文本分割的粒度
缺陷:
- 粒度太大可能导致检索不精准,粒度太小可能导致信息不全面
- 问题的答案可能跨越两个片段
改进:按一定粒度,部分重叠式的切割文本,使上下文更完整
pip install nltkfrom nltk.tokenize import sent_tokenize
import json
# chunk_size 一般根据文档内容或大小来设置
# overlap_size 一般设置 chunk_size 大小的 10%-20% 之间
def split_text(paragraphs, chunk_size=2000, overlap_size=300):
'''按指定 chunk_size 和 overlap_size 交叠割文本'''
sentences = [s.strip() for p in paragraphs for s in sent_tokenize(p)]
chunks = []
i = 0
while i < len(sentences):
chunk = sentences[i]
overlap = ''
prev_len = 0
prev = i - 1
# 向前计算重叠部分
while prev >= 0 and len(sentences[prev])+len(overlap) <= overlap_size:
overlap = sentences[prev] + ' ' + overlap
prev -= 1
chunk = overlap+chunk
next = i + 1
# 向后计算当前 chunk
while next < len(sentences) and len(sentences[next])+len(chunk) <= chunk_size:
chunk = chunk + ' ' + sentences[next]
next += 1
chunks.append(chunk)
i = next
return chunks此处 sent_tokenize 为针对英文的实现,针对中文的实现参考:
import re
import jieba
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
def to_keywords(input_string):
"""将句子转成检索关键词序列"""
# 按搜索引擎模式分词
word_tokens = jieba.cut_for_search(input_string)
# 加载停用词表
stop_words = set(stopwords.words('chinese'))
# 去除停用词
filtered_sentence = [w for w in word_tokens if not w in stop_words]
return ' '.join(filtered_sentence)
def sent_tokenize(input_string):
"""按标点断句"""
# 按标点切分
sentences = re.split(r'(?<=[。!?;?!])', input_string)
# 去掉空字符串
return [sentence for sentence in sentences if sentence.strip()]上面的切割方法比较基础:
- 基于某些规则来切分(如:
\n、\n\n、句号、问号等) - 基于字符数 chunk_size 和 overlap_size 来重叠切割
对于复杂的文本或业务需求,需要:
- NSP 任务来进行微调训练一个切分模型(拿自己业务的数据来投喂)
能够实现更好的切分效果,如:A 和 B 两个句子(段落)是否有关系,有关系则进行合并
检索后排序
问题:有时,最合适的答案不一定排在检索的最前面
方案:
- 检索时过召回一部分文本(TopK 大一点)
- 通过一个排序模型对 query 和 document 重新打分排序
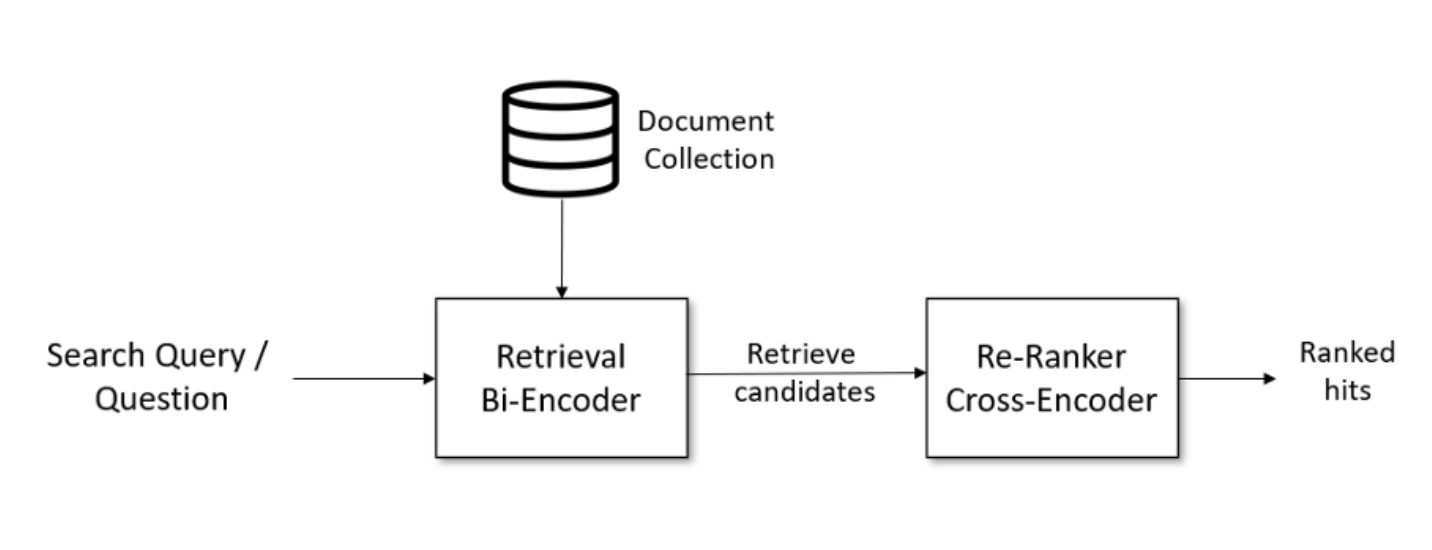
从向量数据库检索出来多个和问题关联的文档通过一个 Re-Ranker 的模型进行重新打分排序
pip install sentence_transformers将 Re-Ranker 模型下载到电脑本地:
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2', max_length=512) # 英文,模型较小
# model = CrossEncoder('BAAI/bge-reranker-large', max_length=512) # 多语言,国产,模型较大测试:
user_query = "how safe is llama 2"
# user_query = "llama 2 安全性如何"
scores = model.predict([(user_query, doc) for doc in search_results['documents'][0]])
# 按得分排序
sorted_list = sorted(zip(scores, search_results['documents'][0]), key=lambda x: x[0], reverse=True)
for score, doc in sorted_list:
print(f"{score}\t{doc}\n")
# 6.613734722137451 We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs, Llama 2 is a new technology that carries potential risks with use (Bender et al., 2021b; Weidinger et al., 2021; Solaiman et al., 2023).
#
# 5.310717582702637 In this work, we develop and release Llama 2, a family of pretrained and fine-tuned LLMs, Llama 2 and Llama 2-Chat, at scales up to 70B parameters. On the series of helpfulness and safety benchmarks we tested, Llama 2-Chat models generally perform better than existing open-source models.
#
# 4.709955215454102 We provide a responsible use guide¶ and code examples‖ to facilitate the safe deployment of Llama 2 and Llama 2-Chat. More details of our responsible release strategy can be found in Section 5.3.
#
# 4.5439653396606445 We also share novel observations we made during the development of Llama 2 and Llama 2-Chat, such as the emergence of tool usage and temporal organization of knowledge. Figure 3: Safety human evaluation results for Llama 2-Chat compared to other open-source and closed source models.
#
# 4.0338897705078125 Additionally, these safety evaluations are performed using content standards that are likely to be biased towards the Llama 2-Chat models. We are releasing the following models to the general public for research and commercial use‡: 1.
# 如果不想把 Re-Ranker 模型下载到本地,有一些在线的 API 服务:
- Cohere Rerank:支持多语言
- Jina Rerank:目前只支持英文
混合检索 (Hybrid Search)
在实际生产中,传统的关键字检索(稀疏表示)与向量检索(稠密表示)各有优劣
举个具体例子,比如文档中包含很长的专有名词,关键字检索往往更精准而向量检索容易引入概念混淆
# 背景说明:在医学中“小细胞肺癌”和“非小细胞肺癌”是两种不同的癌症
query = "非小细胞肺癌的患者"
documents = [
"玛丽患有肺癌,癌细胞已转移",
"刘某肺癌I期",
"张某经诊断为非小细胞肺癌III期",
"小细胞肺癌是肺癌的一种"
]
query_vec = get_embeddings([query])[0]
doc_vecs = get_embeddings(documents)
print("Cosine distance:")
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
# Cosine distance:
# 0.8915956814209096
# 0.8902380296876382
# 0.9043403228477503
# 0.9136486327152477
# 这里对于专有名词,“小细胞肺癌”和“非小细胞肺癌”都是混在一起的(3、4 相关性高)所以,有时候我们需要结合不同的检索算法,来达到比单一检索算法更优的效果,这就是混合检索
混合检索的核心是:综合文档 在不同检索算法下的排序名次(rank),为其生成最终排序
一个最常用的算法叫 Reciprocal Rank Fusion (RRF)
其中 表示所有使用的检索算法的集合, 表示使用算法 检索时,文档 的排序, 是个常数
很多向量数据库都支持混合检索(见主流向量数据库功能对比),也可以根据上述原理自己实现
手写个简单的例子
注意:需要安装好 Elastic Search Server,并启动!
# Elastic Search python 客户端
pip install elasticsearch7- 基于关键字检索的排序
import time
class MyEsConnector:
def __init__(self, es_client, index_name, keyword_fn):
self.es_client = es_client
self.index_name = index_name
self.keyword_fn = keyword_fn
def add_documents(self, documents):
'''文档灌库'''
if self.es_client.indices.exists(index=self.index_name):
self.es_client.indices.delete(index=self.index_name)
self.es_client.indices.create(index=self.index_name)
actions = [
{
"_index": self.index_name,
"_source": {
"keywords": self.keyword_fn(doc),
"text": doc,
"id": f"doc_{i}"
}
}
for i, doc in enumerate(documents)
]
helpers.bulk(self.es_client, actions)
time.sleep(1)
def search(self, query_string, top_n=3):
'''检索'''
search_query = {
"match": {
"keywords": self.keyword_fn(query_string)
}
}
res = self.es_client.search(
index=self.index_name, query=search_query, size=top_n)
return {
hit["_source"]["id"]: {
"text": hit["_source"]["text"],
"rank": i,
}
for i, hit in enumerate(res["hits"]["hits"])
}from chinese_utils import to_keywords # 使用中文的关键字提取函数
# 引入配置文件
ELASTICSEARCH_BASE_URL = os.getenv('ELASTICSEARCH_BASE_URL')
ELASTICSEARCH_PASSWORD = os.getenv('ELASTICSEARCH_PASSWORD')
ELASTICSEARCH_NAME= os.getenv('ELASTICSEARCH_NAME')
es = Elasticsearch(
hosts=[ELASTICSEARCH_BASE_URL],
http_auth=(ELASTICSEARCH_NAME, ELASTICSEARCH_PASSWORD), # 用户名,密码
)
# 创建 ES 连接器
es_connector = MyEsConnector(es, "demo_es_rrf", to_keywords)
# 文档灌库
es_connector.add_documents(documents)
# 关键字检索
keyword_search_results = es_connector.search(query, 3)
print(json.dumps(keyword_search_results, indent=4, ensure_ascii=False))- 基于向量检索的排序
# 创建向量数据库连接器
vecdb_connector = MyVectorDBConnector("demo_vec_rrf", get_embeddings)
# 文档灌库
vecdb_connector.add_documents(documents)
# 向量检索
vector_search_results = {
"doc_"+str(documents.index(doc)): {
"text": doc,
"rank": i
}
for i, doc in enumerate(
vecdb_connector.search(query, 3)["documents"][0]
)
} # 把结果转成跟上面关键字检索结果一样的格式
print(json.dumps(vector_search_results, indent=4, ensure_ascii=False))- 基于 RRF 的融合排序
参考资料:https://learn.microsoft.com/zh-cn/azure/search/hybrid-search-ranking
def rrf(ranks, k=1):
ret = {}
# 遍历每次的排序结果
for rank in ranks:
# 遍历排序中每个元素
for id, val in rank.items():
if id not in ret:
ret[id] = {"score": 0, "text": val["text"]}
# 计算 RRF 得分
ret[id]["score"] += 1.0/(k+val["rank"])
# 按 RRF 得分排序,并返回
return dict(sorted(ret.items(), key=lambda item: item[1]["score"], reverse=True))import json
# 融合两次检索的排序结果
reranked = rrf([keyword_search_results, vector_search_results])
print(json.dumps(reranked, indent=4, ensure_ascii=False))PDF 文档中的表格怎么处理
1. 将每页 PDF 转成图片
pip install PyMuPDF
pip install matplotlibimport os
import fitz
from PIL import Image
def pdf2images(pdf_file):
'''将 PDF 每页转成一个 PNG 图像'''
# 保存路径为原 PDF 文件名(不含扩展名)
output_directory_path, _ = os.path.splitext(pdf_file)
if not os.path.exists(output_directory_path):
os.makedirs(output_directory_path)
# 加载 PDF 文件
pdf_document = fitz.open(pdf_file)
# 每页转一张图
for page_number in range(pdf_document.page_count):
# 取一页
page = pdf_document[page_number]
# 转图像
pix = page.get_pixmap()
# 从位图创建 PNG 对象
image = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
# 保存 PNG 文件
image.save(f"./{output_directory_path}/page_{page_number + 1}.png")
# 关闭 PDF 文件
pdf_document.close()from PIL import Image
import os
import matplotlib.pyplot as plt
def show_images(dir_path):
'''显示目录下的 PNG 图像'''
for file in os.listdir(dir_path):
if file.endswith('.png'):
# 打开图像
img = Image.open(os.path.join(dir_path, file))
# 显示图像
plt.imshow(img)
plt.axis('off') # 不显示坐标轴
plt.show()pdf2images("llama2_page8.pdf")
show_images("llama2_page8")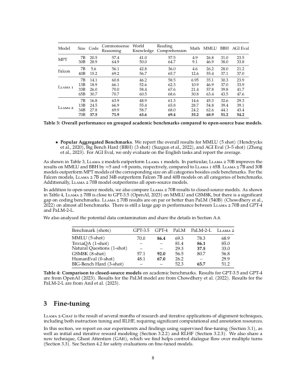
2. 识别图片中的表格
class MaxResize(object):
'''缩放图像'''
def __init__(self, max_size=800):
self.max_size = max_size
def __call__(self, image):
width, height = image.size
current_max_size = max(width, height)
scale = self.max_size / current_max_size
resized_image = image.resize(
(int(round(scale * width)), int(round(scale * height)))
)
return resized_imagepip install torchvision
pip install transformers
pip install timmimport torchvision.transforms as transforms
# 图像预处理
detection_transform = transforms.Compose(
[
MaxResize(800),
# 将原始的 PILImage 格式的数据格式化为可被 pytorch 快速处理的张量类型
transforms.ToTensor(),
# 固定的参数,是当前找到的最佳实践的归一参数
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)from transformers import AutoModelForObjectDetection
# 加载 TableTransformer 模型
model = AutoModelForObjectDetection.from_pretrained(
"microsoft/table-transformer-detection"
)# 识别后的坐标换算与后处理
def box_cxcywh_to_xyxy(x):
'''坐标转换'''
x_c, y_c, w, h = x.unbind(-1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h), (x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
'''区域缩放'''
width, height = size
boxes = box_cxcywh_to_xyxy(out_bbox)
boxes = boxes * torch.tensor(
[width, height, width, height], dtype=torch.float32
)
return boxes
def outputs_to_objects(outputs, img_size, id2label):
'''从模型输出中取定位框坐标'''
m = outputs.logits.softmax(-1).max(-1)
pred_labels = list(m.indices.detach().cpu().numpy())[0]
pred_scores = list(m.values.detach().cpu().numpy())[0]
pred_bboxes = outputs["pred_boxes"].detach().cpu()[0]
pred_bboxes = [
elem.tolist() for elem in rescale_bboxes(pred_bboxes, img_size)
]
objects = []
for label, score, bbox in zip(pred_labels, pred_scores, pred_bboxes):
class_label = id2label[int(label)]
if not class_label == "no object":
objects.append(
{
"label": class_label,
"score": float(score),
"bbox": [float(elem) for elem in bbox],
}
)
return objectsimport torch
# 识别表格,并将表格部分单独存为图像文件
def detect_and_crop_save_table(file_path):
# 加载图像(PDF页)
image = Image.open(file_path)
filename, _ = os.path.splitext(os.path.basename(file_path))
# 输出路径
cropped_table_directory = os.path.join(os.path.dirname(file_path), "table_images")
if not os.path.exists(cropped_table_directory):
os.makedirs(cropped_table_directory)
# 预处理
pixel_values = detection_transform(image).unsqueeze(0)
# 识别表格
with torch.no_grad():
outputs = model(pixel_values)
# 后处理,得到表格子区域
id2label = model.config.id2label
id2label[len(model.config.id2label)] = "no object"
detected_tables = outputs_to_objects(outputs, image.size, id2label)
print(f"检测到的表格数量:{len(detected_tables)}")
for idx in range(len(detected_tables)):
# 将识别从的表格区域单独存为图像
cropped_table = image.crop(detected_tables[idx]["bbox"])
cropped_table.save(os.path.join(cropped_table_directory,f"{filename}_{idx}.png"))detect_and_crop_save_table("llama2_page8/page_1.png")
show_images("llama2_page8/table_images")检测到的表格数量:
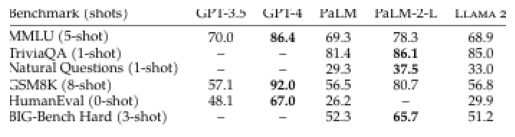
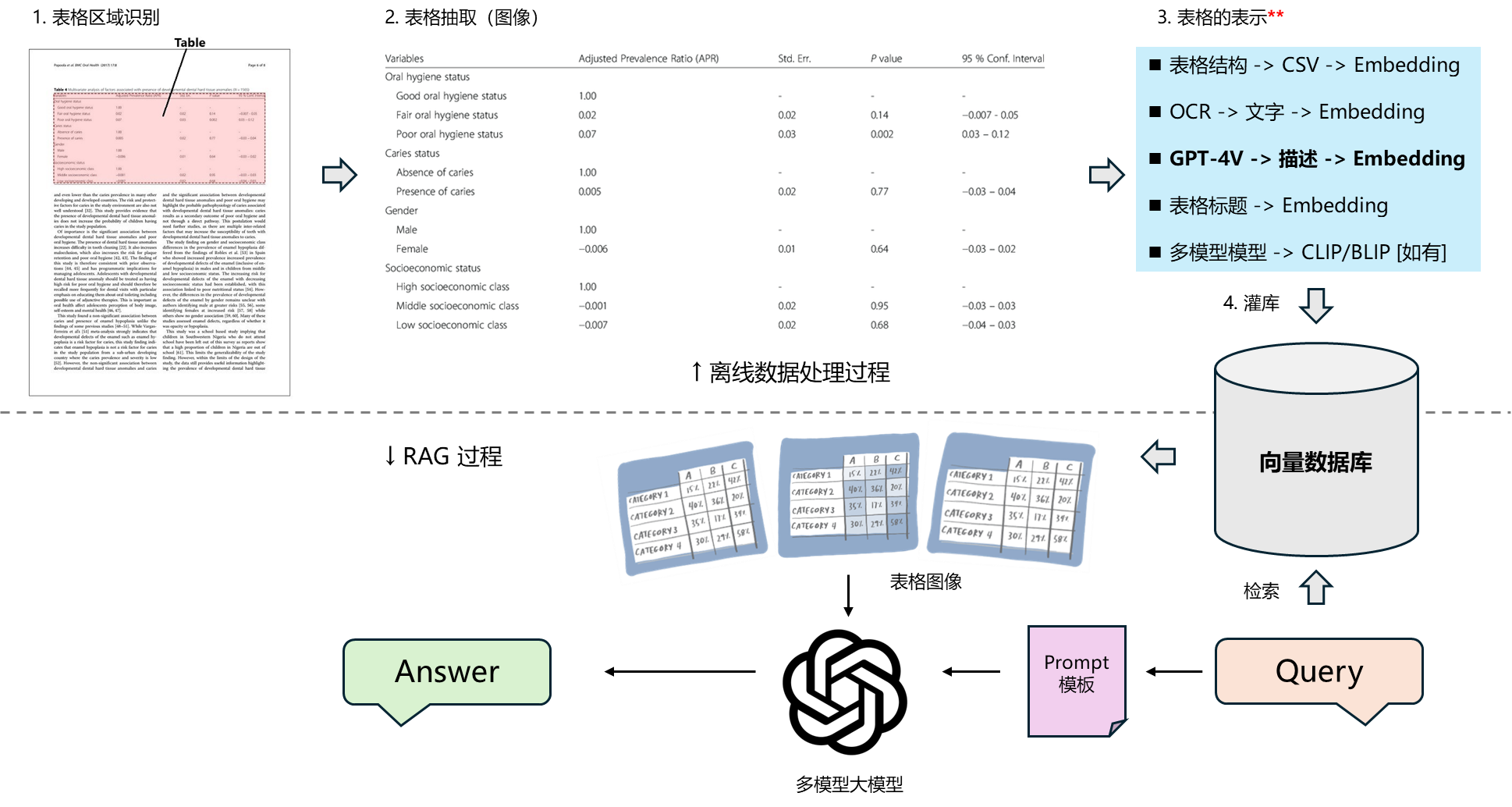
3. 基于 GPT-4 Vision API 做表格问答
import base64
from openai import OpenAI
client = OpenAI()
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def image_qa(query, image_path):
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="gpt-4o",
temperature=0,
seed=42,
messages=[{
"role": "user",
"content": [
{"type": "text", "text": query},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
],
}],
)
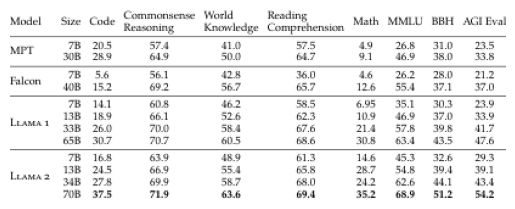
return response.choices[0].message.contentresponse = image_qa("哪个模型在 AGI Eval 数据集上表现最好。得分多少", "llama2_page8/table_images/page_1_0.png")
print(response)
# 在 AGI Eval 数据集上表现最好的模型是 LLaMA 2 70B,得分为 54.2。4. 用 GPT-4 Vision 生成表格图像描述,并向量化用于检索
import chromadb
from chromadb.config import Settings
class NewVectorDBConnector:
def __init__(self, collection_name, embedding_fn):
chroma_client = chromadb.Client(Settings(allow_reset=True))
# 为了演示,实际不需要每次 reset()
chroma_client.reset()
# 创建一个 collection
self.collection = chroma_client.get_or_create_collection(
name=collection_name)
self.embedding_fn = embedding_fn
def add_documents(self, documents):
'''向 collection 中添加文档与向量'''
self.collection.add(
embeddings=self.embedding_fn(documents), # 每个文档的向量
documents=documents, # 文档的原文
ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id
)
def add_images(self, image_paths):
'''向 collection 中添加图像'''
documents = [
image_qa("请简要描述图片中的信息", image)
for image in image_paths
]
self.collection.add(
embeddings=self.embedding_fn(documents), # 每个文档的向量
documents=documents, # 文档的原文
ids=[f"id{i}" for i in range(len(documents))], # 每个文档的 id
metadatas=[{"image": image} for image in image_paths] # 用 metadata 标记源图像路径
)
def search(self, query, top_n):
'''检索向量数据库'''
results = self.collection.query(
query_embeddings=self.embedding_fn([query]),
n_results=top_n
)
return resultsimages = []
dir_path = "llama2_page8/table_images"
for file in os.listdir(dir_path):
if file.endswith('.png'):
# 打开图像
images.append(os.path.join(dir_path, file))
new_db_connector = NewVectorDBConnector("table_demo",get_embeddings)
new_db_connector.add_images(images)query = "哪个模型在AGI Eval数据集上表现最差。得分多少"
results = new_db_connector.search(query, 1)
metadata = results["metadatas"][0]
print("====检索结果====")
print(metadata)
print("====回复====")
response = image_qa(query,metadata[0]["image"])
print(response)
# ====检索结果====
# [{'image': 'llama2_page8/table_images\\page_1_0.png'}]
# ====回复====
# 从表格中可以看出,在 AGI Eval 数据集上表现最差的模型是 **Falcon 7B**,其得分为 **21.2**。一些面向 RAG 的文档解析辅助工具
以上一步步手写代码可以了解其原理,实际项目中可以使用现有的工具:
- PyMuPDF:PDF 文件处理基础库,带有基于规则的表格与图像抽取(不准)
- RAGFlow:一款基于深度文档理解构建的开源 RAG 引擎,支持多种文档格式(火爆)
- Unstructured.io:一个开源 + SaaS 形式的文档解析库,支持多种文档格式
- LlamaParse:付费 API 服务,由 LlamaIndex 官方提供,解析不保证 100% 准确,实测偶有文字丢失或错位发生
- Mathpix:付费 API 服务,效果较好,可解析段落结构、表格、公式等(贵)
在工程上,PDF 解析本身是个复杂且琐碎的工作。以上工具都不完美,建议在自己实际场景测试后选择使用