各大平台 RAG
阿⾥云-百炼 RAG
https://bailian.console.aliyun.com/
创建应⽤ → 上传数据 → 知识索引
通过 Python 来调用 ARG 服务:
import os
from http import HTTPStatus
from dashscope import Application
response = Application.call(
# 若没有配置环境变量,可用百炼 API Key 将下行替换为:api_key="sk-xxx"
# 但不建议在生产环境中直接将 API Key 硬编码到代码中,以减少 API Key 泄露风险
api_key="输入你自身的key",
app_id='输入你自身的appId',
prompt='观察者模式的介绍?你是基于知识库回答的还是基于你自身来回复的?')
if response.status_code != HTTPStatus.OK:
print(f'request_id={response.request_id}')
print(f'code={response.status_code}')
print(f'message={response.message}')
print(f'请参考文档:https://help.aliyun.com/zh/model-studio/developer-reference/error-code')
else:
print(response.output.text)智普 RAG
Google-NoteBook
说说 GraphRAG
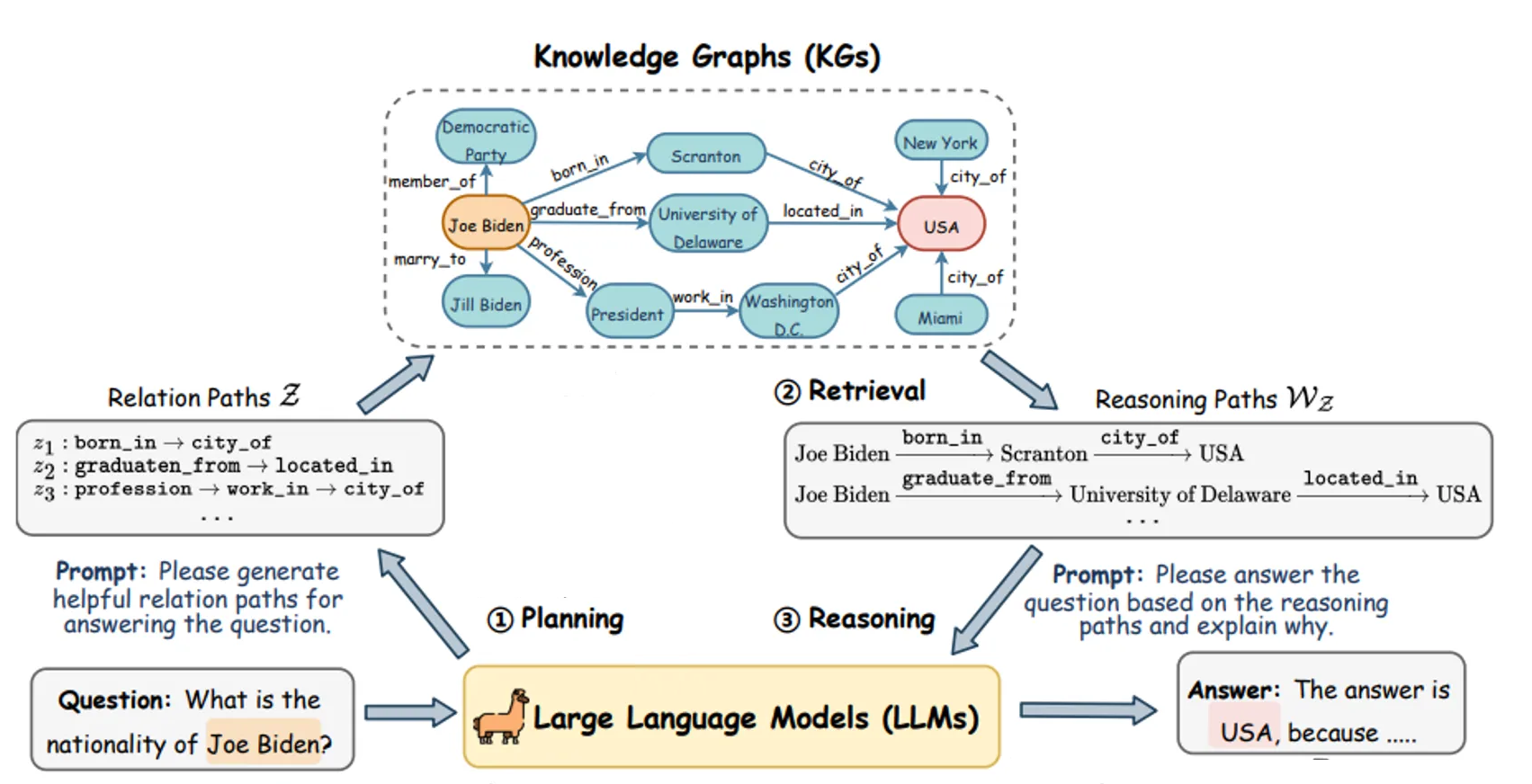
- 什么是 GraphRAG:核心思想是将知识预先处理成知识图谱
- 优点:适合复杂问题,尤其是以查询为中心的总结,例如:“XXX 团队去年有哪些贡献”
- 缺点:知识图谱的构建、清洗、维护更新等都有可观的成本(人力、数据量)
- 建议:
- GraphRAG 不是万能良药
- 领会其核心思想
- 遇到传统 RAG 无论如何优化都不好解决的问题时,酌情使用
总结
RAG 的流程
两个过程:
- 离线步骤
- 文档加载
- 文档切分
- 向量化
- 存入向量数据库
- 在线步骤
- 获得用户问题
- 用户问题向量化
- 检索向量数据库
- 将检索结果和用户问题填入 Prompt 模版
- 用最终获得的 Prompt 调用 LLM
- 由 LLM 生成回复
我用了一个开源的 RAG,不好使怎么办?
- 检查预处理效果:文档加载是否正确,切割的是否合理
- 测试检索效果:问题检索回来的文本片段是否包含答案
- 测试大模型能力:给定问题和包含答案文本片段的前提下,大模型能不能正确回答问题
经验
普通企业做 RAG,直接使用 RAGFlow 就好了
- RAGFlow:一款基于深度文档理解构建的开源 RAG 引擎,支持多种文档格式(火爆)
RAG 开发建议使用 LlamaIndex(数据增强框架,提供了 RAG 数据处理的一整套管道)优于 LangChain