数据存储
Data Storage/Persistence,离线存储、本地存储,浏览器主要组成 部分之一
目前常见的浏览器离线存储的方式如下:
- Cookie
- Web Storage:LocalStorage、SessionStorage
- WebSQL
- IndexedDB
- File System
WebSQL
Warning
基本被废弃,了解一下就好,使用 IndexedDB 代替。
目前来看,WebSQL 已经不再是 W3C 推荐规范,官方也已经不再维护。原因说的很清楚,当前的 SQL 规范采用 SQLite 的 SQL 方言,而作为一个标准,这是不可接受的。
另外,WebSQL 使用 SQL 语言来进行操作,更像是一个关系型数据库;而 IndexedDB 则更像是一个 NoSQL 数据库, 这也是目前 W3C 强推的浏览端数据库解决方案。
所以本文不再对 WebSQL 做过多的介绍。
WebSQL 数据库引入了一组使用 SQL 操作客户端数据库的 APIs。如果之前接触过诸如像 MySQL 这样的关系型数据库,学习过 SQL 语言,那么 WebSQL 没有任何难度。
最新版的 Safari、Chrome 和 Opera 浏览器都支持 WebSQL。
在 WebSQL 中,有 3 个核心方法:
openDatabase:使用现有的数据库或者新建的数据库创建一个数据库对象。transaction:控制事务,基于事务执行提交或者回滚。executeSql:执行实际的 SQL 查询。
打开数据库
使用 openDatabase() 方法来打开已存在的数据库,如果数据库不存在,则会创建一个新的数据库,使用代码如下:
const db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);openDatabase() 方法对应的 5 个参数:
- 数据库名称
- 版本号
- 描述文本
- 数据库大小
- 创建回调:会在创建数据库后被调用
执行操作
const id = '1'
const log = 'test'
db.transaction(function (tx) {
// tx 是一个 SQLTransaction 对象,代表一个事务
tx.executeSql('CREATE TABLE IF NOT EXISTS logs (id unique, log)');
tx.executeSql('INSERT INTO logs (id, log) VALUES (?, ?)', [id, log]);
});使用动态值来插入数据,避免 SQL 注入
同一事务中,只要发生错误,所有 SQL 都会回滚
executeSql(sqlStatement, arguments, callback, errorCallback)executeSql 完整的语法接收 4 个参数,分别是:
- SQL 语句:可以包含动态值
? - 参数:SQL 动态值传参
- 成功回调
- 错误回调
IndexedDB
简介
随着浏览器的功能不断增强,越来越多的网站开始考虑,将大量数据储存在客户端,这样可以减少从服务器获取数据,直接从本地获取数据。
现有的浏览器数据储存方案,都不适合储存大量数据:
- cookie 的大小不超过 4KB,且每次请求都会发送回服务器;
- LocalStorage、SessionStorage 在 2.5MB 到 10MB 之间(各家浏览器不同),而且不提供搜索功能,不能建立自定义的索引。
所以,需要一种新的解决方案,这就是 IndexedDB 诞生的背景。
MDN 官网是这样解释 IndexedDB 的:
IndexedDB 是一种底层 API,用于在客户端存储大量的结构化数据(可以存储 结构化克隆算法 支持的任何对象,包括文件、二进制大型对象
Blob等)。该 API 使用索引实现对数据的高性能搜索。虽然 Web Storage 在存储较少量的数据很有用,但对于存储更大量的结构化数据来说力不从心。而 IndexedDB 提供了这种场景的解决方案。
通俗地说,IndexedDB 就是浏览器提供的本地数据库,它可以被网页脚本创建和操作。IndexedDB 允许储存大量数据,提供查找接口,还能建立索引。这些都是 LocalStorage 所不具备的。就数据库类型而言,IndexedDB 不属于关系型数据库(不支持 SQL 查询语句),更接近 NoSQL 数据库。
下表罗列出了几种常见的客户端存储方式的对比:
| 存储大小 | 失效时间 | |
|---|---|---|
| 会话期 Cookie | 4KB | 浏览器关闭自动清除 |
| 持久性 Cookie | 4KB | 设置过期时间,到期后清除 |
| SessionStorage | 2.5~10MB | 浏览器关闭后清除 |
| LocalStorage | 2.5~10MB | 永久保存(除非手动清除) |
| WebSQL | 已废弃 | 已废弃 |
| IndexedDB | >250MB | 手动更新或删除 |
IndexedDB 具有以下特点:
- 键值对储存:IndexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数据以“键值对”的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
- 异步:IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
- 支持事务:IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。这和 MySQL 等数据库的事务类似。
- 同源限制:IndexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
- 储存空间大:这是 IndexedDB 最显著的特点之一。IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
- 支持二进制储存:IndexedDB 不仅可以储存字符串,还可以储存二进制数据(
ArrayBuffer对象和Blob对象)。
IndexedDB 主要使用在于客户端需要存储大量的数据的场景下:
- 数据可视化等界面,大量数据,每次请求会消耗很大性能。
- 即时聊天工具,大量消息需要存在本地。
- 其它存储方式容量不满足时,使用 IndexedDB。
重要概念
IndexedDB 是一个比较复杂的 API,涉及不少概念。它把不同的实体,抽象成一个个对象接口。学习这个 API,就是学习它的各种对象接口。
- 数据库:
IDBDatabase对象 - 对象仓库:
IDBObjectStore对象 - 索引:
IDBIndex对象 - 事务:
IDBTransaction对象 - 操作请求:
IDBRequest对象 - 指针:
IDBCursor对象 - 主键集合:
IDBKeyRange对象
数据库
数据库是一系列相关数据的容器。每个 host(协议 + 域名 + 端口)都可以新建任意多个数据库。
IndexedDB 数据库有版本的概念。同一个时刻,只能有一个版本的数据库存在。如果要修改数据库结构(新增或删除表、索引或者主键),只能通过升级数据库版本完成。
对象仓库
每个数据库包含若干个对象仓库(object store)。它类似于关系型数据库的数据表。
数据记录
对象仓库保存的是数据记录。每条记录类似于关系型数据库的行,但是只有主键和数据体两部分。主键用来建立默认的索引,必须是不同的,否则会报错。主键可以是数据记录里面的一个属性,也可以指定为一个递增的整数编号。
数据体可以是任意数据类型,不限于对象。
索引
为了加速数据的检索,可以在对象仓库里面,为不同的属性建立索引。
在关系型数据库当中也有索引的概念,可以给对应的表字段添加索引,以便加快查找速率。在 IndexedDB 中同样有索引,可以在创建 store 的时候同时创建索引,在后续对 store 进行查询的时候即可通过索引来筛选。
给某个字段添加索引后,在后续插入数据的过程中,索引字段便不能为空。
事务
数据记录的读写和删改,都要通过事务完成。事务对象提供 error、abort 和 complete 三个事件,用来监听操作结果。
操作请求
indexedDB.open() 方法的返回值,可以设置 onsuccess(数据库打开成功)、onerror(数据库打开失败)、onupgradeneeded(数据库有更新:数据库创建、版本号更新、增删数据表) 等事件的回调函数
指针(游标)
游标是 IndexedDB 数据库新的概念,可以把游标想象为一个指针,比如我们要查询满足某一条件的所有数据时,就需要用到游标,我们让游标一行一行的往下走,游标走到的地方便会返回这一行数据,此时便可对此行数据进行判断,是否满足条件。
使用
想了解 IndexedDB 相关的更多 API,可以扩展阅读:MDN 文档、网道
由于 IndexedDB 所提供的原生 API 比较复杂,所以现在也出现了基于 IndexedDB 封装的库。例如 Dexie.js。
File API
介绍
HTML 的 input 表单控件,其 type 属性可以设置为 file,表示这是一个上传控件。
<input type="file" name="" multiple>现在又有了 HTML5 提供的 File API,该接口允许 JavaScript 读取本地文件,但并不能直接访问本地文件,而是要依赖于用户行为,比如用户在 type="file" 控件上选择了某个文件或者用户将文件拖拽到浏览器上。
File API 提供了以下几个接口来访问本地文件系统:
File:单个文件,提供了诸如name、size、type等只读文件属性FileList:一个类数组File对象集合FileReader:异步读取文件的接口Blob:文件对象的二进制原始数据
File
File 对象代表一个文件,用来读写文件信息。它继承了 Blob 对象,或者说是一种特殊的 Blob 对象,所有可以使用 Blob 对象的场合都可以使用它。
最常见的使用场合是表单的文件上传控件(<input type="file">),用户选中文件以后,浏览器就会生成一个数组,里面是每一个用户选中的文件,它们都是 File 实例对象。
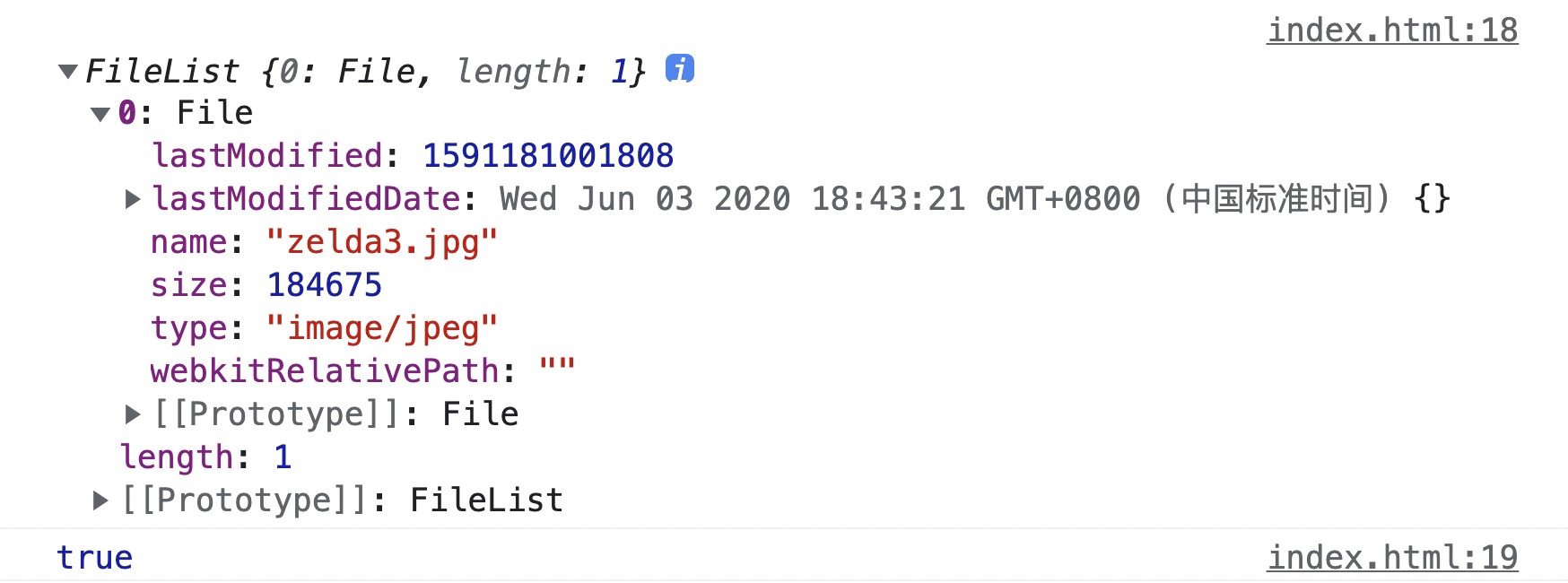
<input type="file" name="" id="file">const file = document.getElementById('file');
file.onchange = function(event) {
const files = event.target.files;
console.log(files); // FileList
console.log(files[0] instanceof File); // true
}
构造函数
浏览器原生提供一个 File() 构造函数,用来生成 File 实例对象。
new File(array, name [, options])File() 构造函数接受三个参数:
array:可以是二进制对象或字符串,表示文件的内容。name:字符串,表示文件名或文件路径。options:配置对象,设置实例的属性。该参数可选。type:字符串,表示实例对象的 MIME 类型,默认为空字符串。lastModified:时间戳,表示上次修改的时间,默认为Date.now()。
实例属性和实例方法
File 对象有以下实例属性:
lastModified:最后修改时间,时间戳字符串lastModifiedDate:最后修改时间,Date对象name:文件名或文件路径size:文件大小,单位是字节(Byte)type:文件的 MIME 类型
File 继承了 Blob,因此可以使用 Blob 的实例方法,如:slice()。
FileList
FileList 对象是一个类数组对象,代表一组选中的文件,每个成员都是一个 File 实例。
在 上面的那个示例 中,我们就可以看到触发 change 事件后,event.target.files 拿到的就是一个 FileList 实例对象。
它主要出现在两个场合:
- 文件控件节点(
<input type="file">)的files属性,返回一个FileList实例。 - 拖拽一组文件时,目标区的
DataTransfer.files属性,返回一个FileList实例。
FileList 的实例属性主要是 length,表示包含多少个文件。
FileList 的实例方法主要是 item(),用来返回指定位置的实例。它接受一个整数作为参数,表示位置的序号(从零开始)。
但是,由于 FileList 的实例是一个类数组对象,可以直接用方括号运算符,即 myFileList[0] 等同于 myFileList.item(0),所以一般用不到 item() 方法。
FileReader
FileReader 用于读取 File 对象或 Blob 对象所包含的文件内容。
浏览器原生提供一个 FileReader 构造函数,用来生成 FileReader 实例。
const reader = new FileReader();实例属性
error:读取文件时产生的错误对象readyState:整数,表示读取文件时的当前状态,一共有三种可能的状态0:尚未加载任何数据1:数据正在加载2:数据加载完成
result:读取完成后的文件内容,可能是字符串,也可能是一个ArrayBuffer实例。onabort:abort事件(用户终止读取操作)的监听函数。onerror:error事件(读取错误)的监听函数。onload:load事件(读取操作完成)的监听函数,通常在这个函数里面使用result属性,拿到文件内容。onloadstart:loadstart事件(读取操作开始)的监听函数。onloadend:loadend事件(读取操作结束)的监听函数。onprogress:progress事件(读取操作进行中)的监听函数。
实例方法
abort():终止读取操作,readyState属性将变成2。readAsArrayBuffer():以ArrayBuffer的格式读取文件,读取完成后result属性将返回一个ArrayBuffer实例。readAsBinaryString():读取完成后,result属性将返回原始的二进制字符串。readAsDataURL():读取完成后,result属性将返回一个 Data URL 格式(Base64 编码)的字符串,代表文件内容。- 对于图片文件,这个字符串可以用于
<img>元素的src属性。 - 注意,这个字符串不能直接进行
Base64解码,必须把前缀data:*/*;base64,从字符串里删除以后,再进行解码。
- 对于图片文件,这个字符串可以用于
readAsText():读取完成后,result属性将返回文件内容的文本字符串。该方法的第一个参数是代表文件的Blob实例,第二个参数是可选的,表示文本编码,默认为 UTF-8。
File System Access API
看上去上面的 File API 还不错,能够读取到本地的文件,但是它和离线存储有啥关系?
我们要的是离线存储功能,能够将数据存储到本地。
确实 File API 只能够做读取的工作,但是有一套新的 API 规范又推出来了,叫做 File System Access API。
是的,这是两套规范,千万没弄混淆了。
- File API 规范:https://w3c.github.io/FileAPI/
- File System Access API 规范:https://wicg.github.io/file-system-access/
关于 File System Access API,这套方案应该是未来的主角。它提供了比较稳妥的本地文件交互模式,即保证了实用价值,又保障了用户的数据安全。
这个 API 对前端来说意义不小。有了这个功能,Web 可以提供更完整的功能链路,从打开、到编辑、到保存,一套到底。不过遗憾的是目前兼容性较差。

目前针对该 API 的相关资料比较少,如果对该 API 感兴趣,下面给出两个扩展阅读资料: