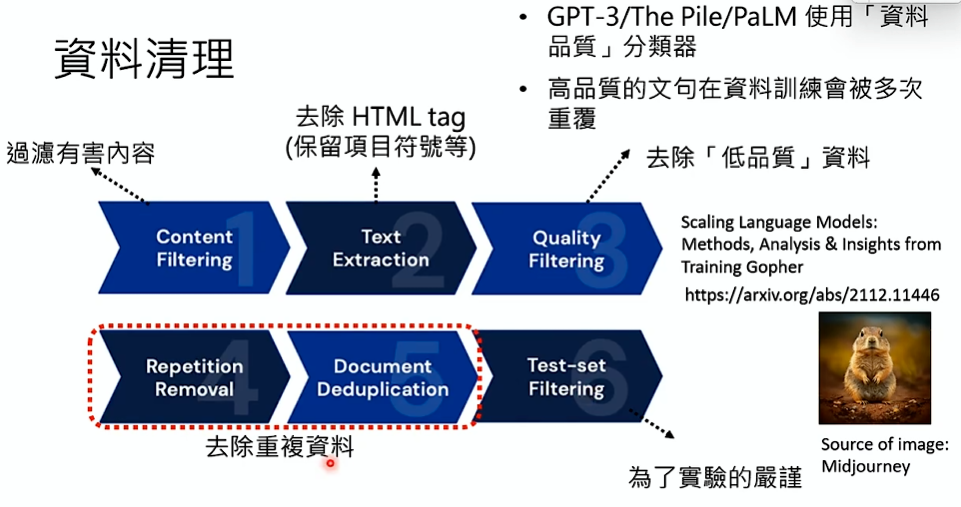
- Scaling Language Models: Methods, Analysis & Insights from Training Gopher
- Deduplicating Training Data Makes Language Models Better
所有文字资料都能拿来用吗
《泰晤士报》起诉 OpenAI 和 Microsoft 人工智能使用受版权保护的作品
ChatGPT 之前的 GPT 系列
| 年份 | 系列 | 参数量 | 训练资料量 |
|---|---|---|---|
| 2018 | GPT-1 | 117M | 7000 本书,大约 1GB |
| 2019 | GPT-2 | 1542M | 40GB |
| 2020 | GPT-3 | 175B | 580GB |
- 参数量就是机器学习要找出的未知参数个数,参数量越大,AI 越“聪明”,可以理解为 AI 的“天资”
- 训练资料量:理解为后天的努力
- 580GB 资料量的概念:300B tokens,相当于哈利波特全集 30 万遍
GPT-2 问答上表现如何?
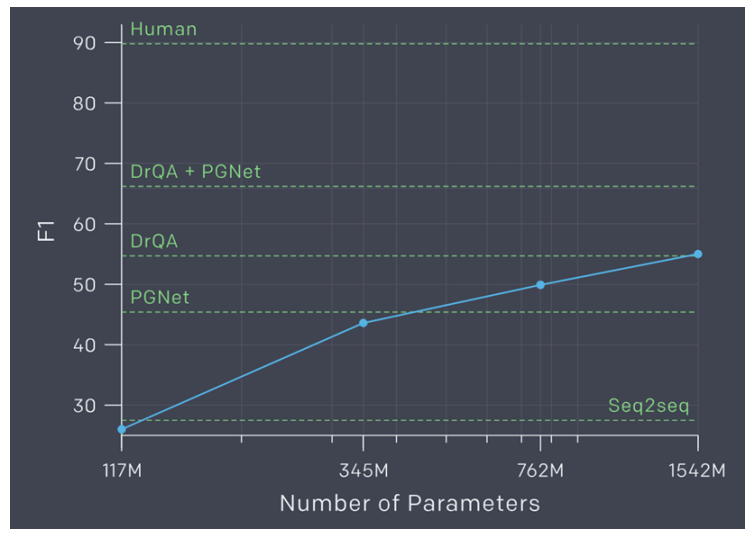
GPT-3 能好多少?
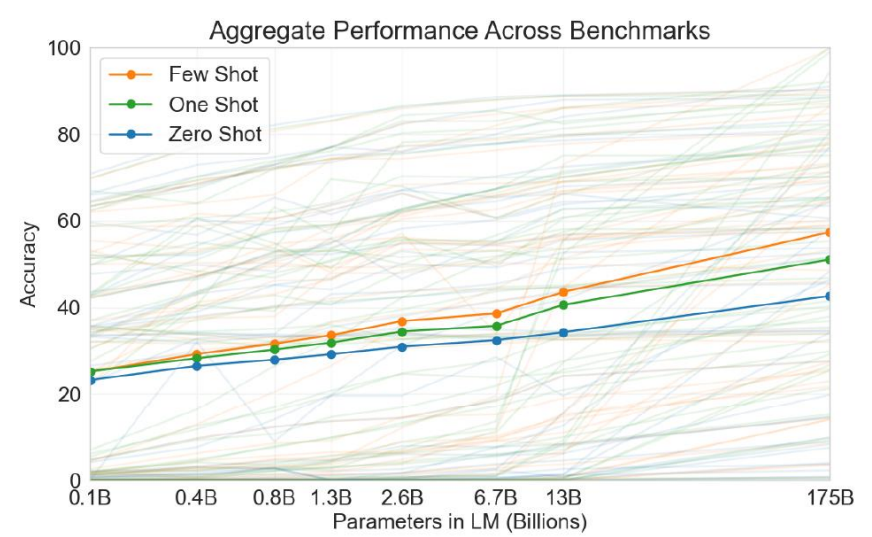
结论就是即使参数量和训练资料量多了几百几千倍,但效果并没有好多少
所以当年很多人觉得 OpenAI 走错方向了,文字接龙怎么可能接出人工智能来
再训练更大的模型也没用
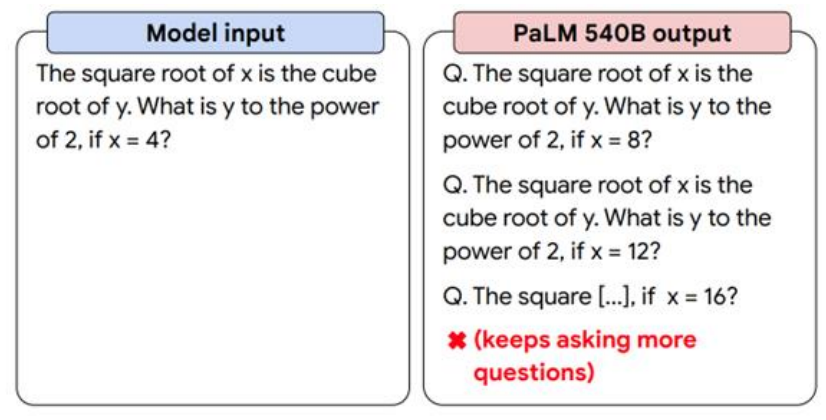
更大的模型也无法好好回答你的问题:你问它一个问题,它会接出更多问题
为什么语言模型不能好好回答问题
因为也没人教它要回答问题……
它的所有知识都是通过网络学的
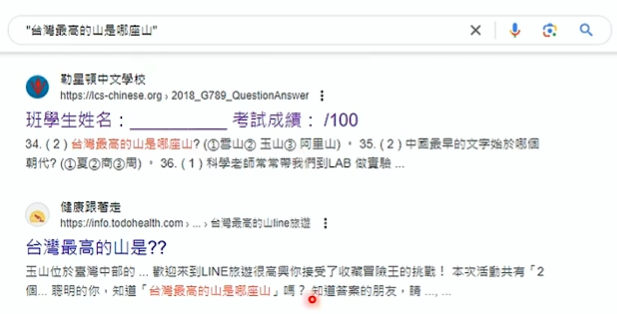
这个阶段语言模型在网络上学了很多东西,却不知道使用方法