引言
你可能在很多地方听过 3D 并行技术,我们之前讨论的数据并行,流水线并行,张量并行都是属于 1D 并行技术
在某些分类中,流水线并行和张量并行都被划归为模型并行技术
混合并行技术是指同时使用多种并行技术,比如数据并行和模型并行,或者数据并行和流水线并行,或者数据并行和张量并行
DP+PP
数据并行和流水线并行的结合,是一种非常常见的 2D 混合并行技术
下图是来自 DeepSpeed 流水线并行教程,演示了如何将 DP 与 PP 结合起来
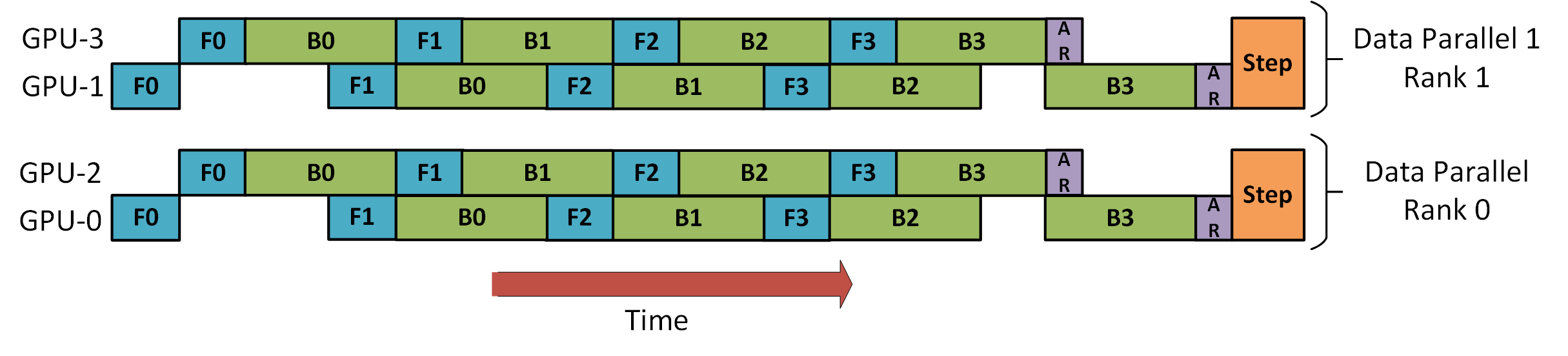
这里重要的是要看到 DP Rank 0 看不到 GPU2,而 DP Rank 1 看不到 GPU3。对于 DP 来说,只有 GPU 0 和 1,它向其中提供数据,就好像只有 2 个 GPU 一样。GPU0 使用 PP“秘密”将部分负载 offload 到 GPU2。而 GPU1 也通过 GPU3 来做同样的事情
由于每个维度至少需要 2 个 GPU,因此这里至少需要 4 个 GPU
DP+PP+TP
为了实现更高效的训练,就出现了 3D 并行,将 PP 与 TP 和 DP 相结合。如下图所示:
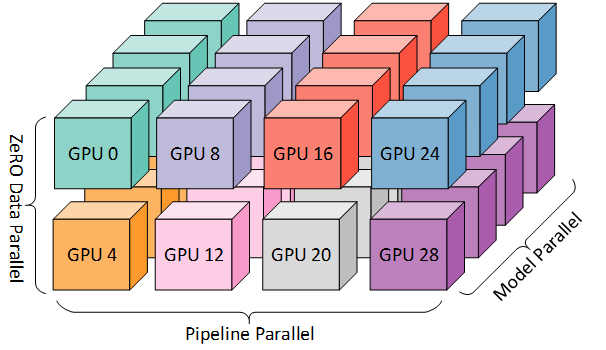
该图来自博客 3D parallelism: Scaling to trillion-parameter models
由于每个维度至少需要 2 个 GPU,因此这里至少需要 8 个 GPU
DP+PP+TP+ZeRO
也就是常说的 4D 并行,ZeRO 是一个由 DeepSpeed 提出的技术,可以将模型的参数划分为多个部分,每个部分在不同的设备上进行计算,最后将结果进行汇总。本质上是 ZeRO-DP 与 PP(和可选的 TP)结合
注意:当 ZeRO-DP 与 PP(和可选的 TP)结合时,它通常只启用 ZeRO 第 1 阶段(优化器分片)
虽然理论上可以将 ZeRO 第 2 阶段(梯度分片)与 PP 结合使用,但这会对性能产生不利影响
每个微批次都需要一个额外的 Reduce-Scatter 集合来在分片之前聚合梯度,这可能会增加大量的通信开销。根据 PP 的性质,会使用较小的微批次 Macro-Batch,而重点是尝试平衡算术强度(微批次大小)和最小化流水线气泡(微批次数量)。因此,这些通信成本将受到影响
此外,由于 PP,层数已经比正常情况少,因此内存节省不会很大。PP 已经将梯度大小减少至 1/PP,因此在此基础上的梯度分片节省不如纯 DP 显著
出于同样的原因,ZeRO 第 3 阶段也不是一个好的选择——需要更多的节点间通信
由于我们有 ZeRO,另一个好处是 ZeRO-Offload。由于这是第 1 阶段,因此优化器状态可以卸载到 CPU
FlexFlow
FlexFlow 也以略有不同的方法解决了并行化问题
论文:Beyond Data and Model Parallelism for Deep Neural Networks
它对样本-操作-属性-参数执行某种 4D 并行:
- 样本 = 数据并行(样本并行)
- 操作 = 将单个操作并行化为多个子操作
- 属性 = 数据并行(长度并行)
- 参数 = 模型并行(无论维度如何 - 水平或垂直)
举例:
- 样本
我们取 10 个序列长度为 512 的批次。如果我们按样本维度将它们并行化到 2 个设备中,我们将得到 10 x 512,即 5 x 2 x 512
- 操作
如果我们执行 layer normalization,我们首先计算 std 标准差,然后计算 mean 平均值,然后我们可以规范化数据。运算符并行性允许并行计算 std 和 mean。因此,如果我们按运算符维度将它们并行到 2 个设备(cuda:0、cuda:1),首先我们将输入数据复制到两个设备中,然后 cuda:0 计算 std,cuda:1 同时计算mean
- 属性
我们有 10 个长度为 512 的批次。如果我们按属性维度将它们并行化到 2 个设备中,则 10 x 512 将等于 10 x 2 x 256
- 参数
它与张量模型并行或 navie 分层模型并行类似
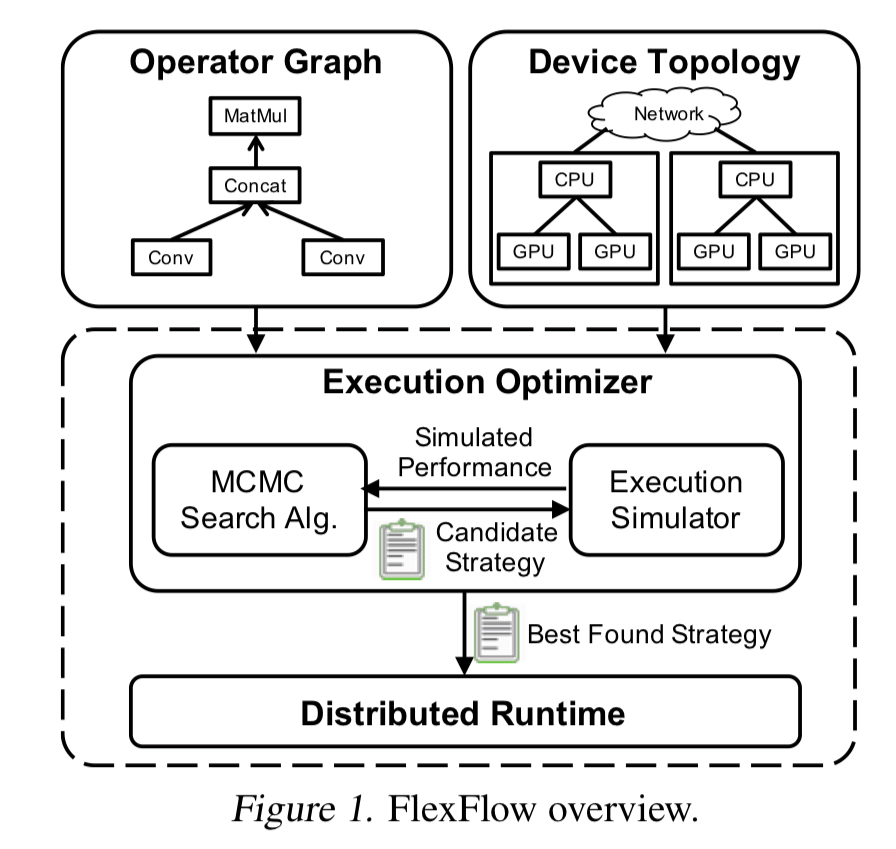
这个框架的重要性在于它占用的资源包括(1)GPU/TPU/CPU 与(2)RAM/DRAM 与(3)快速内部连接/慢速互连,并且它会自动优化所有这些资源,从而通过算法决定在哪里使用哪种并行化
一个非常重要的方面是,FlexFlow 旨在针对具有静态和固定工作负载的模型优化 DNN 并行化,因为具有动态行为的模型可能更喜欢在迭代过程中使用不同的并行化策略
因此,这个承诺非常有吸引力 —— 它在所选集群上运行 30 分钟的模拟,并提出利用此特定环境的最佳策略。如果你添加/删除/替换任何部件,它将运行并重新优化该计划。然后你就可以训练了。不同的设置将有自己的自定义优化