Prompting
训练大型预训练语言模型非常耗时且计算密集。随着模型规模的增长,人们越来越关注更高效的训练方法,比如 Prompting。Prompting 通过包含一段描述任务或展示任务示例的文本提示,为特定的下游任务调整一个冻结的预训练模型。有了 Prompting,你可以避免为每个下游任务完全训练一个单独的模型,而是使用同一个冻结的预训练模型。这样做轻松得多,因为你可以用同一个模型处理多个不同的任务,而且训练和存储一小套提示参数比训练所有模型参数要高效得多
Soft prompts
Soft Prompts(软提示)与 Hard Prompts(硬提示)相对。软提示是可学习的连续向量,可以通过梯度优化方法针对特定数据集进行优化。这种方法不需要人工设计,可以自动优化以适应不同任务,计算效率高,支持多任务学习。然而,软提示不可读,无法解释为何选择这些向量
软提示的工作原理是在模型输入层增加可学习的投影层,将原始输入映射到提示信息所表示的语义空间中。投影层中的参数通过训练数据学习得到,使得提示信息能够更好地适应任务需求
主流方法
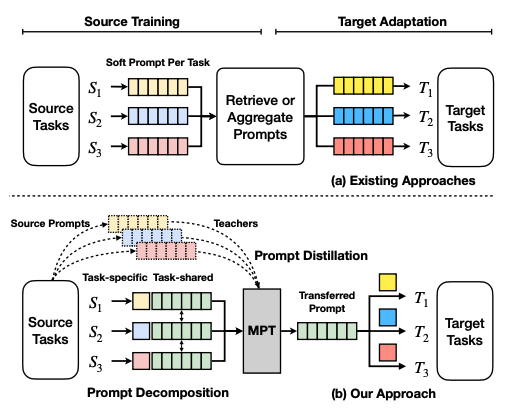
Prompt Tuning
Prompt Tuning 的核心思想在于 prompt tokens 有自己的参数,这些参数可以独立更新。这意味着你可以保持预训练模型的参数不变,只更新 prompt tokens 的嵌入向量的梯度。这样的结果与传统的训练整个模型的方法相当,并且随着模型大小的增加,Prompt Tuning 的性能也会提升
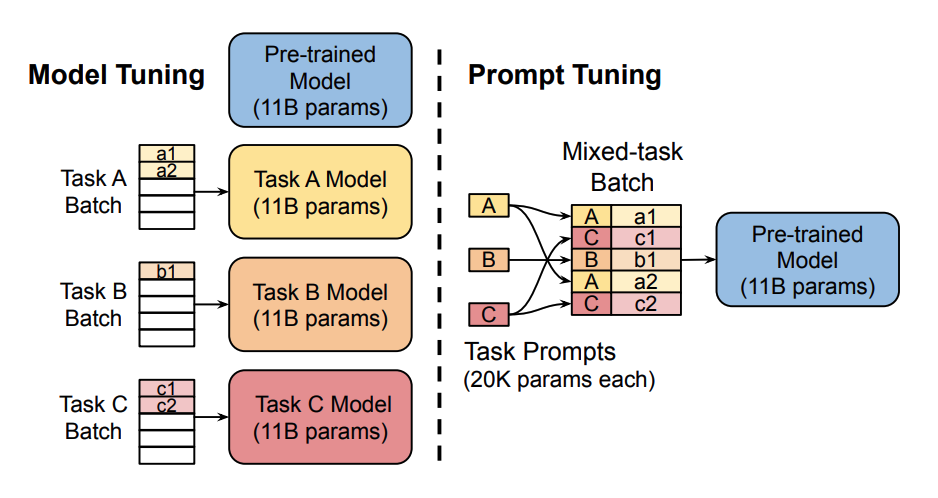
Prefix-Tuning
Prefix-Tuning 是 Prompt Tuning 的一种变体,它通过在模型输入的前缀位置添加可学习的提示向量来实现。这种方法的优势在于可以在不改变模型结构的情况下,为不同的任务提供不同的提示
Prefix-Tuning 和 Prompt Tuning 最主要区别在于,Prefix-Tuning 的前缀参数被插入到模型的所有层中,而 Prompt Tuning 只将提示参数添加到模型的 embedding 层
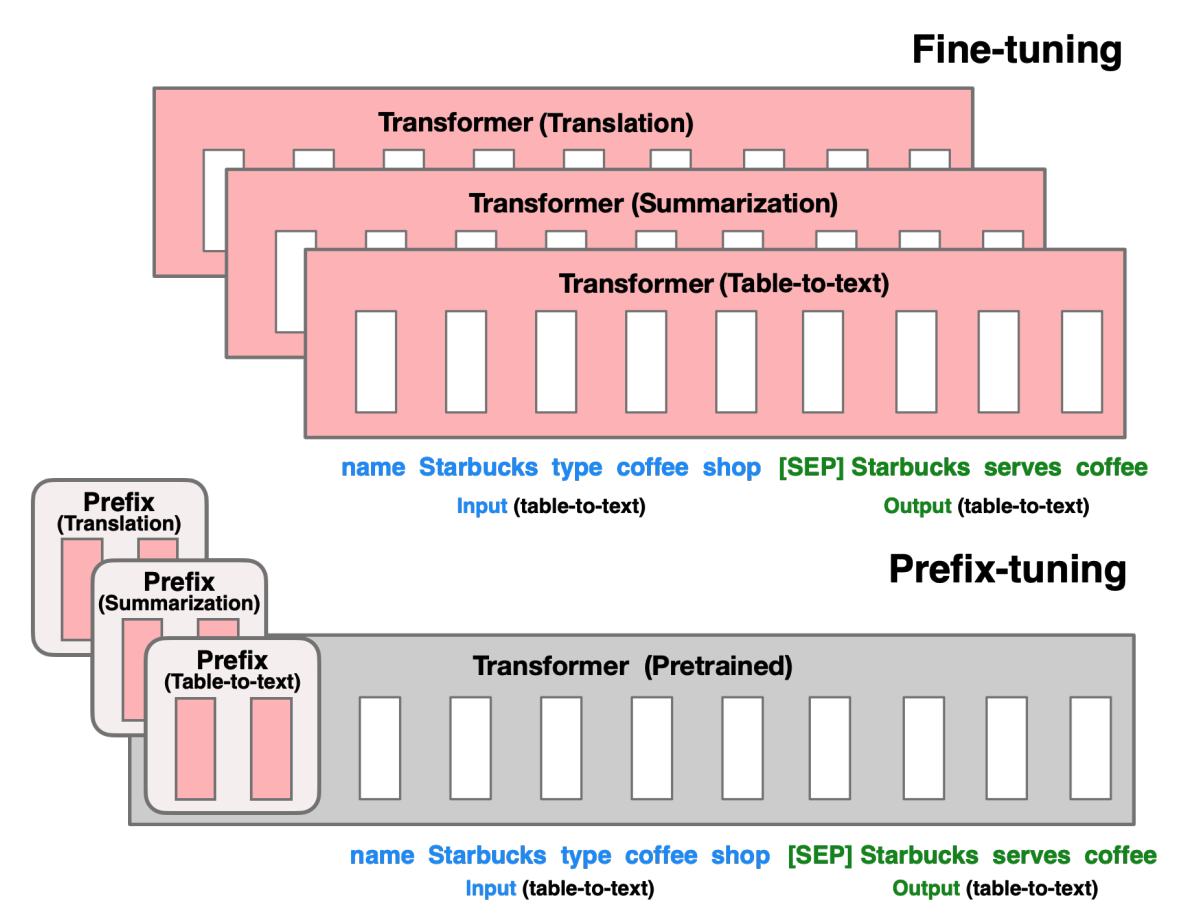
P-Tuning
P-tuning 主要是为自然语言理解(NLU)任务设计的,它是 Soft prompts 的另一种变体。P-tuning 添加了一个可训练的嵌入张量,这个张量可以被优化以找到更好的提示,并且它使用一个提示编码器(一个双向长短期记忆网络或 LSTM)来优化提示参数
P-tuning 的特点是将 Decoder 架构的模型变得适应 Encoder 架构的任务,如 NLU 任务
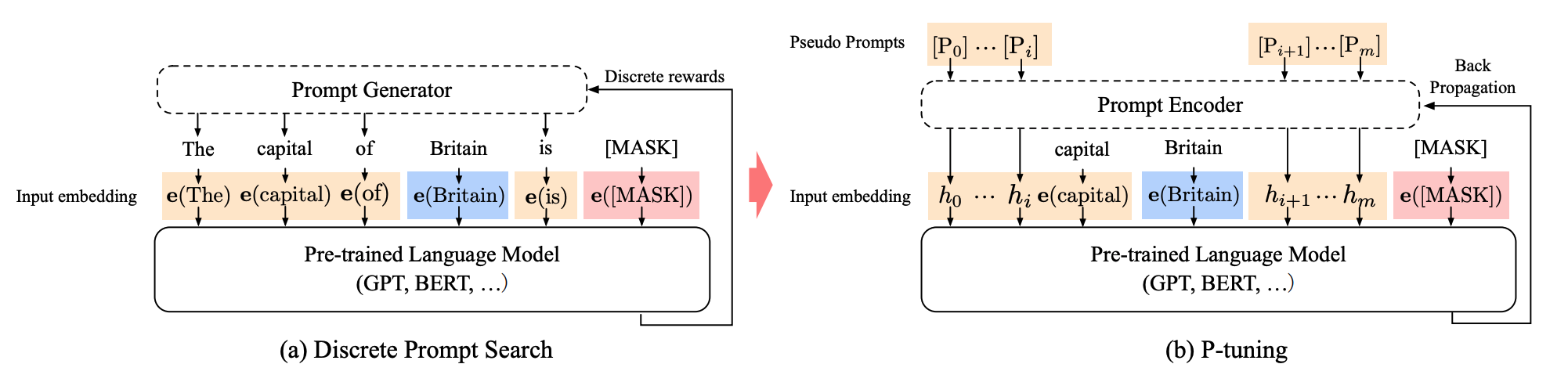
Multitask prompt tuning
多任务提示调整(MPT)是一种从数据中学习单一提示的方法,该提示可以用于多种任务类型,并可以共享以适应不同的目标任务。与之相对的其他现有方法则为每个任务学习一个单独的软提示,这些提示需要被检索或聚合以适应目标任务
简而言之:MPT 先学习一个通用的提示,然后再根据具体任务进行调整