知识点
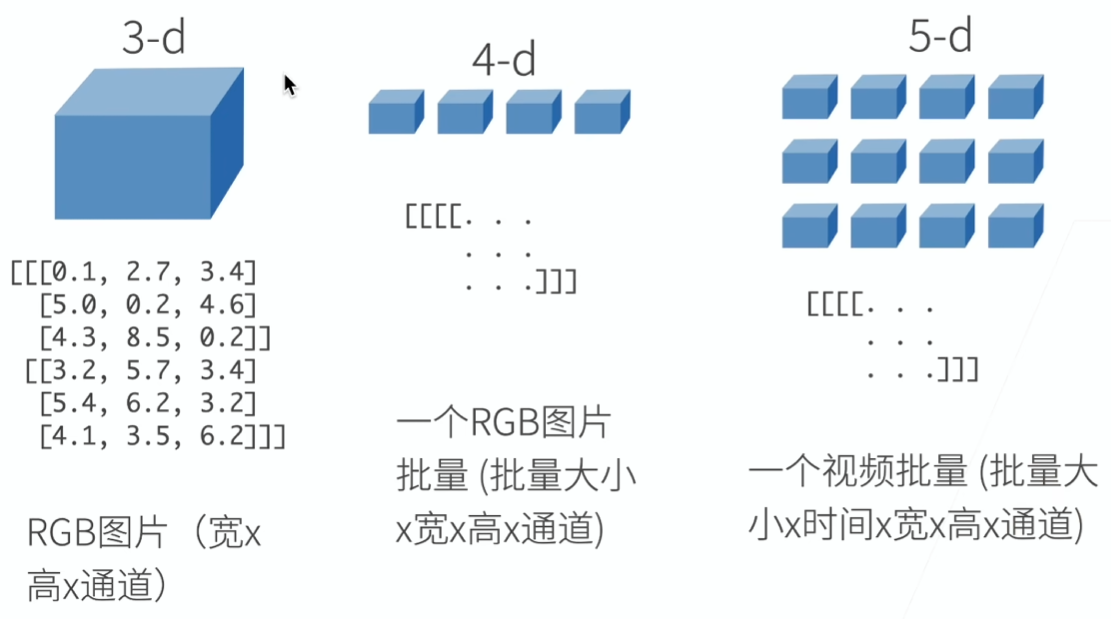
N 维数组样例
N 维数组是机器学习和神经网络的主要数据结构

创建数组
创建数组需要:
- 形状:例如 3x4 矩阵
- 每个元素的数据类型:例如 32 位浮点数
- 每个元素的值:例如全是 0,或者随机数
访问元素
代码
入门
首先,我们导入 torch。请注意,虽然它被称为 PyTorch,但是代码中使用 torch 而不是 pytorch
import torch张量表示一个由数值组成的数组,这个数组可能有多个维度
x = torch.arange(12)
x
'''
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
'''可以通过张量的 shape 属性来访问张量(沿每个轴的长度)的形状
x.shape
'''
torch.Size([12])
'''如果只想知道张量中元素的总数,即形状的所有元素乘积,可以检查它的大小(size)。因为这里在处理的是一个向量,所以它的 shape 与它的 size 相同
x.numel()
'''
12
'''要想改变一个张量的形状而不改变元素数量和元素值,可以调用 reshape 函数
X = x.reshape(3, 4)
X
'''
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
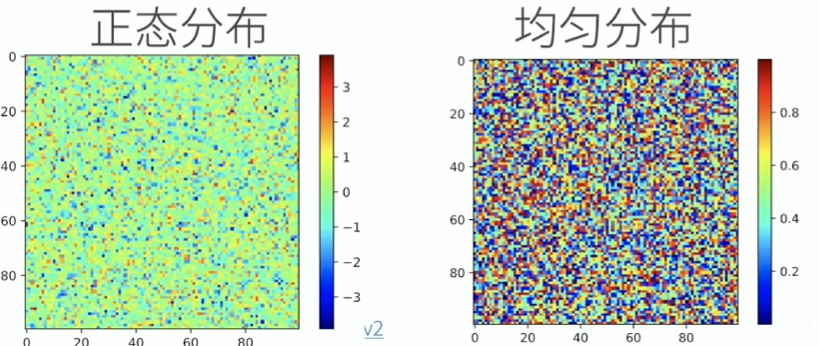
'''使用全 0、全 1、其他常量,或者从特定分布中随机采样的数字来初始化矩阵
torch.zeros((2, 3, 4))
'''
tensor([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
'''
torch.ones((2, 3, 4))
'''
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
'''通过从某个特定的概率分布中随机采样来得到张量中每个元素的值。其中的每个元素都从均值为0、标准差为1的标准高斯分布(正态分布)中随机采样
torch.randn(3, 4)
'''
tensor([[ 0.9933, -0.7864, -0.0141, -0.4889],
[ 2.0723, 0.7619, -1.2722, 1.1326],
[-1.1123, -0.2479, -0.4169, 1.7271]])
'''通过提供包含数值的 Python 列表(或嵌套列表),来为所需张量中的每个元素赋予确定值
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
'''
tensor([[2, 1, 4, 3],
[1, 2, 3, 4],
[4, 3, 2, 1]])
'''运算符
常见的标准算术运算符(+、-、*、/ 和 **)都可以被升级为按元素运算
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # ** 运算符是求幂运算
'''
(tensor([ 3., 4., 6., 10.]),
tensor([-1., 0., 2., 6.]),
tensor([ 2., 4., 8., 16.]),
tensor([0.5000, 1.0000, 2.0000, 4.0000]),
tensor([ 1., 4., 16., 64.]))
'''“按元素”方式可以应用更多的计算
torch.exp(x) # e^x
'''
tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])
'''我们也可以把多个张量连结(concatenate)在一起
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)
'''
(tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 2., 1., 4., 3.],
[ 1., 2., 3., 4.],
[ 4., 3., 2., 1.]]),
tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
[ 4., 5., 6., 7., 1., 2., 3., 4.],
[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
'''通过逻辑运算符构建二元张量
X == Y
'''
tensor([[False, True, False, True],
[False, False, False, False],
[False, False, False, False]])
'''对张量中的所有元素进行求和,会产生一个单元素张量
X.sum()
'''
tensor(66.)
'''广播机制
即使形状不同,我们仍然可以通过调用广播机制(broadcasting mechanism)来执行按元素操作
这种机制的工作方式如下:
- 通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状
- 对生成的数组执行按元素操作
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a, b
'''
(tensor([[0],
[1],
[2]]),
tensor([[0, 1]]))
'''由于 a 和 b 分别是 3x1 和 1x2 矩阵,如果让它们相加,它们的形状不匹配。我们将两个矩阵广播为一个更大的矩阵,如下所示:矩阵 a 将复制列,矩阵 b 将复制行,然后再按元素相加
前提:维度要一样,比如这里的 a 和 b 都是 2 维
a + b
'''
tensor([[0, 1],
[1, 2],
[2, 3]])
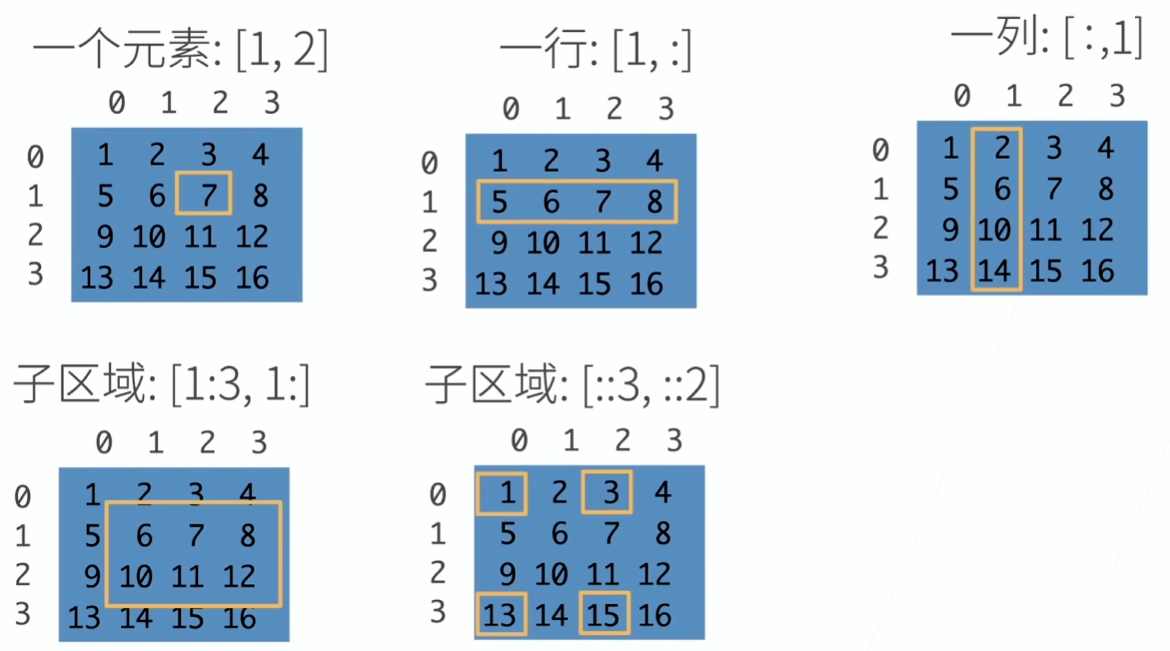
'''索引和切片
可以用 [-1] 选择最后一个元素,可以用 [1:3] 选择第二个和第三个元素
X[-1], X[1:3]
'''
(tensor([ 8., 9., 10., 11.]),
tensor([[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]]))
'''除读取外,我们还可以通过指定索引来将元素写入矩阵
X[1, 2] = 9
X
'''
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 9., 7.],
[ 8., 9., 10., 11.]])
'''为多个元素赋值相同的值,我们只需要索引所有元素,然后为它们赋值
X[0:2, :] = 12
X
'''
tensor([[12., 12., 12., 12.],
[12., 12., 12., 12.],
[ 8., 9., 10., 11.]])
'''节省内存
运行一些操作可能会导致为新结果分配内存
before = id(Y)
Y = Y + X
id(Y) == before
'''
False
'''执行原地操作
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))
'''
id(Z): 2764285093824
id(Z): 2764285093824
'''如果在后续计算中没有重复使用 X,我们也可以使用 X[:] = X + Y 或 X += Y 来减少操作的内存开销
before = id(X)
X += Y
id(X) == before
'''
True
'''转换为其他 Python 对象
转换为 NumPy 张量
A = X.numpy()
B = torch.tensor(A)
type(A), type(B)
'''
(numpy.ndarray, torch.Tensor)
'''将大小为 1 的张量转换为 Python 标量
a = torch.tensor([3.5])
a, a.item(), float(a), int(a)
'''
(tensor([3.5000]), 3.5, 3.5, 3)
'''