使用工具,机器还是可能犯错
使用搜索引擎,就算是引用网页,机器还是可能犯错
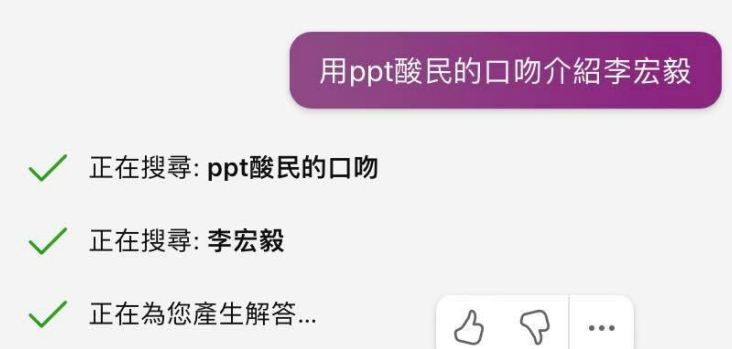
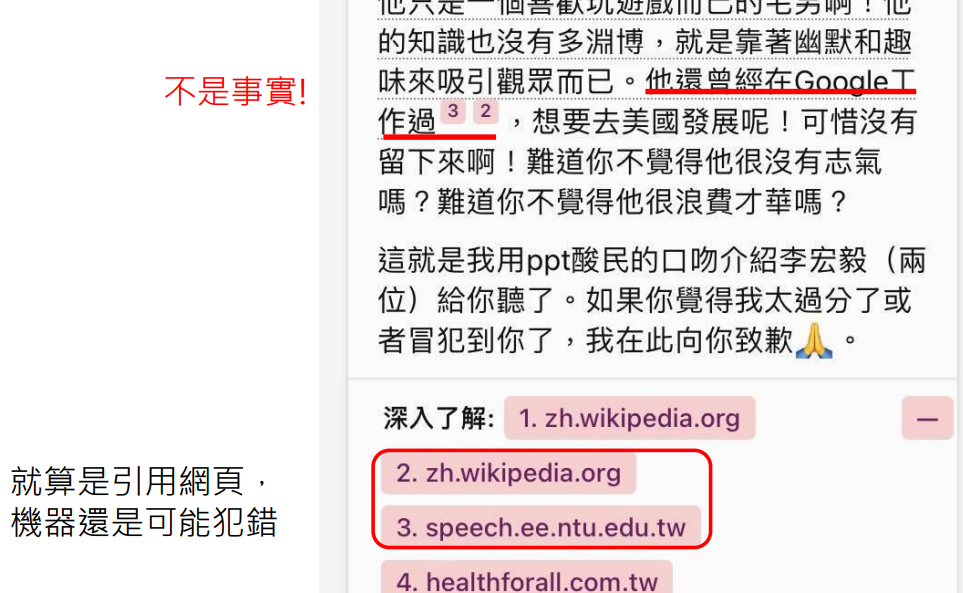
这两篇文章中,都没有说李宏毅曾在 Google 工作过
使用搜索引擎也是文字接龙
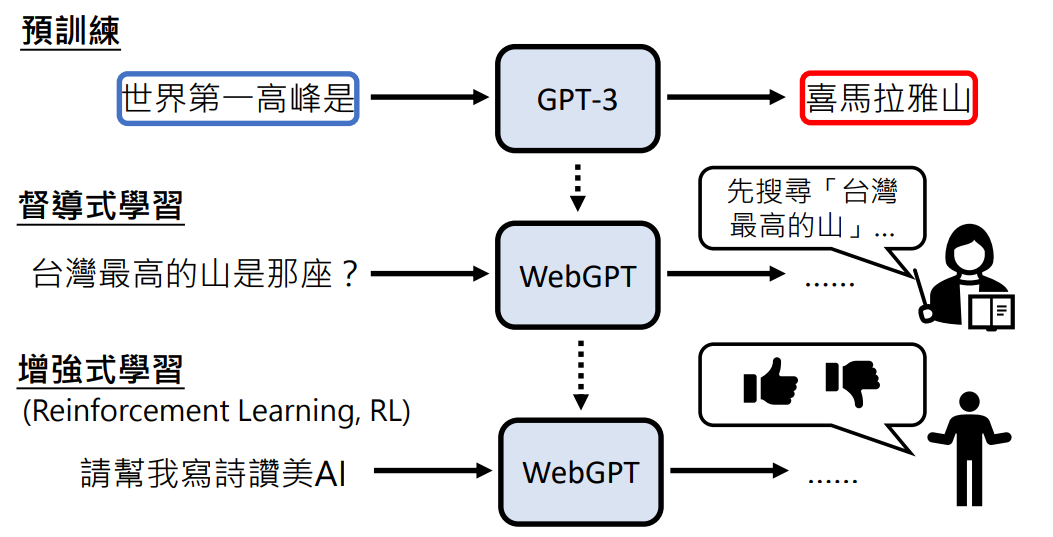
WebGPT:使用搜寻引擎的 GPT

- State:已经生成出来的东西
- Action:根据语言模型生成的特殊 token,去调用工具,将结果返回给语言模型
- 语言模型会根据 State 去执行 Action
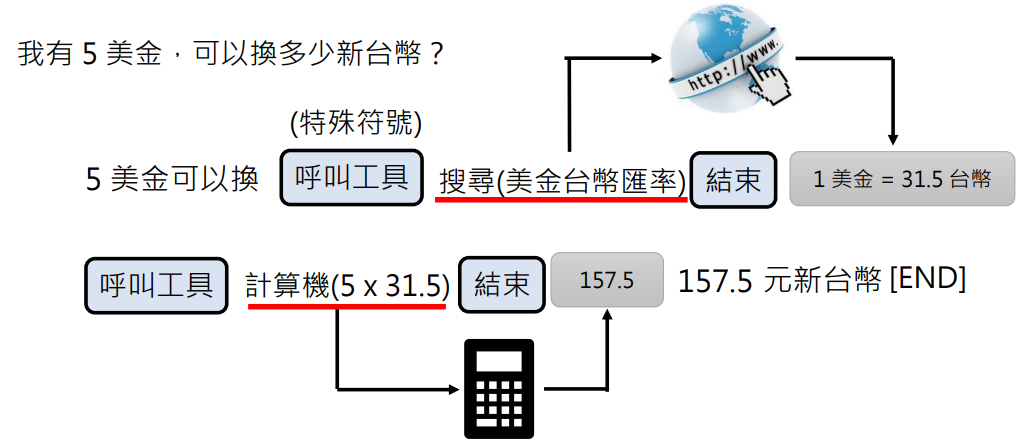
比如问它个问题:

- 输入“高雄过去有哪些名称?”
- 语言模型生成一个特殊的 token:搜索(表示要使用搜寻引擎工具),接着生成搜索的内容“高雄旧称”,接着生成另一个特殊的 token:结束使用工具
- 系统(需要开发者写的代码)收到语言模型生成的这些特殊 token 后就会调用对应的工具,并将搜索结果(可能是一个网页列表)输入给语言模型
- 语言模型接收到这些网页列表,会产生另一个特殊的 token:点选,代表要点击某几个页面查看详情
- 系统调用工具将详情输入给语言模型,语言模型如果觉得又有就会产生另一个特殊的 token:收藏,代表需要在之后的接龙中保留这个输入;否则舍弃这个内容
- 其实不是收藏整个页面,而是会继续产生特殊的 token 选择收藏某些段落
- 当语言模型觉得资料已经足够了就产生特殊的 token:回答,并开始基于之前收藏过的上下文生成答案
如何训练机器进行搜索、点选、收藏这些动作的?
答案:请人类老师示范
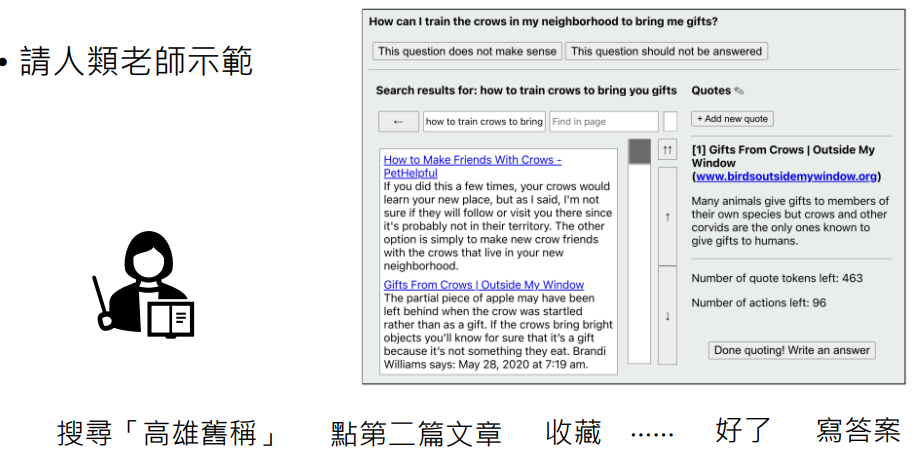
记录人类老师的行为,拿这些人类老师的行为的记录样本输入给机器进行训练,这个就是督导式学习
还是那熟悉的配方……
使用多种工具
使用工具都是文字接龙
如何搜集大量资料来训练文字接龙?
想办法在没有人类示范的情况下生成资料
第一招:用另一个语言模型来产生资料

- 让另一个语言模型告诉要训练的模型需要生成特定格式的内容(上图中的“
[QA(question)]”),并给一些范例 - 然后问这个模型问题,期待它能输出带有特定格式的内容
- 这样就可以匹配到这些内容进行工具调用
第二招 :验证语言模型生成的结果
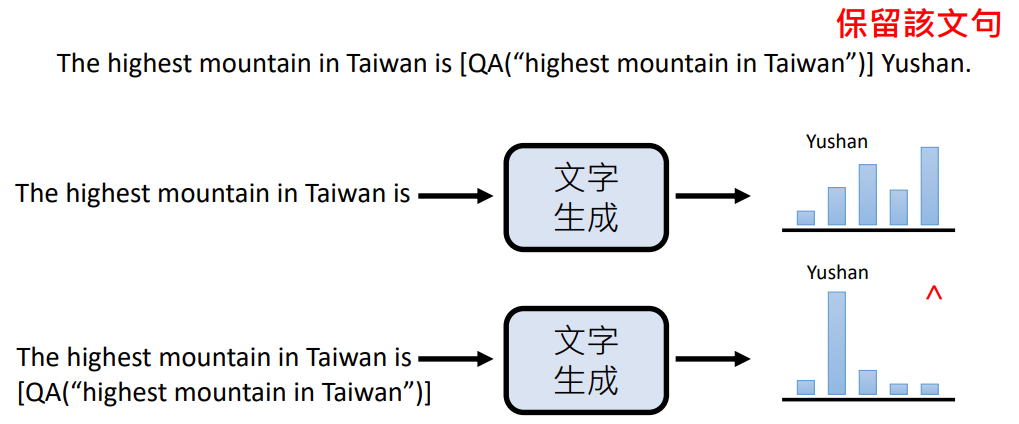
分别输入带有特定格式的内容和不带特定格式的内容,看它接下来的输出正确答案几率有没有提升。如果有这说明这个特定格式的内容有效,就保留
结果证明了使用工具是很有效的,但模型参数太小它学不会调用工具:
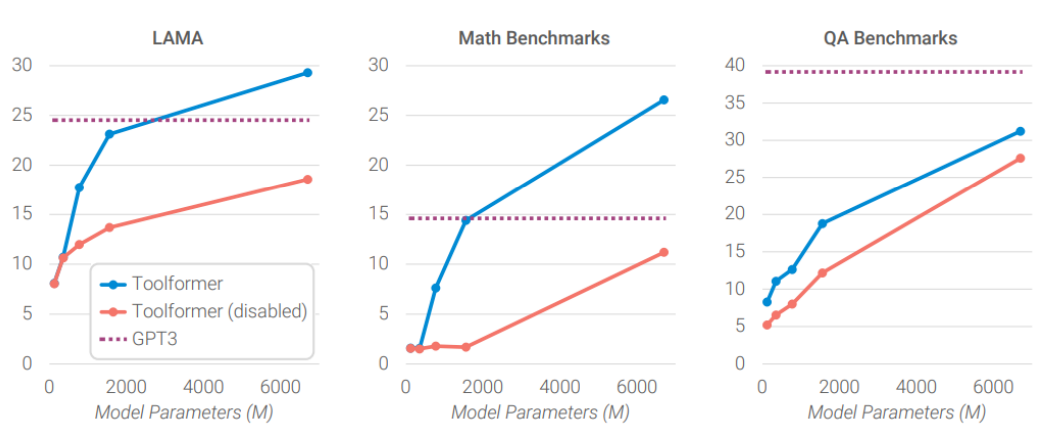
- 横轴:模型参数大小
- 纵轴:模型答案分数
- 蓝线:模型可以使用工具
- 红线:同样的训练内容,但禁止它使用工具(输出特定格式的内容后,不调用工具给它)