导入
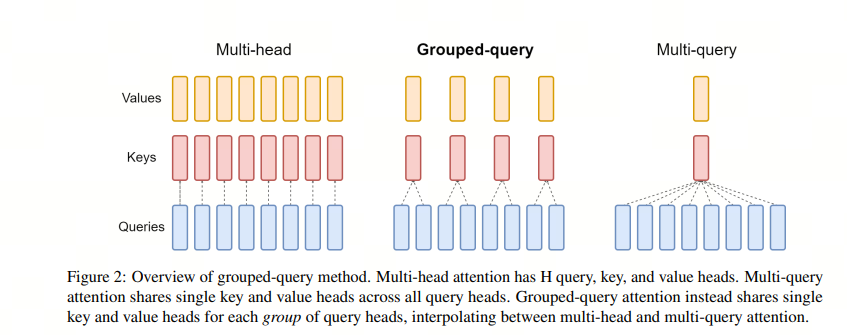
如果你看 GPT 系列的论文,你学习到的 self-attention 是 Multi-Head Attention(MHA),即多头注意力机制, MHA 包含 h 个 Query、Key 和 Value 矩阵,所有注意力头(head)的 Key 和 Value 矩阵权重不共享
这个机制已经能很好的捕捉信息了,为什么会继续发展出 MQA(Multi-Query-Attention)和 GQA(Group-Query-Attention)?
很多文章上来就是这三种 attention 机制的数学公式差别,但没有说为什么有了 MHA,还需要 MQA,甚至 GQA。本文简单阐述原因,给大家一个直觉式的理解
KV Cache
随着大模型的参数量越来越大,推理速度也受到了严峻的挑战。于是人们采用了 KV Cache,想用空间换时间
MQA
而增加了空间后,显存又是一个问题,于是人们尝试在 attention 机制里面共享 keys 和 values 来减少 KV cache 的内容
这就有了 Multi-Query Attention(MQA),即 query 的数量还是多个,而 keys 和 values 只有一个,所有的 query 共享一组。这样 KV Cache 就变小了
GQA
但 MQA 的缺点就是损失了精度,所以研究人员又想了一个折中方案:不是所有的 query 共享一组 KV,而是一个 group 的 guery 共享一组 KV,这样既降低了 KV cache,又能满足精度。这就有了 Group-Query Attention(GQA)