高级优化算法
Adam 算法
梯度下降是一种广泛应用于机器学习的优化算法,并且是许多算法的基础,以及逻辑回归和早期神经网络的实现。但事实证明现在还有其他一些比梯度下降更优的、用于最小化成本函数的优化算法
梯度下降:
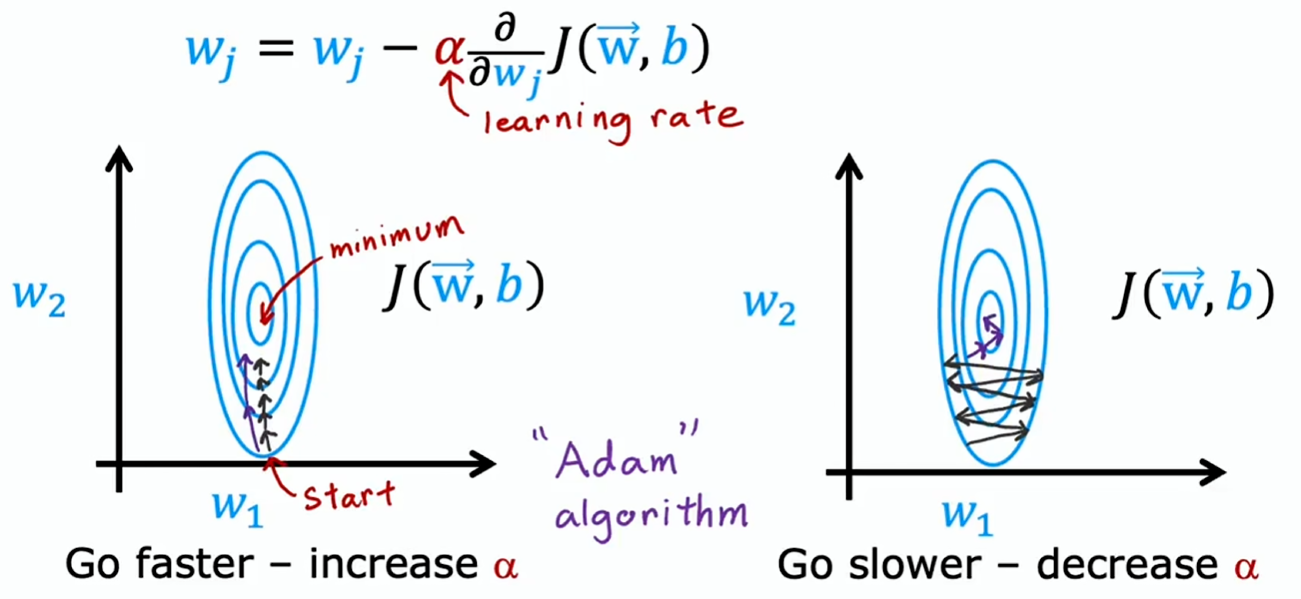
- 左图:学习率太小,而且只是在同一方向上反复迈着小步,就该调大学习率
- 右图:学习率太大,出现反复震荡的情况,就该调小学习率
Adam(Adaptive Moment estimation,自适应矩估计)算法能够自动调整学习率,而且并非采用单一的全局学习率 ,而是为模型的每个参数采用不同的学习率
Adam 算法背后的原理是:
- 如果参数 、 或 似乎一直在变动,而且大致朝同一方向,那就为该参数提高学习率,在那个方向上加快速度
- 相反,如果一个参数一直在来回振荡,那么稍微降低一下该参数的学习率
它通常比梯度下降快得多,而且成了从业者训练神经网络的实际标准
TensorFlow 实现

其他类型网络层
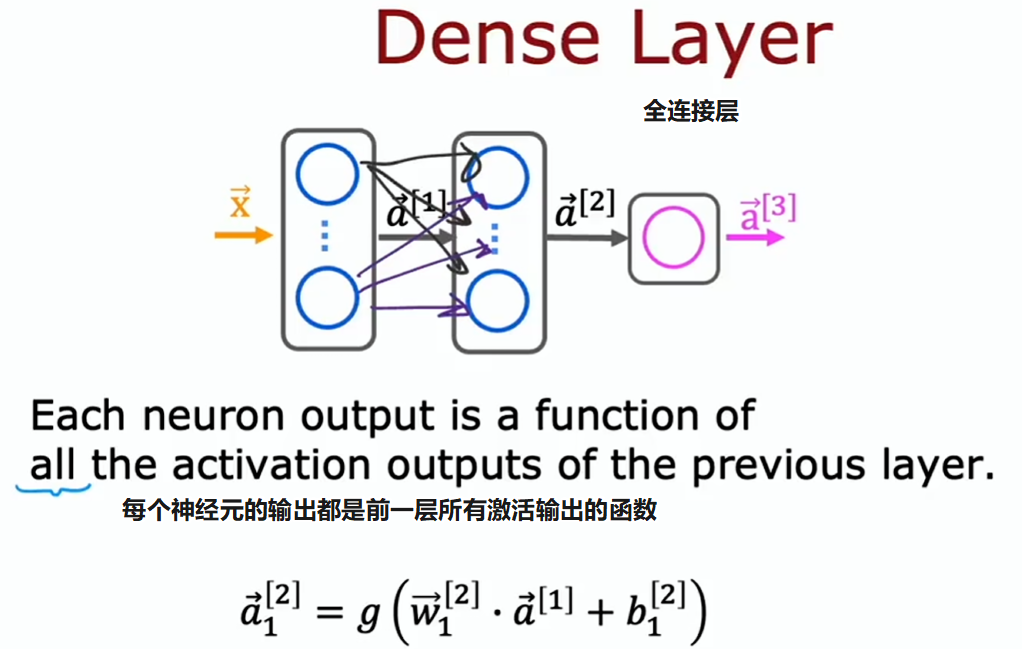
截至目前,我们用过的神经网络层都是密集层类型,层中的每个神经元都以前一层的所有激活值作为输入。事实证明,仅使用密集层类型,就能构建出一些相当强大的学习算法
为了帮你进一步直观了解神经网络的能力,其实还有一些具有其他属性的层
全连接层
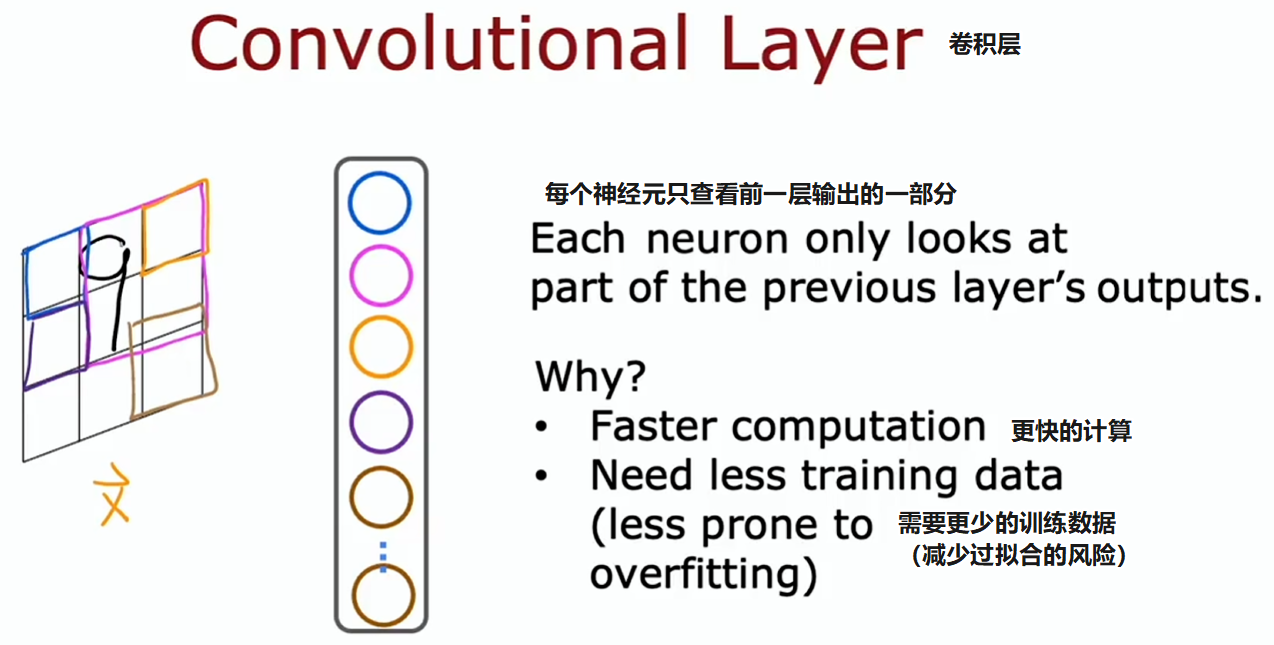
卷积层
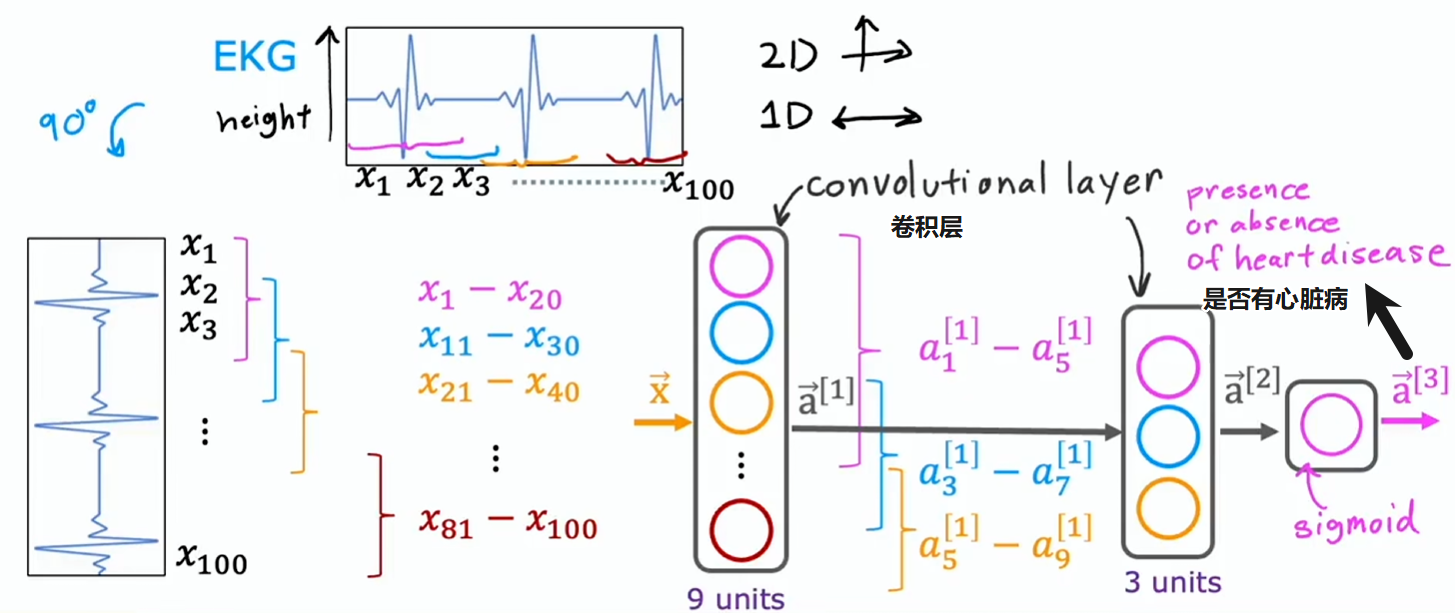
若神经网络中有多个卷积层,有时这就叫卷积神经网络,常用于图片相关处理
举个卷积神经网络的例子:通过心电图判断是否有心脏病