文件下载
消息格式
服务器只要在响应头中加入 Content-Disposition: attachment; filename="xxx" 即可触发浏览器的下载功能
其中:
attachment表示附件,浏览器看到此字段,触发下载行为(不同的浏览器下载行为有所区别)filename="xxx"告诉浏览器,保存文件时使用的默认文件名
这部分操作是由服务器完成的,和前端开发无关,前端还可以使用 <a href="地址" download="文件名">下载</a> 启用强制下载
迅雷下载
用户可能安装了某些下载工具,这些下载工具在安装时,都会自动安装相应的浏览器插件,或者在电脑注册协议(Windows 是注册表,类 Unix 系统是写入指定文件),只要对下载地址稍作修改,就会启用对应的软件进行下载。
比如,迅雷的下载地址规则为:
thunder://base64(AA地址ZZ)断点续传
若要实现下载时的断点续传,首先,服务器在响应时,要在头中加入下面的字段:
Accept-Ranges: bytes这个字段是向客户端表明:我这个文件可以支持传输部分数据,你只需要告诉我你需要的是哪一部分的数据即可,单位是字节
此时,某些支持断点续传的客户端(比如迅雷)就可以在请求时,告诉服务器需要的数据范围。具体做法是在请求头中加入下面的字段:
range: bytes=0-5000客户端告诉服务器:请给我传递 0-5000 字节范围内的数据即可,无须传输全部数据
完整流程如下:

文件上传
消息格式
文件上传的本质仍然是一个数据提交,无非就是数据量大一些而已
在实践中,人们逐渐的形成了一种共识,文件上传一般使用 multipart/form-data 的请求格式:
POST 上传地址 HTTP/1.1
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW
... # 其他请求头
----WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="avatar"; filename="小仙女.jpg"
Content-Type: image/jpeg
(文件二进制数据)
----WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="username"
admin
----WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="password"
123123
----WebKitFormBoundary7MA4YWxkTrZu0gW- 文件上传一般使用 POST 请求
content-type: multipart/form-data,浏览器会自动分配一个定界符boundary- 请求体的格式是一个被定界符
boundary分割的消息,每个分割区域本质就是一个键值对 - 除了键值对外,
multipart/form-data允许添加其他额外信息,比如文件数据区域,一般会把文件在本地的名称和文件 MIME 类型告诉服务器
除了 multipart/form-data 格式,还可以将文件二进制数据进行 *Base64 编码后,得到字符串进行传输。
断点续传
整体来说,实现断点上传的主要思路就是把要上传的文件切分为多个小的数据块然后进行上传。
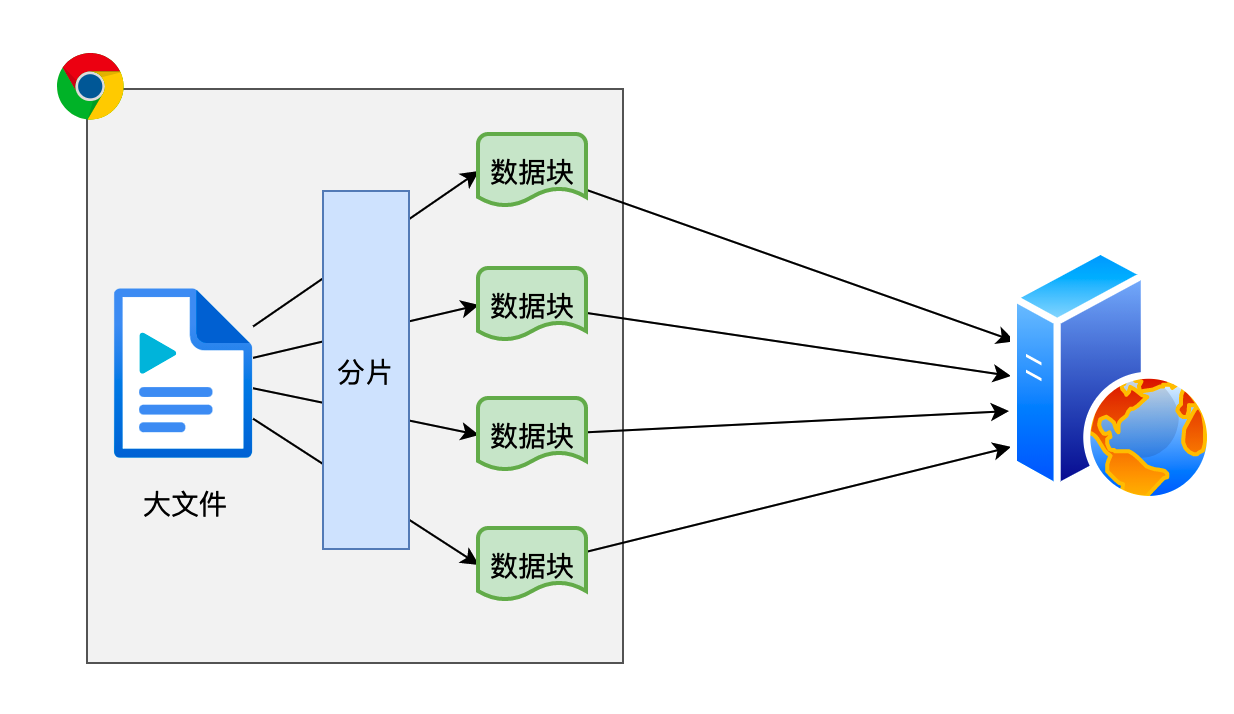
虽然分片上传的整体思路一致,但它没有一个统一的、具体的标准,因此需要根据具体的业务场景制定自己的标准。
由于标准的不同,这也就意味着分片上传需要自行编写代码实现。
下面用一种极其简易的流程实现分片上传:

/**
* 文件分片
* @param {File} file
* @returns
*/
async function splitFile(file) {
return new Promise((resolve) => {
// 分片尺寸(1M)
const chunkSize = 1024 * 1024;
// 分片数量
const chunkCount = Math.ceil(file.size / chunkSize);
// 当前 chunk 的下标
let chunkIndex = 0;
// 使用 ArrayBuffer 完成文件 MD5 编码
const spark = new SparkMD5.ArrayBuffer();
const fileReader = new FileReader(); // 文件读取器
const chunks = []; // 分片信息数组
// 读取一个分片后的回调
fileReader.onload = function (e) {
spark.append(e.target.result); // 分片数据追加到 MD5 编码器中
// 当前分片单独的 MD5
const chunkMD5 = SparkMD5.ArrayBuffer.hash(e.target.result) + chunkIndex;
chunkIndex++;
chunks.push({
id: chunkMD5,
content: new Blob([e.target.result]),
});
if (chunkIndex < chunkCount) {
loadNext(); // 继续读取下一个分片
} else {
// 读取完成
const fileId = spark.end();
resolve({
fileId,
ext: extname(file.name),
chunks,
});
}
};
// 读取下一个分片
function loadNext() {
const start = chunkIndex * chunkSize,
end = start + chunkSize >= file.size ? file.size : start + chunkSize;
fileReader.readAsArrayBuffer(file.slice(start, end));
}
/**
* 获取文件的后缀名
* @param {string} filename 文件完整名称
*/
function extname(filename) {
const i = filename.lastIndexOf('.');
if (i < 0) {
return '';
}
return filename.substr(i);
}
loadNext();
});
}