本系列是对 Hugging Face 官方文档的翻译,原文链接
引言
为了训练最大的 Llama 3 模型,Meta 结合了三种并行化方式:数据并行化、模型并行化和管道并行化。当同时在 16K GPU 上进行训练时,他们最高效的实现实现了每 GPU 超过 400 TFLOPS 的计算利用率。他们在两个定制的 24K GPU 集群上进行了训练运行。为了最大限度地延长 GPU 的正常运行时间,他们开发了一种新的训练堆栈,可以自动检测、处理和维护错误。他们还大大改进了硬件可靠性和无声数据损坏检测机制,并开发了新的可扩展存储系统,减少了检查点和回滚的开销。这些改进使总体有效训练时间缩短了 95% 以上,与 Llama 2 相比,将 Llama 3 的训练效率提高了约三倍
这边,Meta 使用了三种并行化方式:数据并行化、模型并行化和管道并行化。这三种并行化方式是大模型分布式训练的核心技术,在这个系列我将对这几种并行化方式进行详细介绍
本系列旨在用最简单的方式介绍大模型分布式训练并行技术,不涉及太多细节和实现方式,只介绍最基本的概念
并行化策略
- 数据并行 DataParallel (DP) - 相同的设置被复制多次,每次都输入一部分数据。处理是并行进行的,所有设置在每个训练步骤结束时同步
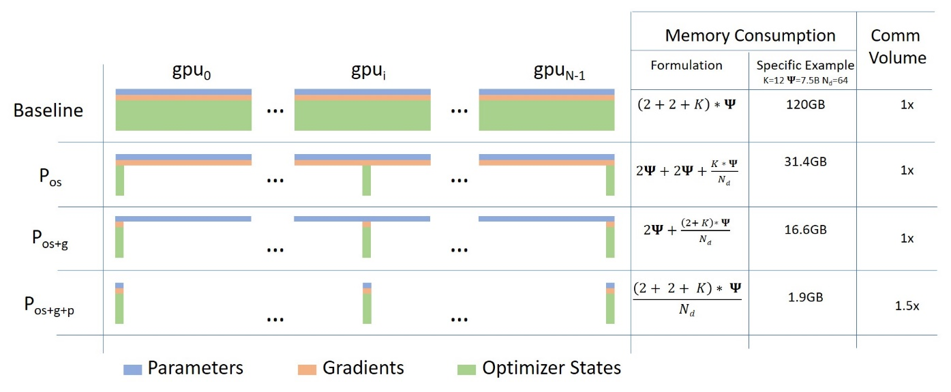
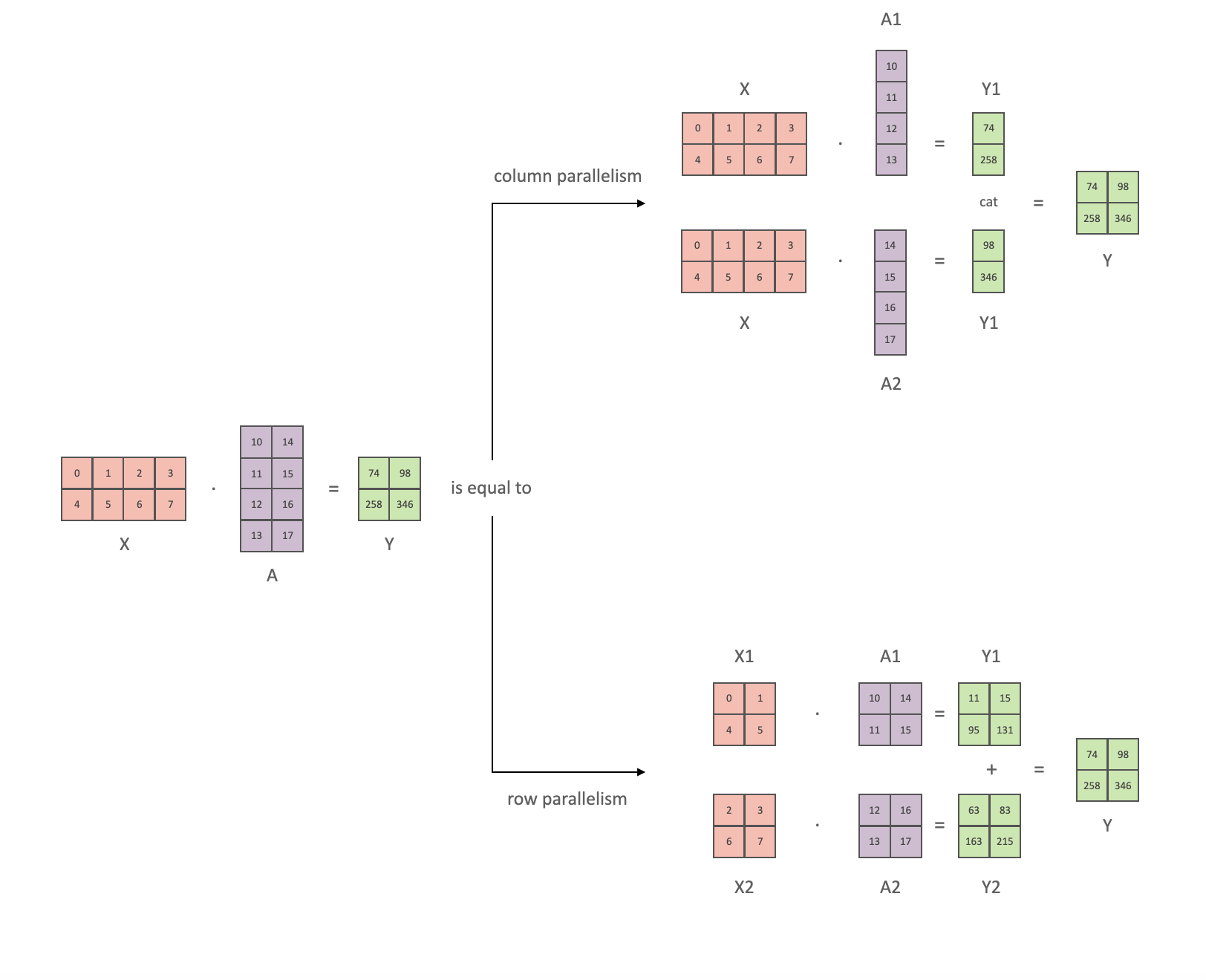
- 张量并行 TensorParallel (TP) - 每个张量被分成多个块,因此不是将整个张量驻留在单个 GPU 上,而是将张量的每个分片驻留在其指定的 GPU 上。在处理过程中,每个分片在不同的 GPU 上单独并行处理,结果在步骤结束时同步。这就是所谓的水平并行,因为拆分发生在水平层面
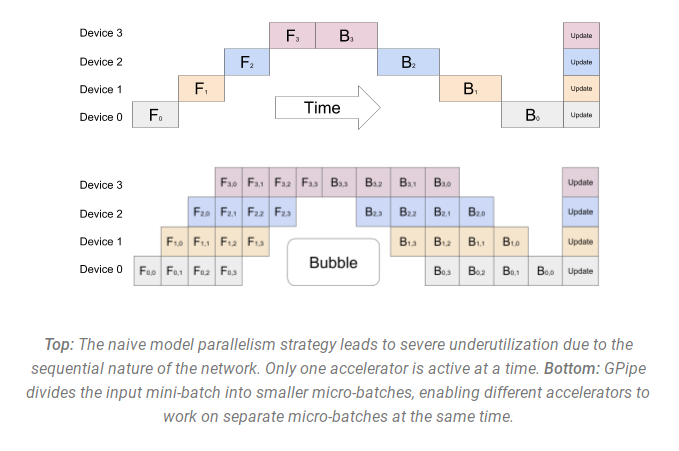
- 管道并行、流水线并行 PipelineParallel (PP) - 模型在多个 GPU 上垂直(层级)拆分,因此只有一层或几层模型放在单个 GPU 上,每个 GPU 并行处理管道的不同阶段并处理一小部分批次
- 混合并行 MixedParallel (MP) - 混合并行是将数据并行、模型并行和管道并行结合在一起的一种方法。这种方法可以在多个 GPU 上同时进行数据并行和模型并行,同时在每个 GPU 上进行管道并行
如何选择策略?
以下是何时使用并行策略的粗略概述,每个列表中的第一个通常更快
单 GPU
- 模型适合单个 GPU:
- 正常使用
- 模型不适合单个 GPU:
- ZeRO + offload CPU 和可选的 NVMe
- 如上所述,如果最大层无法放入单个 GPU,则使用以内存为中心的平铺(详情见下文)
- 最大层不适合单个 GPU:
- ZeRO - 启用以内存为中心的平铺 Memory Centric Tiling (MCT)。它允许通过自动拆分并按顺序执行来运行任意大的层。MCT 减少了 GPU 上活动的参数数量,但不会影响激活内存。由于这种需求在撰写本文时非常罕见,因此用户需要手动覆盖
torch.nn.Linear
- ZeRO - 启用以内存为中心的平铺 Memory Centric Tiling (MCT)。它允许通过自动拆分并按顺序执行来运行任意大的层。MCT 减少了 GPU 上活动的参数数量,但不会影响激活内存。由于这种需求在撰写本文时非常罕见,因此用户需要手动覆盖
单节点多GPU
- 模型适合单个 GPU:
- DDP - Distributed DP
- ZeRO - 可能更快,也可能不快,具体取决于所用的情况和配置
- 模型不适合单个 GPU:
- PP
- ZeRO
- TP
- 有了 NVLINK 或 NVSwitch 的非常快速的节点内连接,这三者应该基本相当,如果没有这些,PP 将比 TP 或 ZeRO 更快
- TP 的程度也可能有所不同,最好进行实验以找到特定设置中的赢家
- 最大层不适合单个 GPU:
- 如果不使用 ZeRO - 必须使用 TP,因为单独使用 PP 无法满足需求
- 对于 ZeRO,请参见上面的“单 GPU”条目
TP 几乎总是在单个节点内使用。即 TP 大小 ⇐ 每个节点的 GPU
多节点多 GPU
- 当你拥有快速的节点间连接时:
- ZeRO - 因为它几乎不需要对模型进行任何修改
- PP+TP+DP - 通信较少,但需要对模型进行大量更改
- 当你拥有缓慢的节点间连接且 GPU 内存仍然不足时:
- DP+PP+TP+ZeRO-1