过拟合与欠拟合
回归问题
用房子尺寸预测房价的例子:
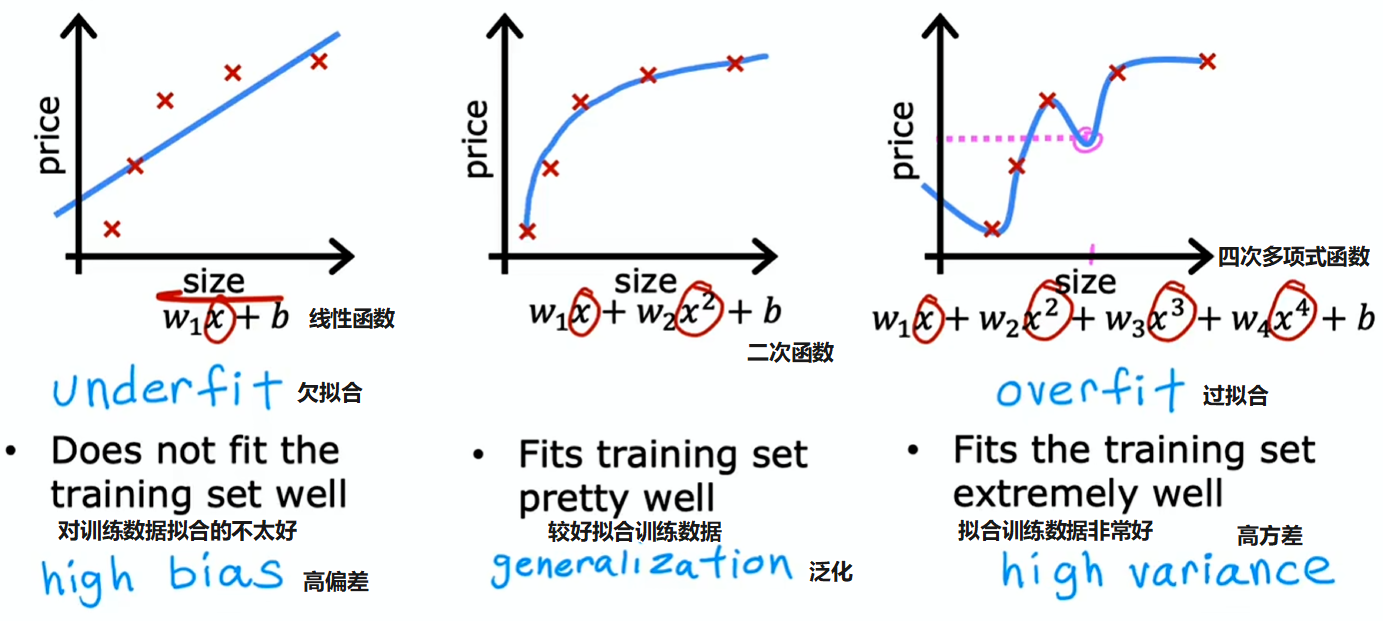
- 欠拟合(或叫高偏差):算法对训练数据拟合不足
- 恰好:在训练数据拟合较好,并且有很好的泛化能力,即使是针对训练集之外的示例,也能够预测的很好
- 过拟合(或叫高方差):完美拟合训练数据,但缺乏泛化能力,无法适用于它从未见过的新样本
- 直观原因是:算法会非常努力地去拟合每一个训练样本
- 结果是:要是训练集哪怕只有一点点差异,那么算法拟合出的函数最终可能会完全不同
- 所以要是两位不同的机器学习工程师用这个四阶多项式模型去拟合稍有不同的数据集,最终可能得出截然不同或变化极大的预测结果
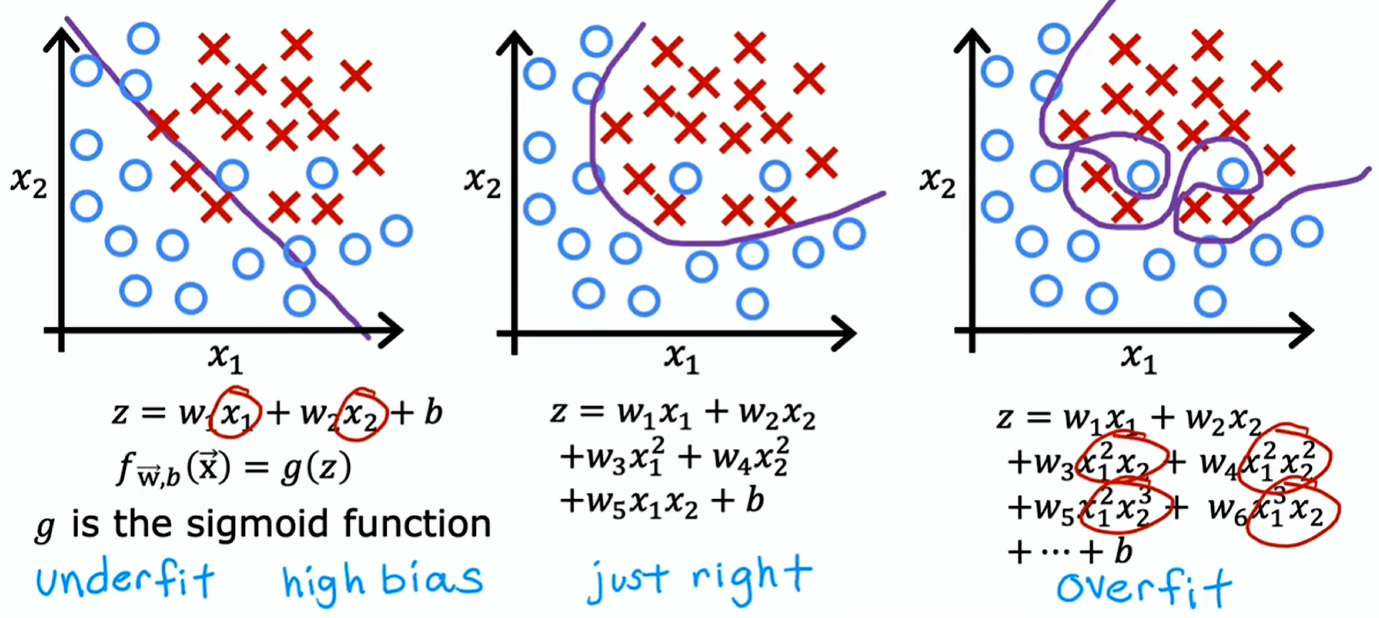
分类问题
用肿瘤大小和患者年龄预测是否恶性肿瘤的例子:
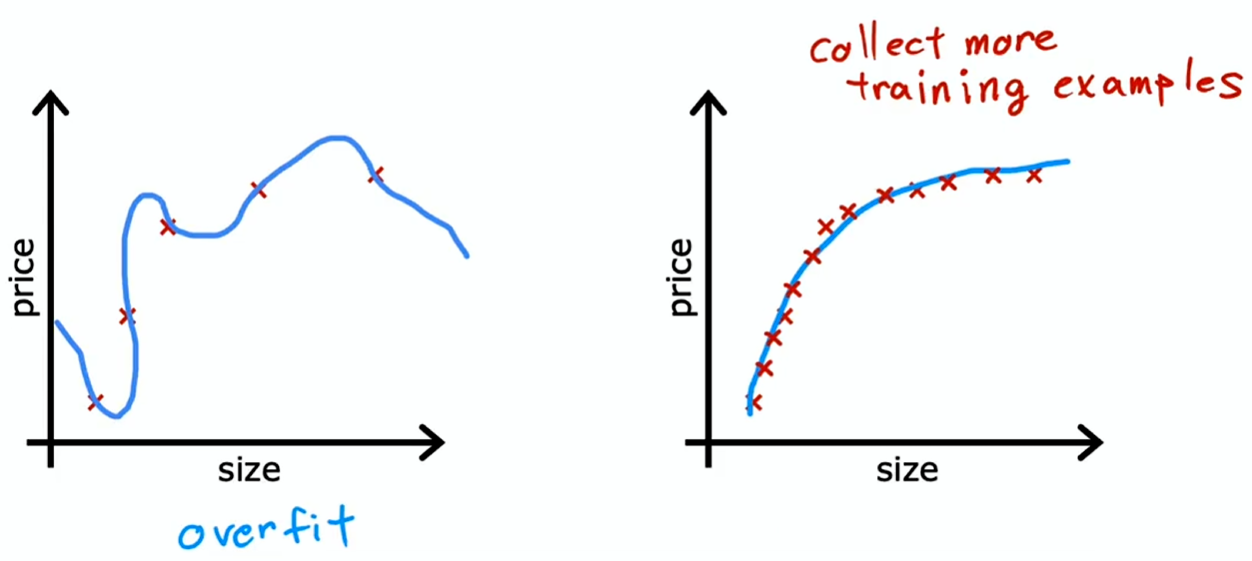
解决过拟合
收集更多训练数据
选择特征进行包含/排除
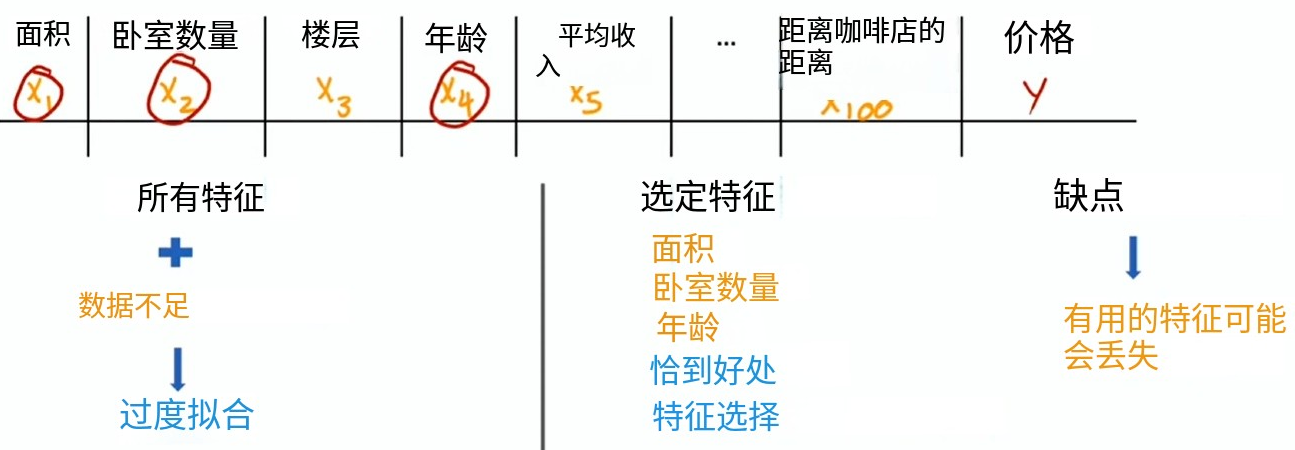
太多特征,但是训练数据不足,可能导致过拟合。解决方法是选定一些特征,而忽略其他特征(凭直觉)
正则化:减小参数大小
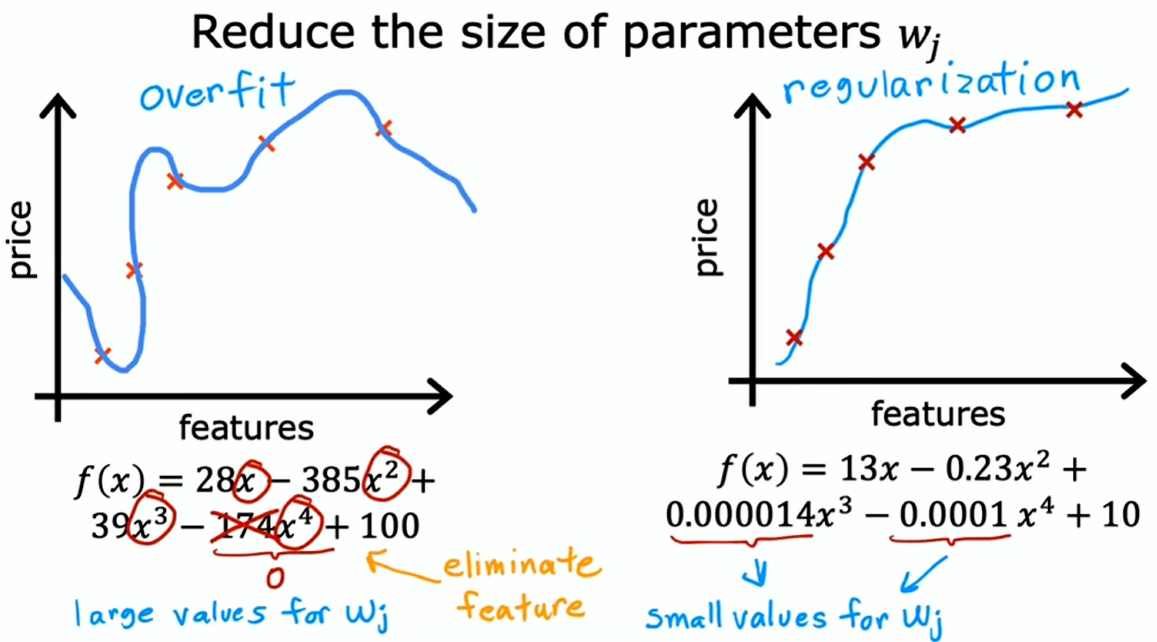
观察一个过拟合模型,会发现 参数往往较大,若要消除其中一些特征,将其参数设为零或接近零
即:正则化是一种更温和地降低某些特征影响的方法,而不是直接进行像完全消除那样严厉的操作
正则化的作用是鼓励学习算法缩小参数值,而不一定要求将参数设置为恰好为零。所以正则化能让你保留所有特征,但它能防止这些特征产生过大影响
按照惯例:通常只需减小 参数的大小,而对参数 进行正则化与否影响不大