Optimizer 负责在训练过程中更新模型的参数,目的是通过调整参数来最小化损失函数,即模型预测和实际数据之间的差异
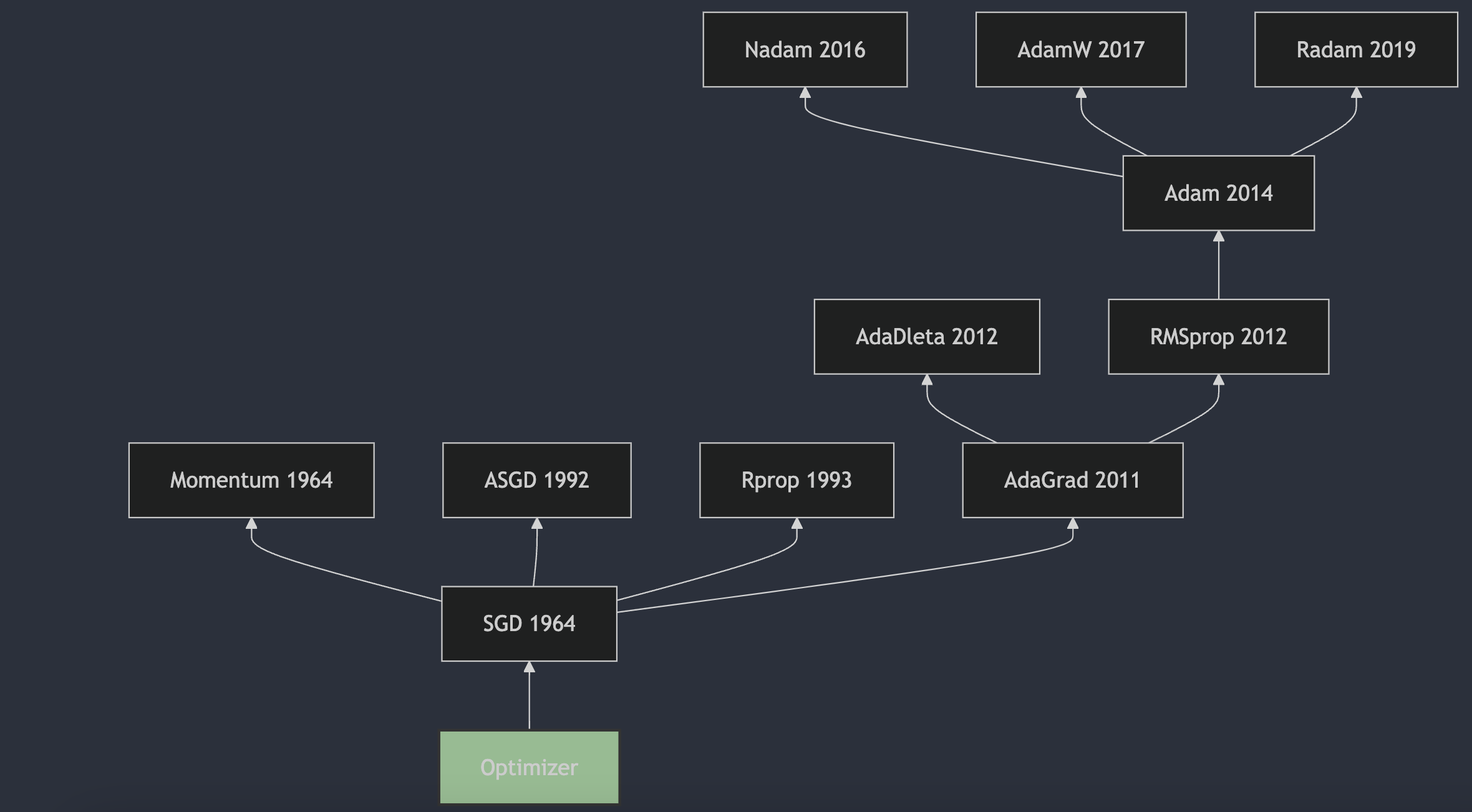
从 1951 年 Herbert Robbins 和 Sutton Monro 在其题为“随机近似方法”的文章中提出 SGD,到 2017 年出现的 AdamW 成为最主流的选择,优化器的发展经历了 70 多年的时间。本系列从时间的角度出发,对神经网络的优化器进行梳理,希望能够帮助大家更好地理解优化器的发展历程
发展历史:
Optimizer 负责在训练过程中更新模型的参数,目的是通过调整参数来最小化损失函数,即模型预测和实际数据之间的差异
从 1951 年 Herbert Robbins 和 Sutton Monro 在其题为“随机近似方法”的文章中提出 SGD,到 2017 年出现的 AdamW 成为最主流的选择,优化器的发展经历了 70 多年的时间。本系列从时间的角度出发,对神经网络的优化器进行梳理,希望能够帮助大家更好地理解优化器的发展历程
发展历史: