FlashAttention V2 在减少计算量和内存访问的同时,保持了算法的精度和效率,实现了更快的 Attention 计算。这些优化使得 V2 版本在 A100 GPU 上前向传播的速度提升了大约 2 倍,达到了理论计算峰值的 50%-73%
FlashAttention V1
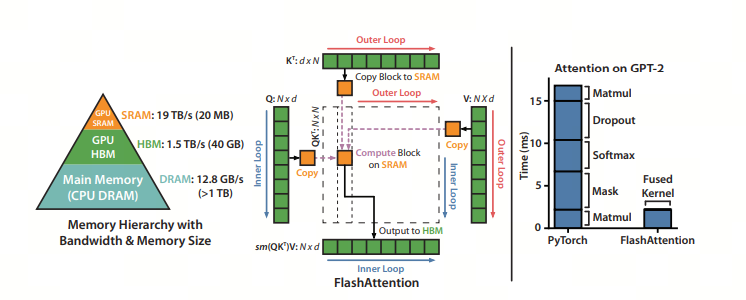
FlashAttention 不需要在全局内存上实现 和 矩阵,而是将上述公式中的整个计算融合到单个 CUDA 内核中。这要求我们设计一种算法来仔细管理片上内存(on-chip memory,如流算法),因为 NVIDIA GPU 的共享内存(SRAM)很小
对于矩阵乘法等经典算法,使用平铺(tiling)来确保片上内存不超过硬件限制。这种平铺方法是有效的原因是:加法是关联的,允许将整个矩阵乘法分解为许多平铺矩阵乘法的总和,详见
FlashAttention V2 的更新
- 减少了 non-matmul FLOPs 的数量(消除了原先频繁 rescale)。虽然 non-matmul FLOPs 仅占总 FLOPs 的一小部分,但它们的执行时间较长,这是因为 GPU 有专用的矩阵乘法计算单元,其吞吐量高达非矩阵乘法吞吐量的 16 倍。因此,减少 non-matmul FLOPs 并尽可能多地执行 matmul FLOPs 非常重要
- 提出了在序列长度维度上并行化。该方法在输入序列很长(此时 batch size 通常很小)的情况下增加了 GPU 利用率。即使对于单个 head,也在不同的 thread block 之间进行并行计算
- 在一个 attention 计算块内,将工作分配在一个 thread block 的不同 warp 上,以减少通信和共享内存读/写
第一个更新详解
减少了 non-matmul FLOPs 的数量(消除了原先频繁 rescale)。虽然 non-matmul FLOPs 仅占总 FLOPs 的一小部分,但它们的执行时间较长,这是因为 GPU 有专用的矩阵乘法计算单元,其吞吐量高达非矩阵乘法吞吐量的 16 倍。因此,减少 non-matmul FLOPs 并尽可能多地执行 matmul FLOPs 非常重要
non-matmul vs. GEMM
non matrix multiply
非矩阵乘法:指的是在矩阵乘法之外的操作,如加法、乘法、除法等, 例如 rescale 操作,使用的是 GPU 的通用硬件:CUDA Core
General Matrix Multiply
通用矩阵乘法:指的是矩阵乘法的一种实现方式,使用的是 GPU 的专用硬件:Tensor Core
CUDA Core vs. Tensor Core
非矩阵乘法操作的执行时间较长,因为 GPU 有专用的矩阵乘法计算单元 Tensor Core,其吞吐量高达非矩阵乘法吞吐量的 16 倍
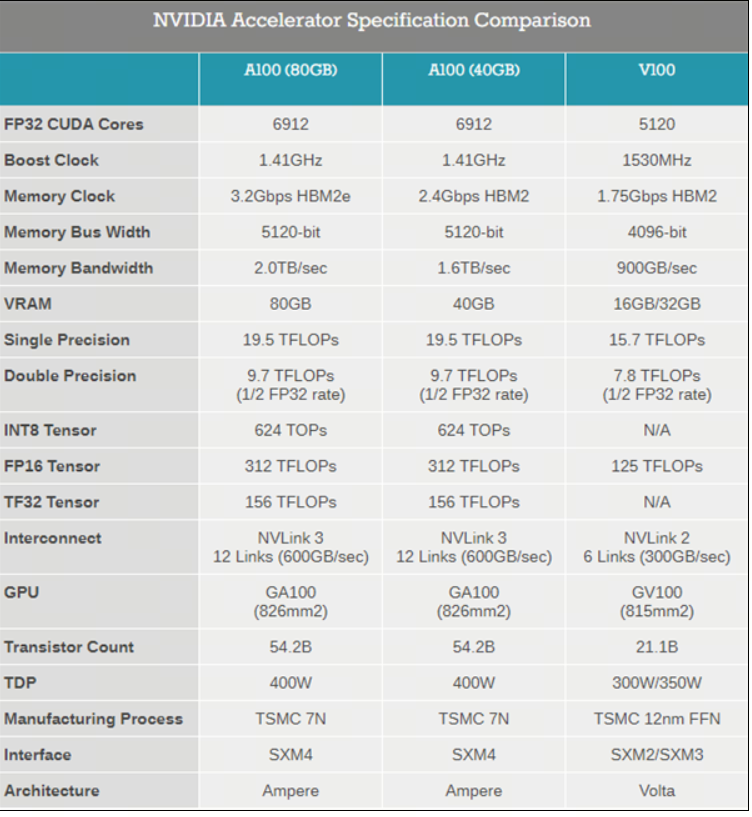
下图是 A100 的介绍,可以看到 CUDA Core 单精度 TF16 的计算能力是 19.5TFLOPS,而 Tensor Core 的计算能力是 312TFLOPS,相差 16 倍之多
Rescale 操作
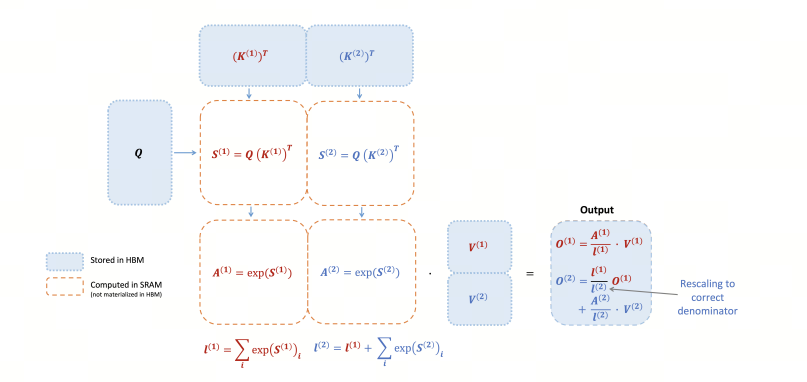
V2 版本调整了算法,减少了非矩阵乘法操作的浮点运算次数,同时保持输出不变。在原始的 FlashAttention(即 V1 版本)中,每个 block 的每次迭代都需要执行 rescale 操作,这涉及到除法运算
而在 V2 中,这种 rescale 操作被延后到循环的最后才执行一次,每次计算可以减少一次除法运算。这样的调整是因为只要每次迭代确保分子部分被 scale 为正确值以及分母部分计算正确即可。这种优化减少了计算量,提高了效率
第二个更新详解
提出了在序列长度维度上并行化。该方法在输入序列很长(此时 batch size 通常很小)的情况下增加了 GPU 利用率。即使对于单个 head,也在不同的 thread block 之间进行并行计算
GPU 硬件
- Streaming Processor(SP):是最基本的处理单元,从 fermi 架构开始被叫做 CUDA core
- Streaming MultiProcessor(SM):一个 SM 由多个 CUDA core(SP)组成,每个 SM 在不同 GPU 架构上有不同数量的 CUDA core,例如 Pascal 架构中一个 SM 有 128 个 CUDA core
GPU 软件
- thread:一个 CUDA 并行程序由多个 thread 来执行,thread 是最基本的执行单元(the basic unit of execution)
- warp:一个 warp 通常包含 32 个 thread。每个 warp 中的 thread 可以同时执行相同的指令,从而实现 SIMT(单指令多线程)并行。warp 是 SM 中最小的调度单位(the smallest scheduling unit on an SM),一个 SM 可以同时处理多个 warp
- thread block:一个 thread block 可以包含多个 warp,同一个 block 中的 thread 可以同步,也可以通过 shared memory 进行通信。thread block 是 GPU 执行的最小单位(the smallest unit of execution on the GPU)。一个 warp 中的 threads 必然在同一个 block 中,如果 block 所含 thread 数量不是 warp 大小的整数倍,那么多出的那个 warp 中会剩余一些 inactive 的 thread。也就是说,即使 warp 的 thread 数量不足,硬件也会为 warp 凑足 thread,只不过这些 thread 是 inactive 状态,但也会消耗 SM 资源
V2 相对于 V1 的第二个主要更新是增加了序列长度维度的并行计算,这样做的目的是提高 GPU 的 SM(Streaming Multiprocessor)利用率,尤其是在处理长序列数据时。在 V1 中,计算是先按批次和头数并行执行,然后在序列长度上串行执行。这意味着当序列长度较长时,可能无法充分利用所有可用的 SM,因为每个 block 只能处理序列的一个片段
在 V2 中,通过在序列长度维度上进行并行化,可以更有效地分配计算任务到更多的 block,从而更充分地利用 GPU 资源。具体来说,V2 通过增加 num_m_block 的概念,将 Q 矩阵在序列长度方向上进一步划分为多个小块,每一块由不同的 block 来处理。这样,每个 block 可以独立地计算它所负责的输出部分,减少了不同 block 之间的依赖和通信开销
有点像 continous batching 的思路
第三个更新详解
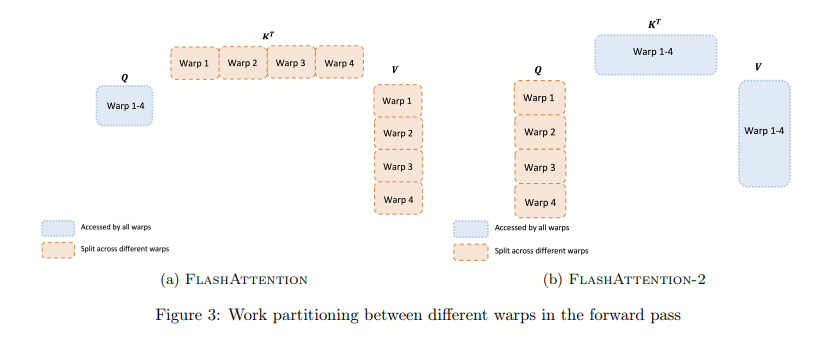
在 V2 中,通过调整循环顺序,将 Q 作为外循环,K 和 V 作为内循环,每个线程块(thread block)负责计算输出矩阵 O 的一部分。这种设计允许每个线程块独立进行计算,减少了线程块之间的依赖和通信需求。同时,V2 版本在前向传播中进一步减少了非矩阵乘法操作的浮点运算,以充分利用 GPU 上的专用计算单元,如 Nvidia GPU 上的 Tensor Cores,从而最大化 GPU 的吞吐量
此外,V2 版本在反向传播中也进行了优化,采用了类似的分块策略来优化计算和内存访问,提高效率和性能。通过这种方式,FlashAttention V2 能够实现更高的并行性,减少不必要的计算和内存访问,从而提升整体的计算性能