引言
如果你最近被 deepseek 刷屏了,你应该会去阅读它的技术报告,尤其是 v3 和 r1,这两篇技术报告默认读者对于当前的大模型训练技术很了解
所以对于初学者来讲,阅读这些技术报告会有痛苦和挑战,第一个挑战可能就是 MLA (Multi-Head Latent Attention),这是个来源于 deepseek v2 的技术
本文试图从头开始,为大家梳理从 MHA,MQA,GQA 到 MLA 一路发展的脉络以及背后的原因,并尽量将所需要的知识直接附上,免去递归查找之苦。为了初学者友好,本文的思路是线性的,如果你已经了解某一块的知识,可以直接跳到其它感兴趣的部分
通过本文,你会掌握 MLA 所需的前置知识包括:
- 多头注意力机制 MHA
- 什么是位置编码和 ROPE
- KV Cache,prefilling&decoding
- MHA 为什么需要继续发展出 MQA 和 GQA
并掌握 MLA 的技术核心:
- MLA 从 0-1 思路的猜测
- MLA 的技术要点
多头注意力机制 MHA
如果你看 GPT 系列的论文,你学习到的 self-attention 是 Multi-Head Attention(MHA),即多头注意力机制, MHA 包含 h 个 Query、Key 和 Value 矩阵,所有注意力头(head)的 Key 和 Value 矩阵权重不共享
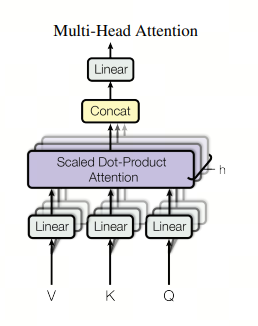
更细一点:
KV Cache:推理阶段的工程优化
KV Cache 是 GPT2 开始就存在的工程优化。它主要用于在生成阶段(decode)缓存之前计算的键值对,避免重复计算,从而节省计算资源和时间
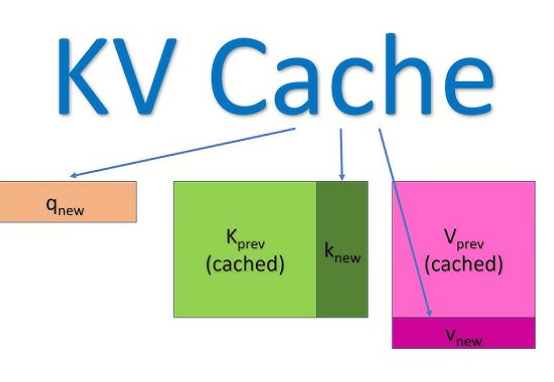
推理有两个阶段:prefill 和 decode
- Prefill 阶段处理整个输入序列,生成第一个输出 token,并初始化 KV 缓存
- Decode 阶段则逐个生成后续的 token,此时如果有 KV 缓存,每次只需处理新生成的 token,而无需重新计算之前所有 token 的键值
附录 1 是一个 KV Cache 的例子作为参考
MQA,GQA:多头注意力机制的降本增效
既然我们用空间换时间的方案,加快了推理速度,那占用显存空间又成了一个可以优化的点,有没有可能降低 KV Cache 的大小呢?
业界在 2019 年和 2023 年分别发明了 MQA(Multi Query Attention)和 GQA(Group Query Attention), 来降低 KV 缓存的大小
不可否认的是,这两者都会对大模型的能力产生影响,但两者都认为这部分的能力衰减可以通过进一步的训练或者增加 FFN/GLU 的规模来弥补
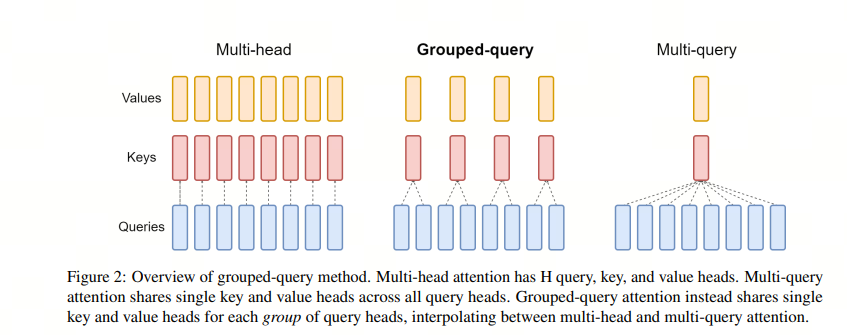
MQA 通过在 Attention 机制里面共享 keys 和 values 来减少 KV cache 的内容,query 的数量还是多个,而 keys 和 values 只有一个,所有的 query 共享一组 kv,这样 KV Cache 就变小了
GQA 不是所有的 query 共享一组 KV,而是一个 group 的 guery 共享一组 KV,这样既降低了 KV cache,又能满足精度,属于 MHA 和 MQA 之间的折中方案
MLA:山穷水尽疑无路,柳暗花明又一村
MHA,MQA,GQA 后下一个创新点在哪?
MQA 和 GQA 是在缓存多少数量 KV 的思路上进行优化:直觉是如果我缓存的 KV 个数少一些,显存就占用少一些,大模型能力的降低可以通过进一步的训练或者增加 FFN/GLU 的规模来弥补
如果想进一步降低 KV 缓存的占用,从数量上思考已经不行了,那就势必得从 KV 本身思考,有没有可能每个缓存的 KV 都比之前小?
我们知道,一个 的矩阵可以近似成两个 和 矩阵的乘积,那如果我把一个 K 或者 V 矩阵拆成两个小矩阵的乘积,缓存的时候显存占用不就变小了吗?
但这有一个问题,如果单纯的把一个大的 K/V 矩阵拆成 2 个小矩阵进行 cache,那在推理的时候,还是需要计算出完整的 K 矩阵,这样就失去了缓存的意义,毕竟缓存的意义就是减少计算!
有没有一种方法,即能减少缓存大小,又不增加推理时候的计算?
我们看看 deepseek v2 中是怎么解这个问题的
MLA 面临的问题与解法
在 v2 的论文中, 的表达从 变为 , 原来缓存的是 ,而现在缓存的是 的一部分 ,论文中把它定义成 ,这样就达到了降低 K 大小的目的
注意到 中 是 UP 的意思,指带将后面的矩阵维度升上去; 中 是 Down 的意思,指将维度降下去,而 指的是对 K,V 矩阵的采用相同的降维矩阵,这样只用缓存相同的
推理阶段计算量的增加
到目前为止,似乎是 so far so good,但是注意到在推理的时候,为了得到 和 ,还得将 或者 乘上去,失去了缓存的意义,怎么办?
有没有什么办法在推理的时候,降低这一步的计算量呢?如果在推理中,一定要还原出 或者 ,那就无解了,但好在 和 也只是中间变量,我们可以通过一定的变形巧妙的避免推理计算量
我们看 Attention 因子的计算:
其中 代表第 次输入/输出, 代表第 个 head
利用矩阵的结合率,我们可以在推理的时候,提前算好 ,这样在 decode 的时候,计算量基本没有增加,这被称为矩阵吸收(absorb)
同理, 也可以被吸收到 中,注意这边我们需要小心的通过转置等手段保证数学上的恒等
这样 deepseek v2 就能既要又要了
MLA 和 RoPE 位置编码不兼容
但是 MLA 又有一个新的问题,那就是和 Rope 位置编码的兼容性问题,为此他们还找过 Rope 的发明人苏剑林讨论过,这在苏 2024 年 5 月的博客里有提到,引用如下:

Deepseek 最终的解决方案是在 Q,K 上新加 d 个维度,单独用来存储位置向量,在推理的时候,缓存 和
完整的 MLA 算法
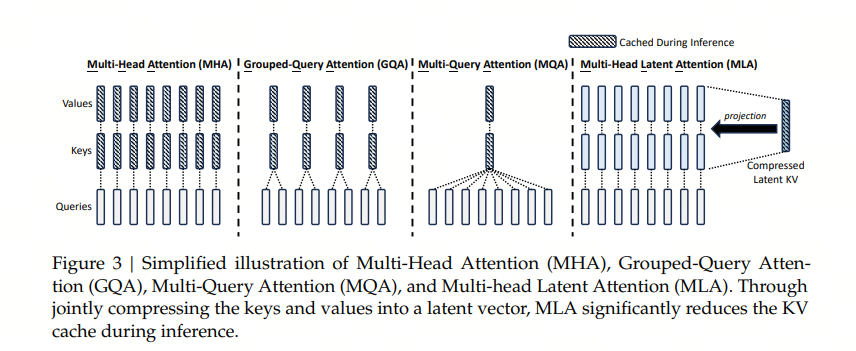
我们可以看下完整的包含了 RoPE 的位置编码 MLA 算法,标框的是缓存的内容
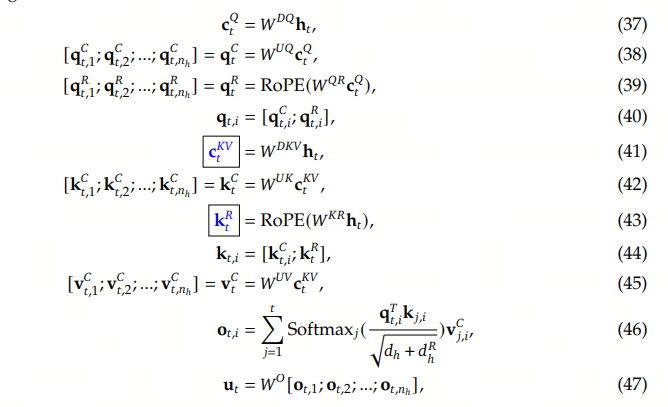
附录 1:KV Cache
在推理阶段,KV Cache 的存在与否对大模型的计算流程和效率有显著影响
以下以 prompt 为“真忒修斯之船是一个”,生成 completion “分享平台”为例,分别说明有无 KV Cache 的差异:
无 KV Cache 的推理过程
原理:每次生成新 token 时,需要将整个历史序列(prompt+已生成 tokens)重新输入模型,并重新计算所有 token 的 Key 和 Value 向量
示例流程:
- 输入完整 prompt“真忒修斯之船是一个”,计算所有 token 的 Key/Value,生成第一个 token“分”
- 计算量:需处理 9 个 token(假设“真忒修斯之船是一个”分词为 9 个 token)
- 输入“真忒修斯之船是一个分”,重新计算全部 10 个 token 的 Key/Value,生成“享”
- 冗余计算:前 9 个 token 的 Key/Value 被重复计算
- 输入“真忒修斯之船是一个分享”,重新计算 11 个 token 的 Key/Value,生成“平”
- 输入“真忒修斯之船是一个分享平”,重新计算 12 个 token 的 Key/Value,生成“台”
问题:
- 计算冗余:每生成一个 token 需重新计算所有历史 token 的 Key/Value,复杂度为 显存和计算时间随序列长度急剧增长
- 显存占用高:显存需存储完整历史序列的中间结果,例如生成“台”时需缓存 10 个 token 的 Key/Value
有 KV Cache 的推理过程
原理:在 prefill 阶段计算 prompt 的 Key/Value 并缓存,后续 decode 阶段仅需计算新 token 的 Key/Value,复用缓存的旧结果
示例流程:
- Prefill 阶段:输入完整 prompt“真忒修斯之船是一个”,计算其 9 个 token 的 Key/Value 并缓存,生成第一个 token“分”
- Decode 阶段:
- 输入新 token“分”,仅计算其 Key/Value,与缓存的 9 个 Key/Value 合并,生成“享”
- 输入新 token“享”,计算其 Key/Value,与缓存的 10 个 Key/Value 合并,生成“平”
- 输入新 token“平”,计算其 Key/Value,与缓存的 11 个 Key/Value 合并,生成“台”
优势:
- 计算量降低:复杂度从 降至 每个 decode 步骤仅需计算新 token 的 Key/Value
- 显存优化:仅需存储缓存的 Key/Value,显存占用公式为 但通过复用缓存避免了冗余存储
- 速度提升:实验显示,KV Cache 可使吞吐量提升数十倍
核心对比
| 维度 | 无 KV Cache | 有 KV Cache |
|---|---|---|
| 计算复杂度 | 随序列长度平方增长 | 仅需计算新 token |
| 显存占用 | 存储完整序列中间结果,显存需求高 | 缓存 Key/Value,显存需求可控 |
| 生成速度 | 慢(重复计算历史 token) | 快(仅计算新 token,复用缓存) |
| 适用场景 | 短序列生成(<100 tokens) | 长序列生成(如 API 输入、视频生成) |