什么是位置编码
位置编码(Positional Encoding)是一种在处理序列数据时,用于向模型提供序列中每个元素位置信息的技术
在自然语言处理(NLP)中,尤其是在使用 Transformer 模型时,位置编码尤为重要,因为 Transformer 模型本身并不包含处理序列顺序的机制
位置编码的主要目的是让模型能够区分输入序列中词的顺序,从而更好地理解句子的结构和含义
好的位置编码
- 为每个位置输出唯一的编码
- 不同长度的句子之间,任何两个位置之间的差值应该保持一致
- 编码值应该是有界的
- 具备远程衰减的特性
位置编码的远程衰减性是指随着序列中元素之间相对位置的增加,位置编码对模型性能的影响逐渐减弱的特性。这种特性在理论上对于 Transformer 模型是有益的,因为它可以模拟人类在处理长文本时注意力逐渐分散的现象
位置编码的种类
位置编码通常分为两种类型:绝对位置编码和相对位置编码
绝对位置编码
这是最常见的一种位置编码方法,其核心思想是在每个输入序列的元素上添加一个位置向量,以表示该元素在序列中的具体位置。这个位置向量通常通过正弦和余弦函数生成,具有周期性,能够捕捉序列中的相对位置信息
相对位置编码
这种编码方式侧重于考虑元素之间的距离信息。在自注意力机制中,通过加入位置偏置项,使模型能够感知到元素间的相对位置关系。常见的相对位置编码方法包括 Sinusoidal Positional Encoding 和 Learned Positional Encoding,前者通过不同频率的正弦和余弦函数来计算位置编码,后者则是通过学习得到的参数来计算位置编码
绝对位置编码的实现
绝对位置编码的实现通常采用正弦和余弦函数的组合,这种编码方式最早由 Vaswani 等人在《Attention is All You Need》中提出,被广泛应用于 Transformer 模型中
绝对位置编码的实现通常涉及以下步骤:
生成位置向量
为序列中的每个位置生成一个位置向量。这个向量通常具有与模型的词嵌入维度相同的大小
使用正弦和余弦函数
绝对位置编码的计算公式如下:对于每个位置 pos 和每个维度索引 i,计算正弦和余弦函数的值:
其中:
- 表示位置编码(Positional Encoding)
- 是词在序列中的位置
- 是模型的维度大小
添加到词嵌入
将计算得到的位置向量添加到相应的词嵌入向量中。这样,每个词的嵌入不仅包含了语义信息,还包含了位置信息
训练模型
在训练过程中,模型将学习如何利用这些位置编码来更好地理解序列数据
绝对位置编码的设计允许模型捕捉序列中的相对位置信息,这对于理解语言结构和执行如机器翻译、文本摘要等任务至关重要。通过这种方式,Transformer 模型能够区分相同词在不同位置的不同含义,从而提高模型的性能和准确性
绝对位置编码 FAQ
为什么是三角函数?
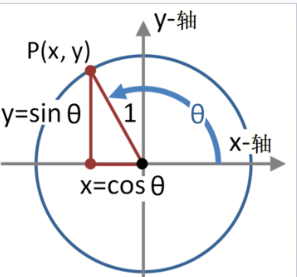
正弦和余弦函数是周期性函数,可以捕捉序列中元素之间的相对位置信息。这种函数的周期性特征使得模型能够更好地理解序列中元素的位置关系,从而提高模型的性能和准确性
为什么要除以 10000?
除以 10000 是为了缩放位置编码的值,使其在不同位置之间具有一定的差异性。这样,模型可以更好地区分不同位置的元素,通过调整 10000 这个缩放因子,可以控制模型对不同位置之间距离的敏感性
- 较小的缩放因子会使得位置编码对距离更敏感
- 而较大的缩放因子则使得模型对更广泛的位置范围敏感
为什么要使用正弦和余弦函数交替?
正弦和余弦函数交替使用是为了使位置编码具有不同的周期性特征。这样,模型可以更好地捕捉序列中元素之间的相对位置信息,从而提高模型的性能和准确性
相对位置编码
相对位置编码不是为序列中的每个位置分配一个固定的位置向量,而是在计算注意力权重时考虑了元素之间的相对位置关系
相对位置编码的关键特点包括:
- 相对位置敏感性:编码方式允许模型在计算注意力分数时,不仅考虑元素之间的相互作用,还考虑它们之间的相对位置
- 动态计算:相对位置编码通常是动态计算的,这意味着它们会根据输入序列中元素的实际相对位置来生成编码
- 注意力机制的扩展:在自注意力机制中,通常会向计算的注意力分数中添加一个与相对位置相关的偏置项,这个偏置项可以是基于相对位置的函数
- 多种实现方式:相对位置编码有多种实现方式,例如使用预先定义的相对位置矩阵、通过可训练的参数学习相对位置编码,或者使用其他复杂的函数来捕捉元素之间的相对距离
- 提高模型性能:通过考虑元素之间的相对位置,相对位置编码可以帮助模型更好地捕捉序列数据中的模式和依赖关系,从而提高模型在某些任务上的性能
- 适用于长序列:相对位置编码特别适合处理长序列,因为它允许模型在不考虑序列绝对位置的情况下,通过相对位置关系来理解序列结构
外推性
位置编码的外推性是指模型在处理推理阶段比训练阶段更长的序列时,如何有效地扩展其位置编码以保持性能
在大模型中,由于显存资源的限制,通常在预训练时设计的最大序列长度有限,例如 4k 左右,但推理时可能需要处理更长的序列,如 32K 的文本。因此,设计合适的位置编码对于提升模型在更长序列上的外推性至关重要