这节课会带给你
- 如何用你的垂域数据补充 LLM 的能力
- 如何构建你的垂域(向量)知识库
- 搭建一套完整 RAG 系统需要哪些模块
- 搭建 RAG 系统时更多的有用技巧
什么是检索增强生成 (RAG)
大模型目前固有的局限性
大语言模型(LLM)是概率生成系统
- 知识时效性:模型知识截止于训练数据时间点(联网搜索)
- 推理局限性:本质是概率预测而非逻辑运算,复杂数学推理易出错(DeepSeek-R1 的架构有所不同)
- 专业领域盲区:缺乏垂直领域知识,不知道你私有的领域/业务知识
- 幻觉现象:可能生成看似合理但实际错误的内容
1、2 都解决了,4 也许之后能解决,但是 3 是业务结合的场景,都是私有化的形态,公共通用模型必定无法解决
私有化解决的方法有两个:
- RAG
- 指令微调
详见下文:RAG VS. Fine-tuning
为什么会用到 RAG
- 提高准确性:通过检索相关的信息,RAG 可以提高生成文本的准确性
- 减少训练成本:与需要大量数据来训练的大型生成模型相比,RAG 可以通过检索机制来减少所需的训练数据量,从而降低训练成本
- 适应性强:RAG 模型可以适应新的或不断变化的数据
RAG 概念
RAG(Retrieval Augmented Generation)顾名思义,通过检索外部数据的方法来增强生成模型的能力
论文:Retrieval-Augmented Generation for Large Language Models: A Survey
类比:你可以把这个过程想象成开卷考试。让 LLM 先翻书,再回答问题
RAG VS. Fine-tuning
RAG(检索增强⽣成)是把内部的⽂档数据先进⾏ embedding,借助检索先获得⼤致的知识范围答案,再结合 prompt 给到 LLM,让 LLM ⽣成最终的答案
Fine-tuning(微调)是⽤⼀定量的数据集对 LLM 进⾏局部参数的调整,以期望 LLM 更加理解我们的业务逻辑,有更好的 zero-shot 能⼒
RAG 系统的基本搭建流程
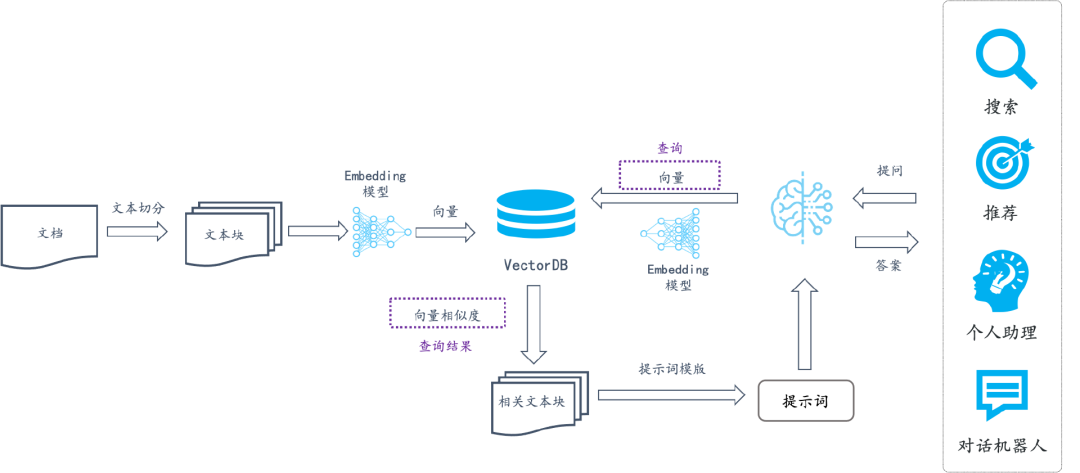
搭建过程:
- 索引 (Indexing):这⼀步对于在随后的检索阶段实现⾼效的相似性搜索⾄关重要
- 加载 (load):⾸先清理和提取各种格式的原始数据,如 PDF、HTML、 Word、Markdown,然后将其转换为统⼀的纯⽂本格式
- 切割 (split):为了适应语⾔模型的上下⽂限制,⽂本被分割成更⼩的、可消化的块(chunk)
- 嵌入 (embed):然后使⽤嵌⼊模型将块编码成向量表示
- 存储 (store):将 chunk 编码的向量存储在向量数据库中
- 检索 (Retrieval):封装检索接口,构建调用流程:Query → 检索 → Prompt → LLM → 回复
- 在收到⽤户查询(Query)后,RAG 系统采⽤与索引阶段相同的编码模型将查询转换为向量表示
- 然后计算索引语料库(向量数据库)中查询向量与块向量的相似性得分
- 匹配检索最⾼ k(Top-K)块,这些块被⽤作扩展上下⽂与 Query 构建 prompt
注意点:
- 索引在实际应用中往往是一个增量过程
- 如何将内容进行恰当地切割是一个关键节点,很大程度决定了 RAG 系统的优劣,往往是一个重要的优化点
- 随着数据增多,向量数据库检索可能会成为性能瓶颈(需要类似 MySQL 分库分表、读写分离、主从复制的优化手段)
- Query 向量化的 Embedding 模型一定要和文档资料使用的 Embedding 模型是同一个
文档的加载与切割
# pdf 解析库
pip install pdfminer.sixfrom pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
def extract_text_from_pdf(filename, page_numbers=None, min_line_length=1):
'''从 PDF 文件中(按指定页码)提取文字'''
paragraphs = []
buffer = ''
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码范围,跳过范围外的页
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
# 按空行分隔,将文本重新组织成段落
lines = full_text.split('\n')
for text in lines:
if len(text) >= min_line_length:
buffer += (' '+text) if not text.endswith('-') else text.strip('-')
elif buffer:
paragraphs.append(buffer)
buffer = ''
if buffer:
paragraphs.append(buffer)
return paragraphsparagraphs = extract_text_from_pdf("llama2.pdf", min_line_length=10)
for para in paragraphs[:4]:
print(para+"\n")LLM 接口封装
pip install --upgrade openai
# 读取 .env 环境变量文件
pip install -U python-dotenv# .env
OPENAI_API_KEY=your openai api key
OPENAI_BASE_URL=https://api.openai-hk.com/v1from openai import OpenAI
import os
from dotenv import load_dotenv, find_dotenv
# 加载环境变量
_ = load_dotenv(find_dotenv(), verbose=True) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEY
client = OpenAI()
def get_completion(prompt, model="gpt-4o"):
'''封装 openai 接口'''
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小,1 最大
)
return response.choices[0].message.contenttemperature 表示模型生成的随机性:
- 企业中做知识库问答和 RAG 时建议不要设太大,不要有太多创新,就基于知识库内容进行回答
- 如果要做一些文案生成等需要创造力的内容时,可以设大一些
Prompt 模板
# context:从向量数据库检索出来的原始文档
# query:用户的提问
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
已知信息:
{context}
用户问:
{query}
如果已知信息不包含用户问题的答案,或者已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
请不要输出已知信息中不包含的信息或答案。
请用中文回答用户问题。
"""
def build_prompt(prompt_template, **kwargs):
'''将 Prompt 模板赋值'''
inputs = {}
for k, v in kwargs.items():
if isinstance(v, list) and all(isinstance(elem, str) for elem in v):
val = '\n\n'.join(v)
else:
val = v
inputs[k] = val
return prompt_template.format(**inputs)