预训练阶段语言模型在网络上学了很多东西,却不知道使用方法
而在微调阶段会让语言模型接收人类老师的教导,发挥它的潜力
指令

- 要耗费大量人力产生一些特定资料(收集整理一些很好的问题和很好的答案)对模型进行训练
- 耗费大量人力产生特定资料叫做资料标注
- 通过这种资料标注训练模型的过程叫做督导式学习 (Supervised Learning)
为什么要标注出用户和 AI 呢?


所以 ChatGPT 不是以“你是谁”进行文字接龙的,而是“USER:你是谁 AI:”进行文字接龙
微调
第二阶段微调成功的关键是用第一阶段预训练的参数初始化
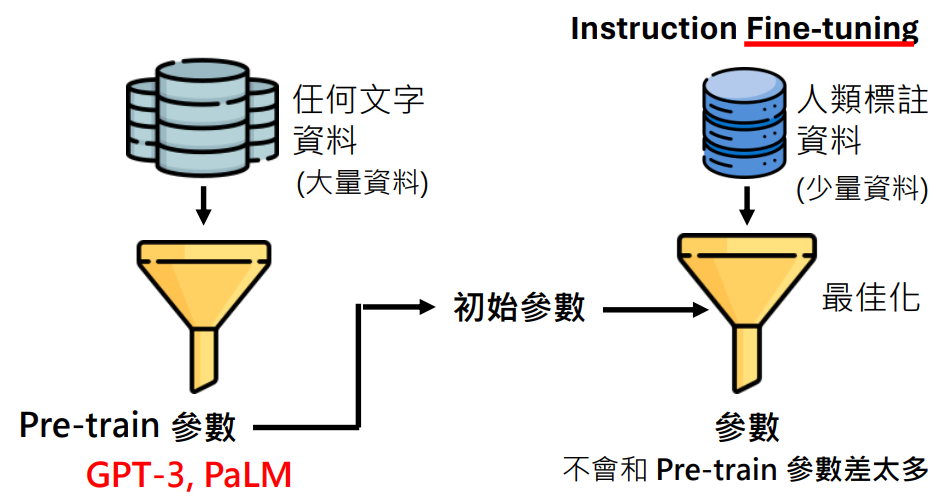
因为是用预训练的参数作为初始化参数,所以微调过程的最佳化产生的参数不会和预训练的参数差太多
为什么说微调成功的关键是用预训练的参数初始化?
- 预训练的资料量相当大,最佳化找出来的参数不会太差
不会仅凭简单的规则做文字接龙,如:看到“最”就答“玉山”这样的简单找出来的参数是通不过海量数据验证的
- 很强的举一反三能力
例如在多种语言上做预训练后,只要教某一个语言的某一个任务,模型自动学会其他语言的同样任务
Adapter
例如:LoRA
Adapter 是指微调最佳化过程中不改变预训练的参数,而是新加少量参数,微调最佳化的过程是找寻这些新加少量未知参数的值
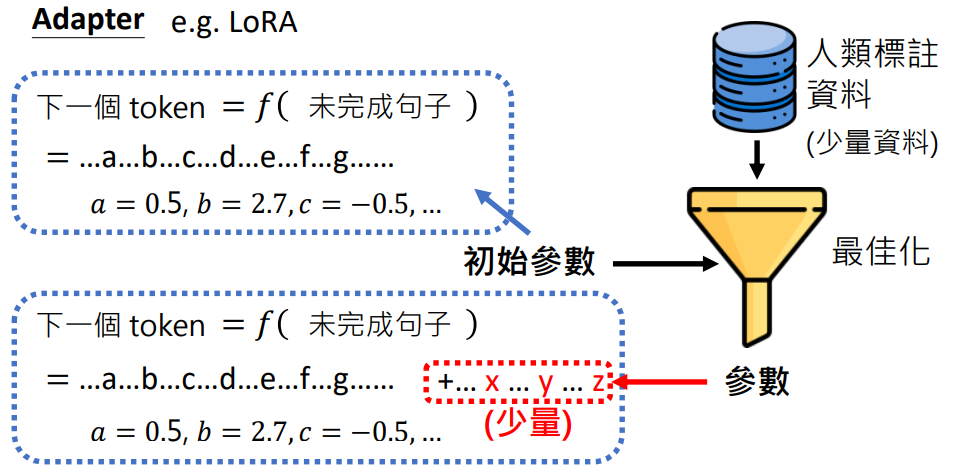
这样做的好处是:
- 不改变预训练的参数,避免微调导致模型改变太多(如变差、不稳定、不受控)
- 减少微调最佳化的运算量(只需要找少量的参数,而不是全部的参数)
各种 Adapter:随着插入新参数的位置不同、数量不同,有各种各样的 Adapter,LoRA 只是其中一种
微调的路线分成了两条
- 路线一:打造一堆专才模型
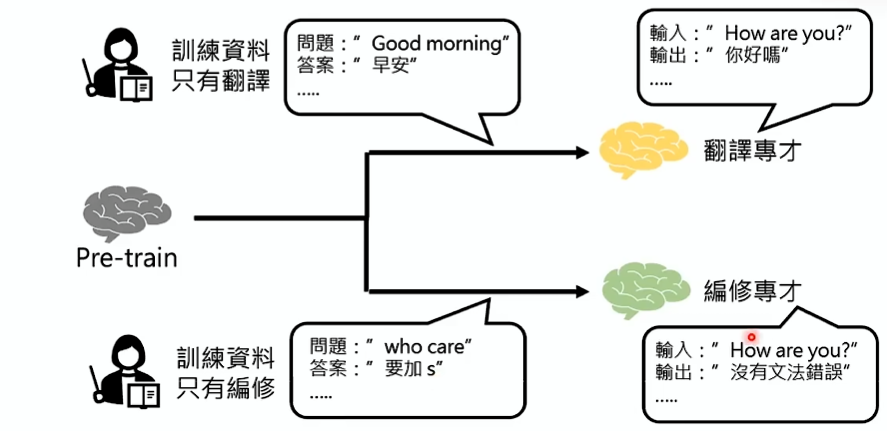
如:BERT 系列
- 路线二:直接打造一个通才
世界上有这么多任务,要把每一个任务微调一个模型吗?太麻烦了
直接打造一个通才,一劳永逸解决所有任务,让模型做什么任务,直接告诉它
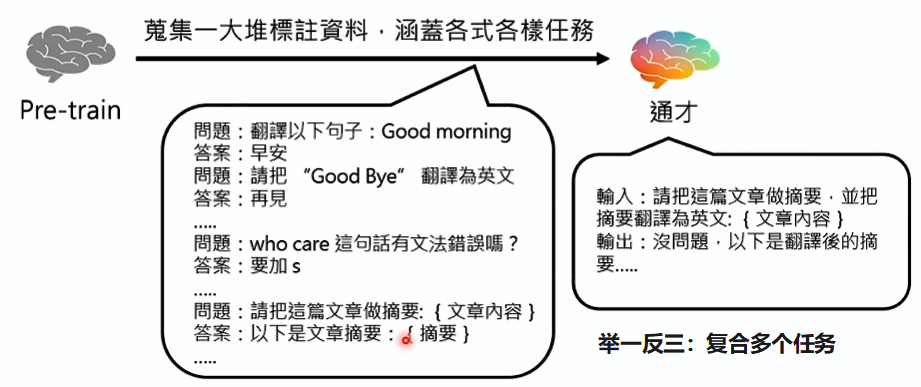
不一定一次使用很多类型的任务,也可以逐步微调,如先学习翻译、再学习编修
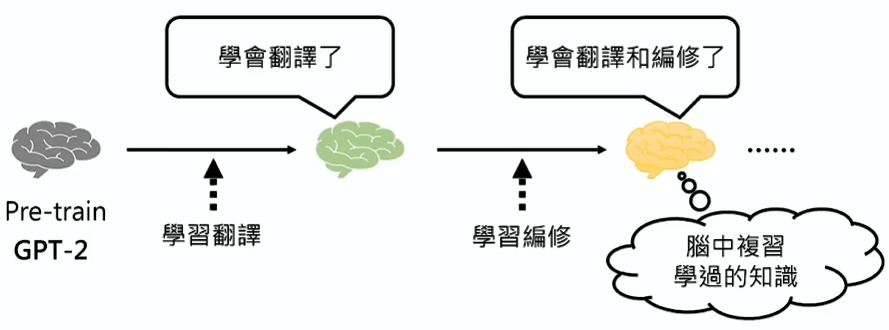
但是微调的资料标注多了,它会忘记之前的资料,就需要让模型进行复习,如何进行复习:
通才更发挥模型的举一反三能力:
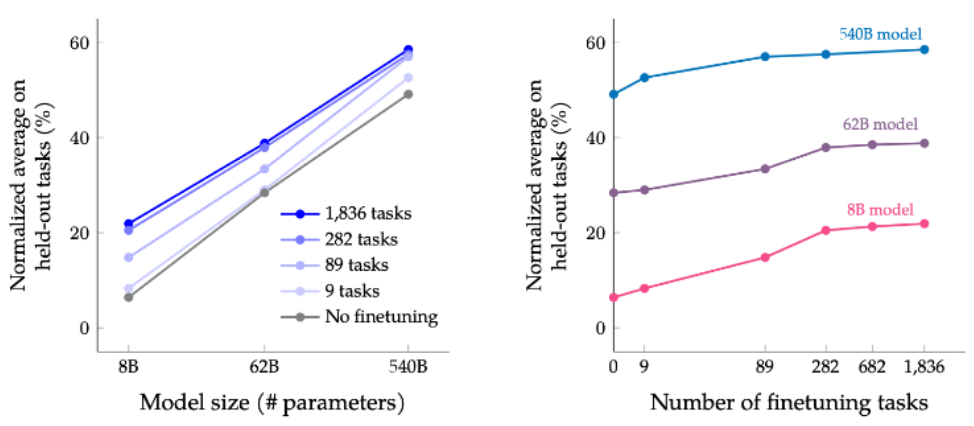
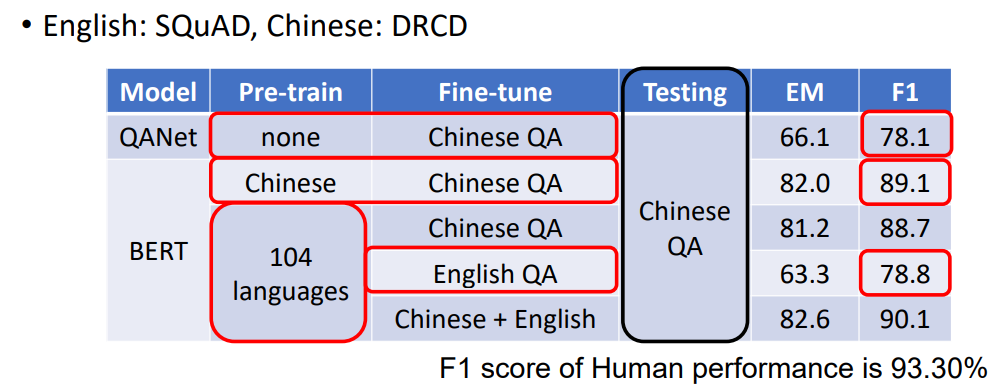
从上图可以看出:训练的任务越多,模型在没见过的任务上的表现越好
对于 PaLM 540B,指令微调只需要 0.2% 的预训练计算量
指令微调是画龙点睛
指令微调并不需要太多的资料量
- Instruct GPT(OpenAI GPT 系列)只使用了上万个资料
- LLaMA2 论文指出他们可以轻松获得数百万资料标注,但只用了两万多资料进行微调,因为根据效果发现数量不是太重要的,质量才是更重要的
- LIMA:Less Is More for Alignment,他们只用了一千个自己想的精选资料进行微调,就能在 43% 的情况下优于或等于 GPT-4 的效果
我自己也能做指令微调吗?
- 没有高品质的资料标注
OpenAI 有大量的线上使用者,所以知道用户会问什么问题
有人提出可以对 ChatGPT 做逆向工程,看看 ChatGPT 用了什么微调资料
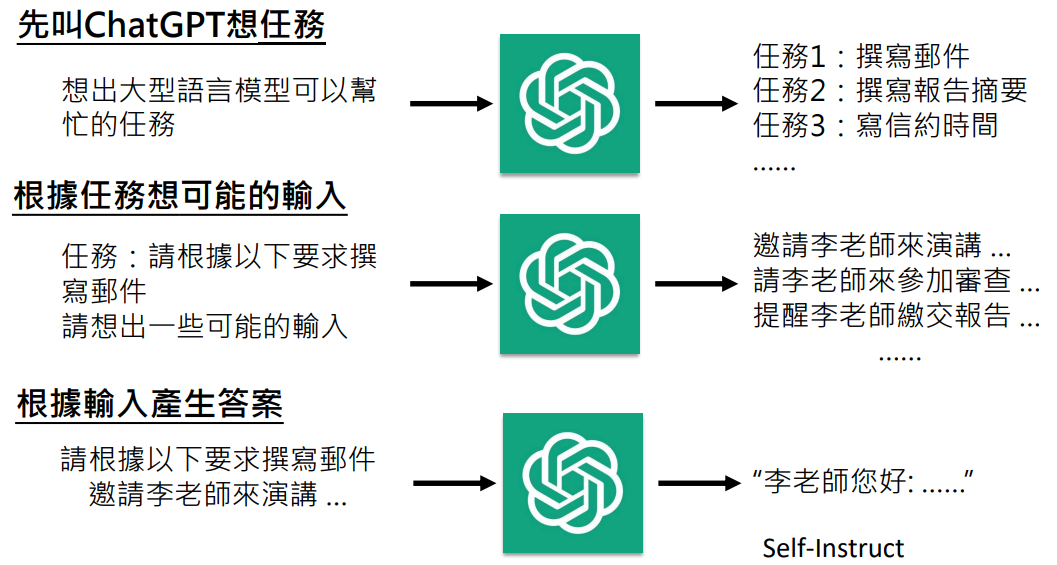
不过下面的文献指出通过这种方式获得的微调资料并没有很优质,不过有总比没有好
- 没有预训练完成的模型参数
Meta 开源了 LLaMA
两个问题解决后,现在人人都可以 fine-tune 大型语言模型的时代开始了!