Text Generation Inference(TGI)是一个由 Hugging Face 开发的用于部署和提供大型语言模型(LLMs)的框架。它是一个生产级别的工具包,专门设计用于在本地机器上以服务的形式运行大型语言模型。TGI 使用 Rust 和 Python 编写,提供了一个端点来调用模型,使得文本生成任务更加高效和灵活
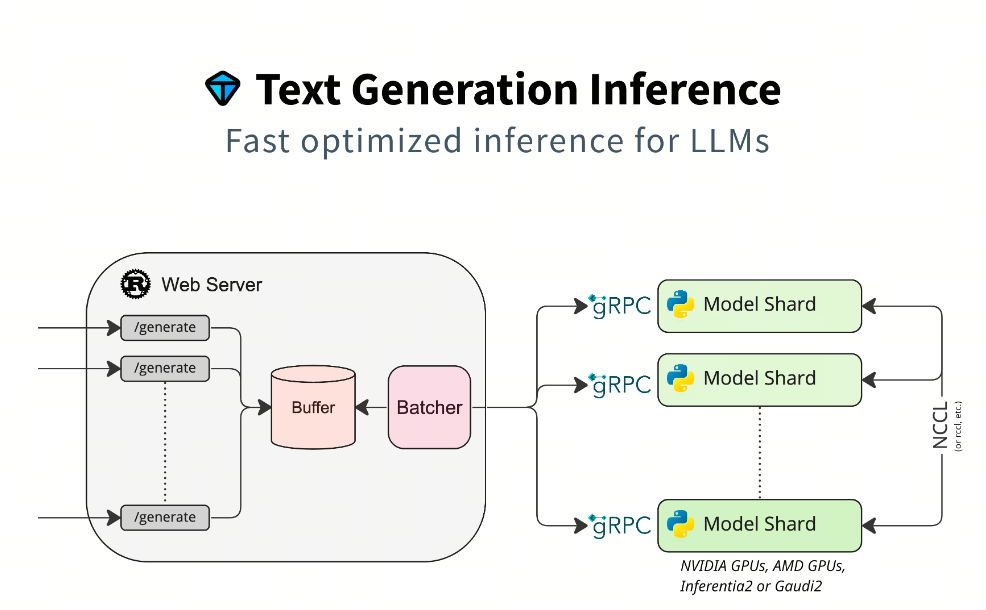
加速推理技术
- Tensor Parallelism
张量并行使用了矩阵乘法可以并行计算的特性,将模型的参数划分为多个部分,每个部分在不同的设备上进行计算,最后将结果进行汇总。下面,我们分别看 FFN 和 Self-Attention 的张量并行实现
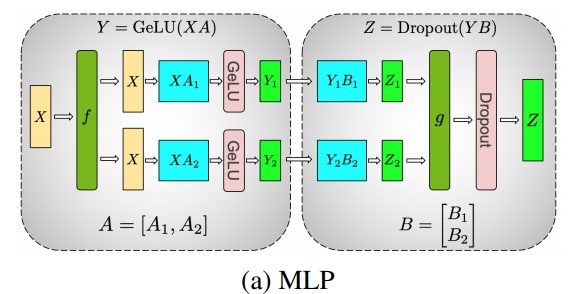
MLP 的主要构建块都是完全连接的 nn.Linear,后跟非线性激活 GeLU
按照 Megatron 的论文符号,我们可以将其点积部分写为 ,其中 和 是输入和输出向量, 是权重矩阵
如果我们以矩阵形式查看计算,很容易看出矩阵乘法如何在多个 GPU 之间拆分:
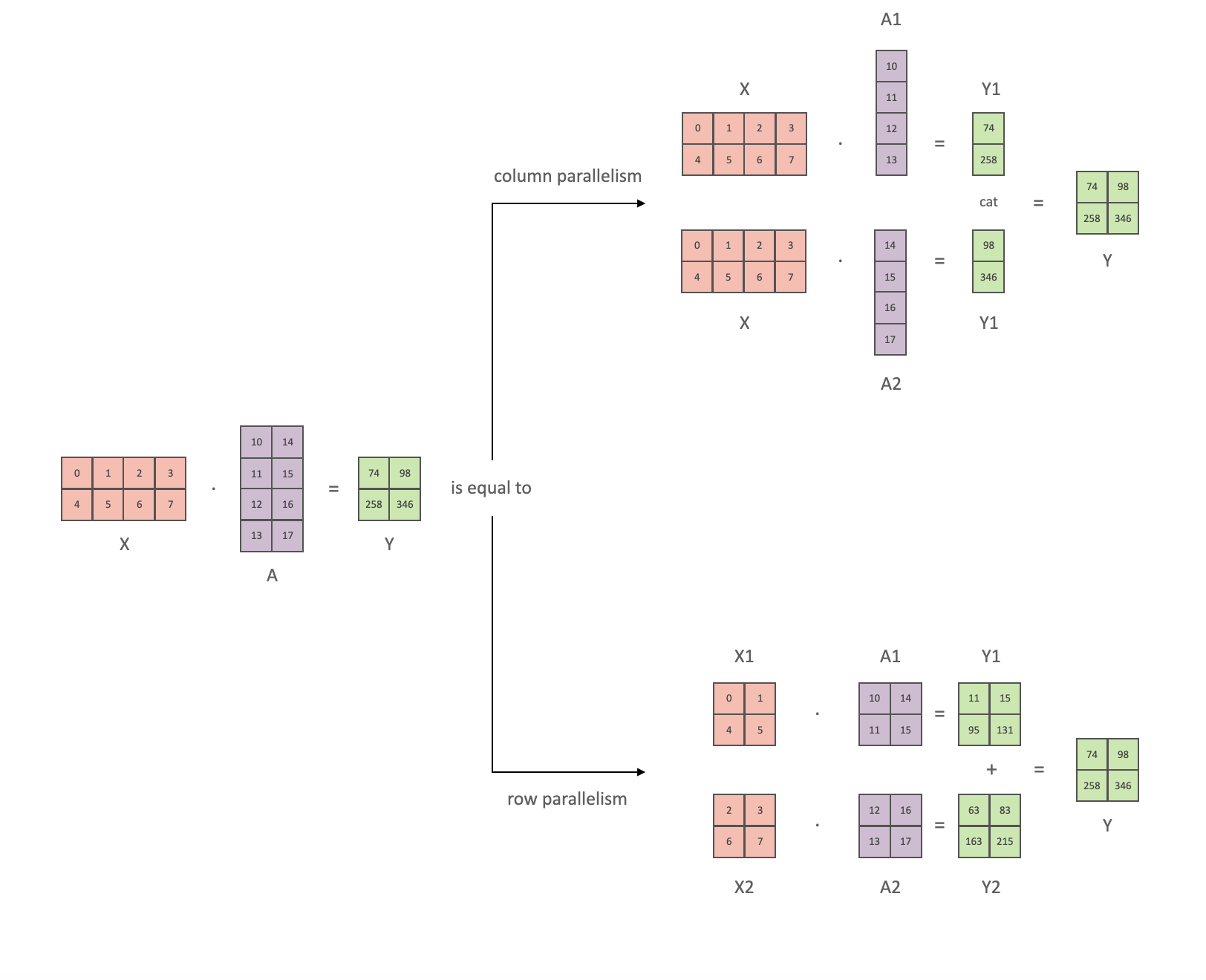
如果我们将权重矩阵 按列拆分到 N 个 GPU 上,并行执行矩阵乘法 到 ,那么我们将得到 N 个输出向量 、、…、,这些向量可以独立输入到 GeLU 中:
利用这一原理,我们可以更新任意深度的 MLP,而无需 GPU 之间进行任何同步,直到最后,我们才需要重建输出向量
Megatron-LM 论文作者为此提供了一个有用的例子:
Self-Attention 的张量并行更简单,因为 self-attention 天然的是多头注意力机制,可以将每个头的计算分配到不同的 GPU 上
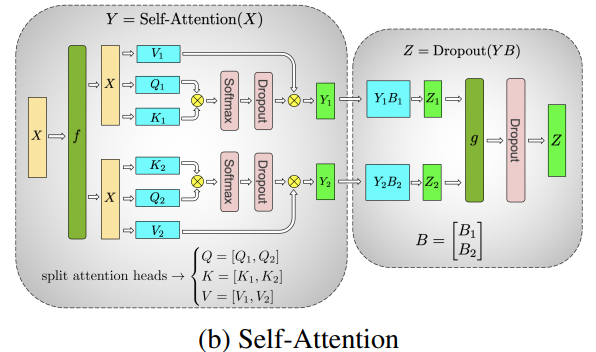
在上图中,我们可以用 2 个 GPU 并行的计算 self-attention,其中每个 GPU 计算一个头的注意力机制。那原则上,有几个头就可以用几个 GPU 并行计算
- Continuous batching
在传统的批处理方法中,一批请求必须全部完成处理后才能一起返回结果。这就意味着较短请求需要等待较长请求处理完成,导致了 GPU 资源的浪费和推理延迟的增加。而 Continuous Batching 技术允许模型在处理完当前迭代后,如果有请求已经处理完成,则可以立即返回该请求的结果,而不需要等待整个批次的请求都处理完成,这样可以显著提高硬件资源的利用率并减少空闲时间
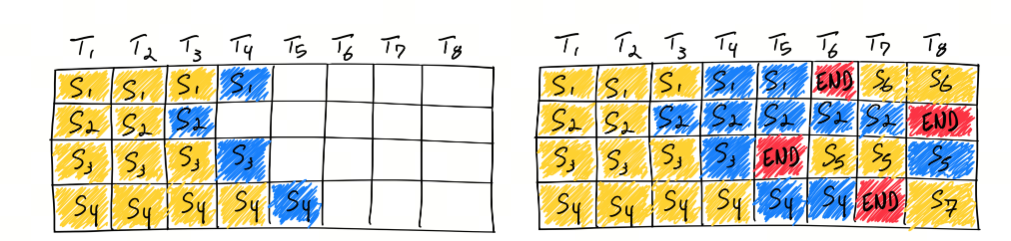
此外,Continuous Batching 还能够解决不同请求计算量不同导致的资源浪费问题,通过迭代级别的调度动态调整批处理大小,适应不同请求的复杂程度,有效降低高复杂度请求的等待时间
值得注意的是,实现 Continuous Batching 需要考虑一些关键问题,如对 Early-finished Requests、Late-joining Requests 的处理,以及如何处理不同长度的请求 Batching。OCRA 提出的两个设计思路:Iteration-level Batching 和 Selective Batching,就是为了解决这些问题
- Flash Attention
Flash Attention 是一种新型的注意力机制算法,由斯坦福大学和纽约州立大学布法罗分校的科研团队共同开发,旨在解决传统 Transformer 模型在处理长序列数据时面临的时间和内存复杂度高的问题。该算法的核心思想是减少 GPU 高带宽内存(HBM)和 GPU 片上 SRAM 之间的内存读写次数,通过分块计算(tiling)和重计算(recomputation)技术,显著降低了对 HBM 的访问频率,从而提升了运行速度并减少了内存使用
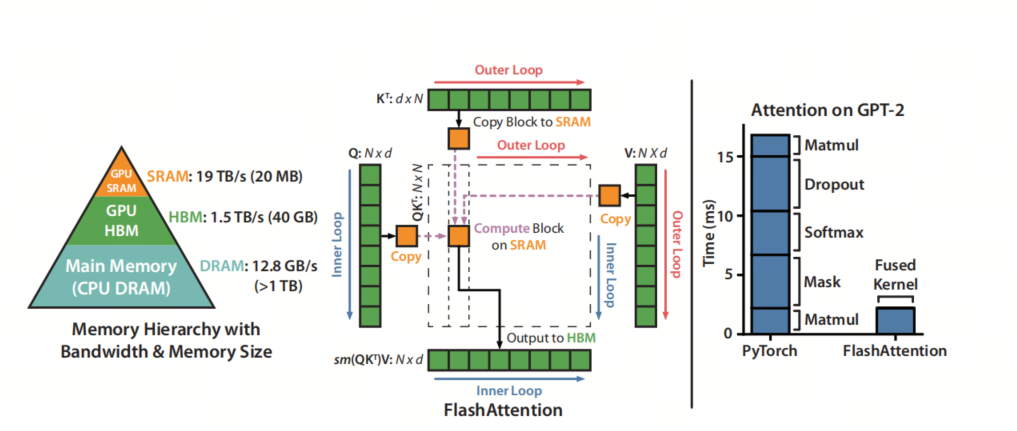
Flash Attention 通过 IO 感知的设计理念,优化了内存访问模式,使得 Transformer 模型在长序列处理上更加高效,为构建更长上下文的高质量模型提供了可能
- PagedAttention
vLLM 引入了 PagedAttention,这是一种注意力算法,其灵感来自操作系统中虚拟内存和分页的经典思想。与传统的注意力算法不同,PagedAttention 允许在非连续的内存空间中存储连续的键和值。具体来说,PagedAttention 将每个序列的 KV 缓存划分为块,每个块包含固定数量 token 的键和值。在注意力计算过程中,PagedAttention 内核会高效地识别和获取这些块
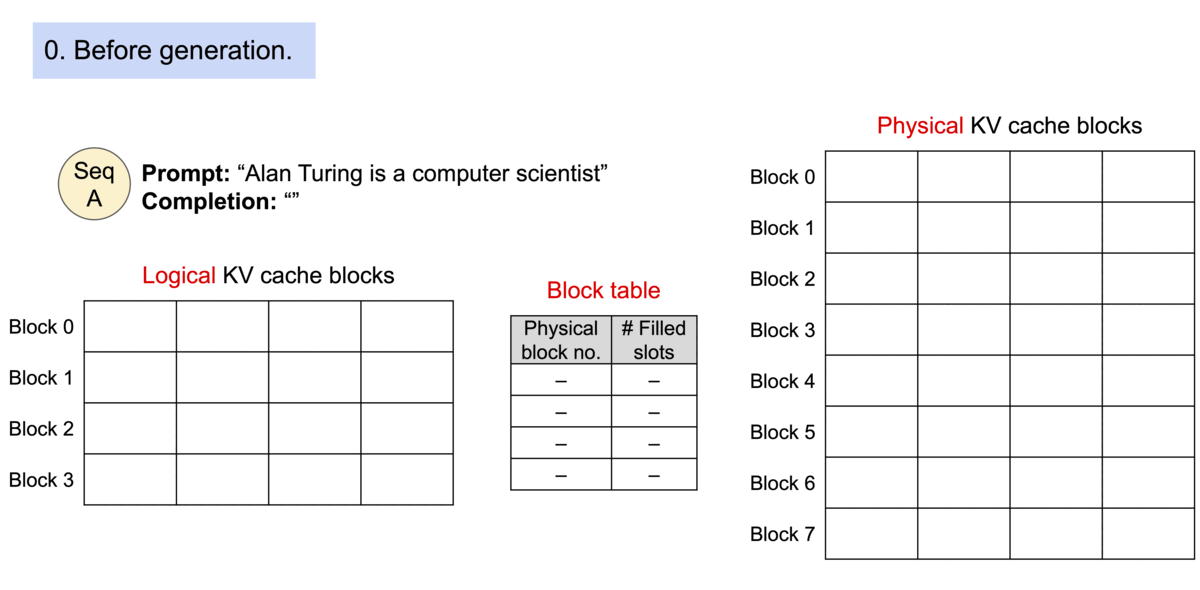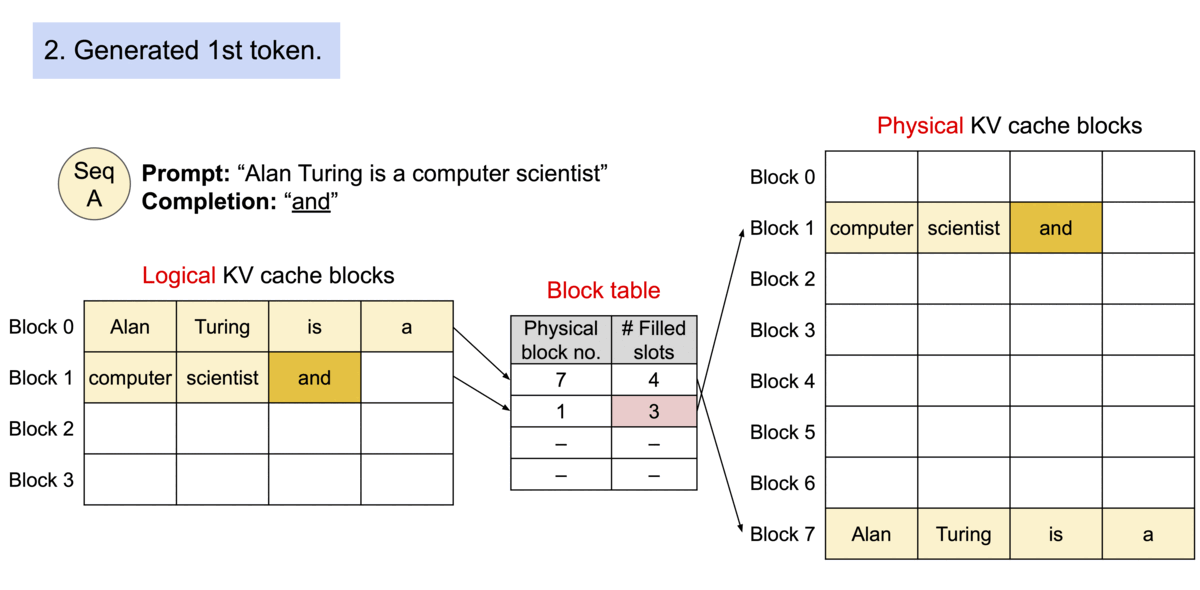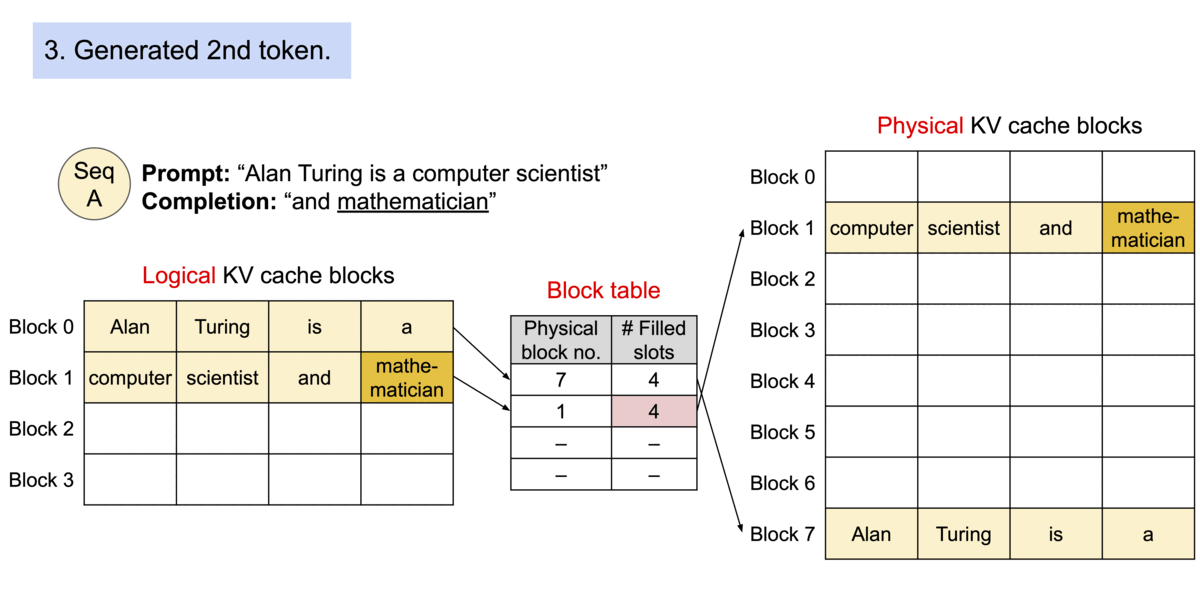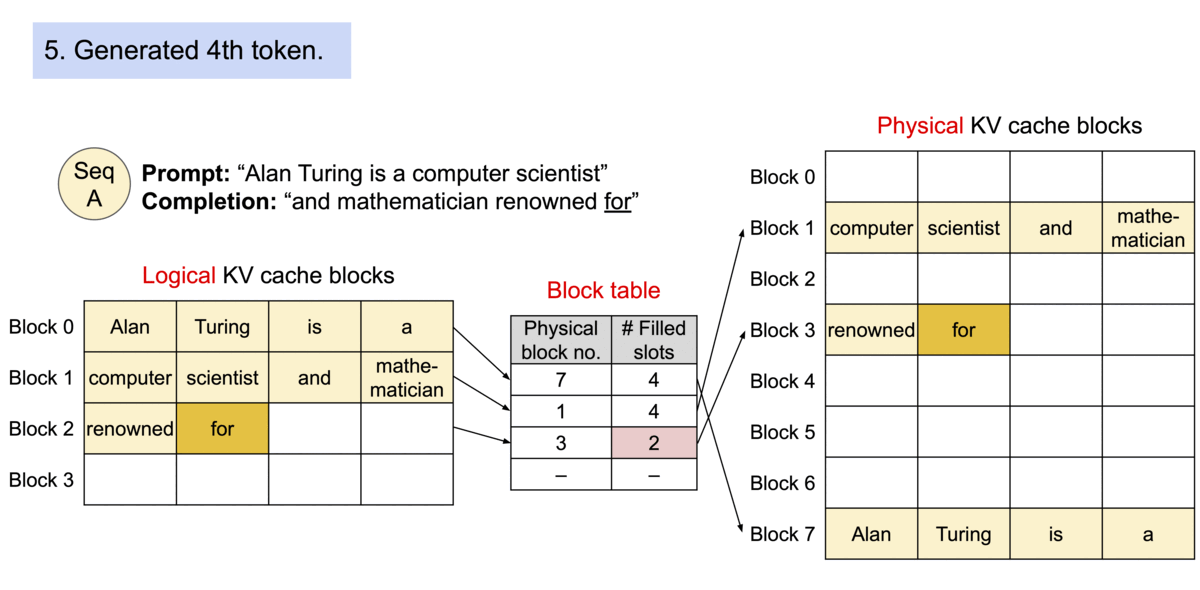
TGI 的特性
- 简单的启动器:TGI 提供了一个简单的启动器,可以轻松服务最流行的 LLMs
- 生产就绪:TGI 集成了分布式追踪(使用 Open Telemetry)和 Prometheus 指标,满足生产环境的需求
- 张量并行:通过在多个 GPU 上进行张量并行计算,TGI 能够显著加快推理速度
- 令牌流式传输:使用服务器发送事件(SSE)实现令牌的流式传输
- 连续批处理:对传入请求进行连续批处理,提高总体吞吐量
- 优化的推理代码:针对最流行的架构,TGI 使用 Flash Attention 和 Paged Attention 等技术优化了 Transformers 代码
- 多种量化支持:支持 bitsandbytes、GPT-Q、EETQ、AWQ、Marlin 和 fp8 等多种量化方法
- 安全加载权重:使用 Safetensors 进行权重加载,提高安全性
- 水印技术:集成了”A Watermark for Large Language Models”的水印技术
- 灵活的生成控制:支持 logits warper(温度缩放、top-p、top-k、重复惩罚等)、停止序列和对数概率输出
- 推测生成:实现了约 2 倍的延迟优化
- 引导/JSON输出:支持指定输出格式,加速推理并确保输出符合特定规范
- 自定义提示生成:通过提供自定义提示来指导模型的输出,从而轻松生成文本
- 微调支持:利用微调模型执行特定任务,以实现更高的精度和性能
- 硬件支持:除了 NVIDIA GPU,TGI 还支持 AMD GPU、Intel GPU、Inferentia、Gaudi 和 Google TPU 等多种硬件