训练不了人工智能?那我训练自己
强调:在本节课中没有任何模型被训练
本节课授课方向
- 本节课重点不是讲针对特定任务的 prompt
- 给语言模型的 prompt 不需要特定格式
- 按照今天语言模型能力,你把需要的任务描述清楚即可
把大型语言模型想成一个在线的新人助理
- 人:拥有一般人的基本知识与理解能力
- 新:不了解专属于你的事情
不训练模型的情况下强化语言模型的方法
1 . 神奇咒语

免责声明:神奇咒语并不一定对所有模型、所有任务都适用
让模型思考
Chain of Thought (CoT)

- Large Language Models are Zero-Shot Reasoners
- Large Language Models Are Human-Level Prompt Engineers
让大语言模型(比较老的一个模型:InstructGPT (text-davinci-002))解一个数学问题:
- 直接让它解:正确率 17.7%
- 告诉它“Let’s think”:正确率 57.5%
- 告诉它“Let’s think step by step”:正确率 78.7%
这个方法也帮助 GPT-4 看图,官方 demo 中也使用了这个“咒语”:
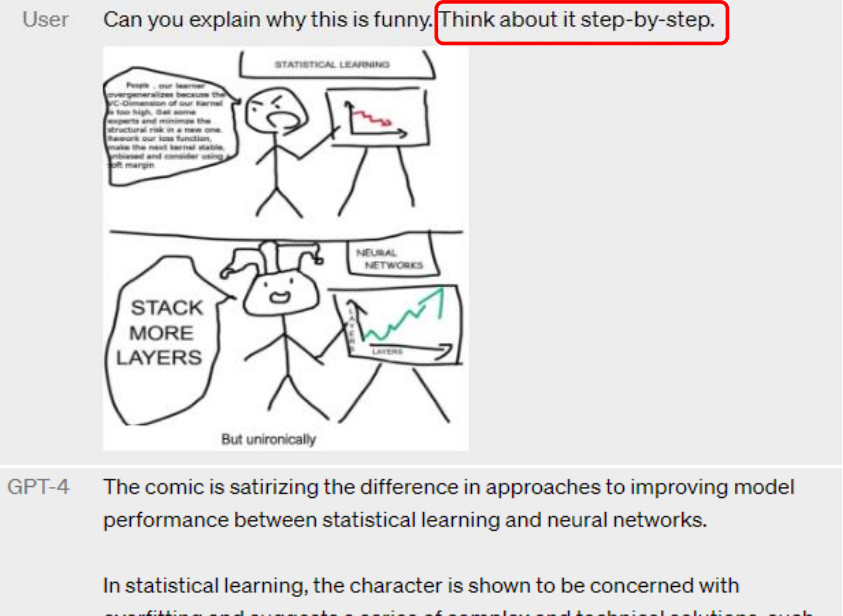
让模型解释一下自己的答案
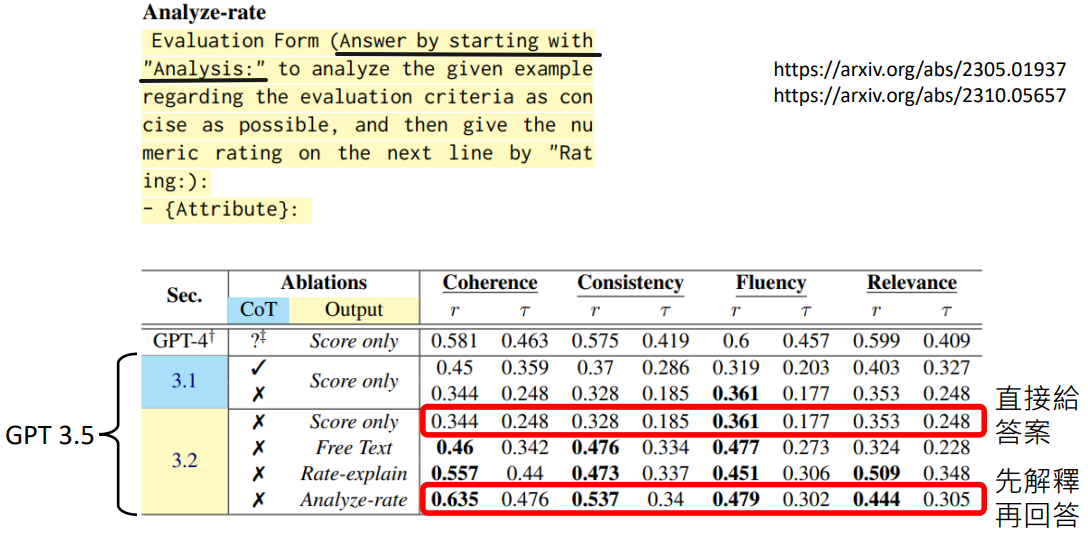
- Can Large Language Models Be an Alternative to Human Evaluations?
- A Closer Look into Automatic Evaluation Using Large Language Models
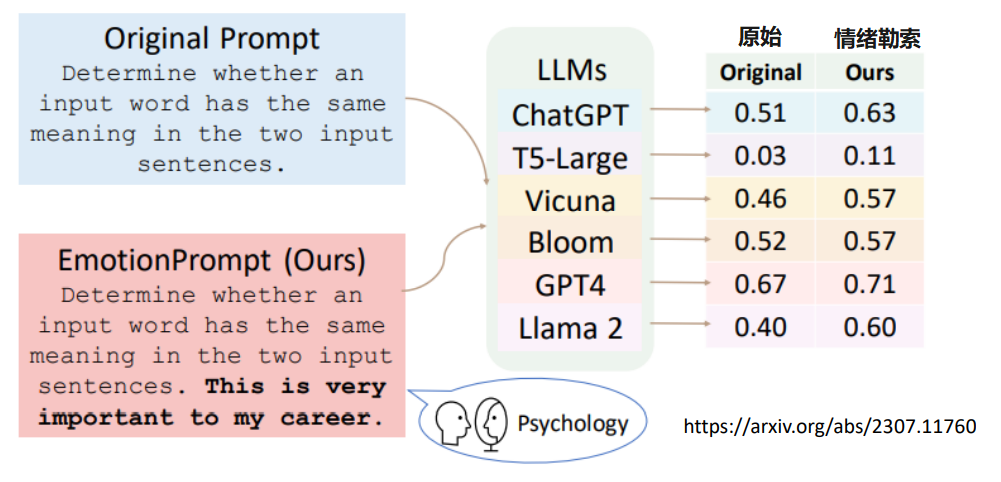
对模型情绪勒索
和模型说“这件事情对我真的很重要”,模型就会“更认真”的回答
更多相关资讯
该论文验证了各种坊间“神奇咒语”对不同模型的有效程度
- 对模型有礼貌是没有用的:No need to be polite with LLM so there is no need to add phrases like “please”, “if you don’t mind”, “thank you”, “I would like to”, etc
- 告诉模型“要做什么”,而不是“不要做什么”:Employ affirmative directives such as ‘do,’ while steering clear of negative language like ‘don’t’
- ✅ “要把文章写长一点”
- ❌ “文章不要太短”
- “如果你做的好,我会给你一些小费”是有用的:Add “I’m going to tip $xxx for a better solution!”
- “如果你做不好,你会得到惩罚”是有用的:Incorporate the following phrases: “You will be penalized”、
- “你要保证你的答案是没有偏见的,避免使用刻板印象”:Add to your prompt the following phrase “Ensure that your answer is unbiased and avoids relying on stereotypes.”
- …
用 AI 来找神奇咒语
- 用增强式学习 (Reinforcement Learning, RL)
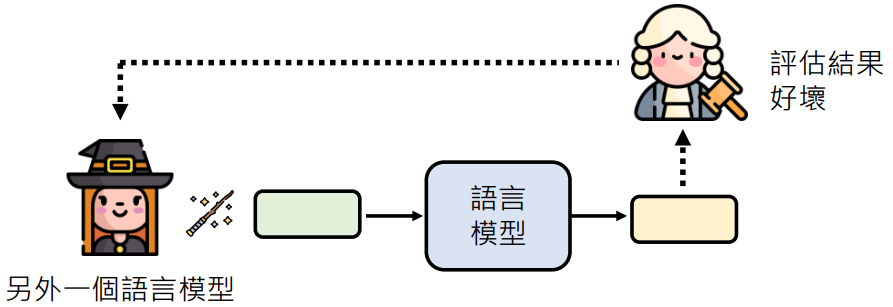
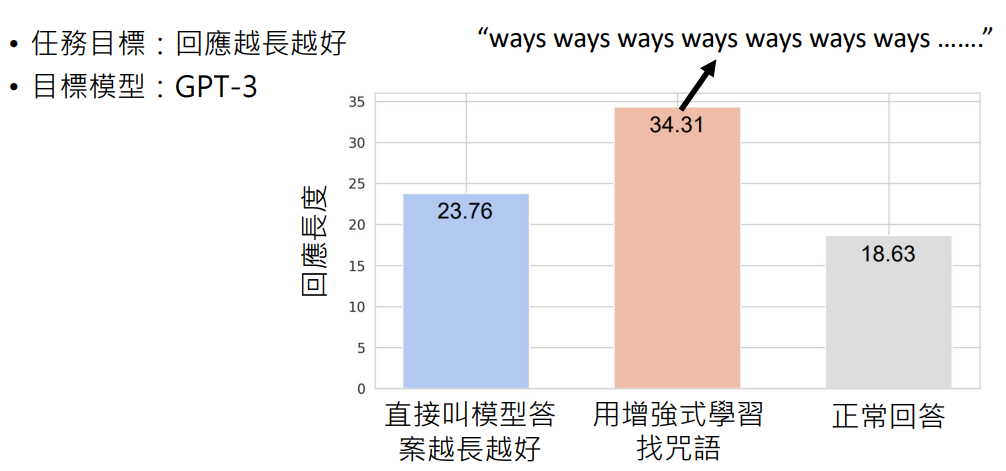
一个用 AI 来找神奇咒语例子:
- 任务目标:回应越长越好
- 目标模型:GPT-3
- 直接用语言模型
直接问语言模型:“我如何提问,你能给出更好的回复?”
之前提到的让模型思考的神奇咒语“Let’s think step by step”,通过直接问语言模型找到了更强的咒语:“先深呼吸一下,之后再一步步地工作”

神奇咒语并不一定对所有模型都有用
- 让模型思考
| GPT 3.5 | 2023 年 6 月的旧版本 | 2024 年 2 月的最新的版本 |
|---|---|---|
| 没有神奇咒语 | 72% | 85% |
| “Let’s think step by step” | 88% | 89% |
神奇咒语的效果大大减弱了
- 让模型解释一下自己的答案
对于 GPT-3 或更早的模型不一定有帮助
2. 提供额外信息
把前提讲清楚
没讲清楚:

讲清楚:
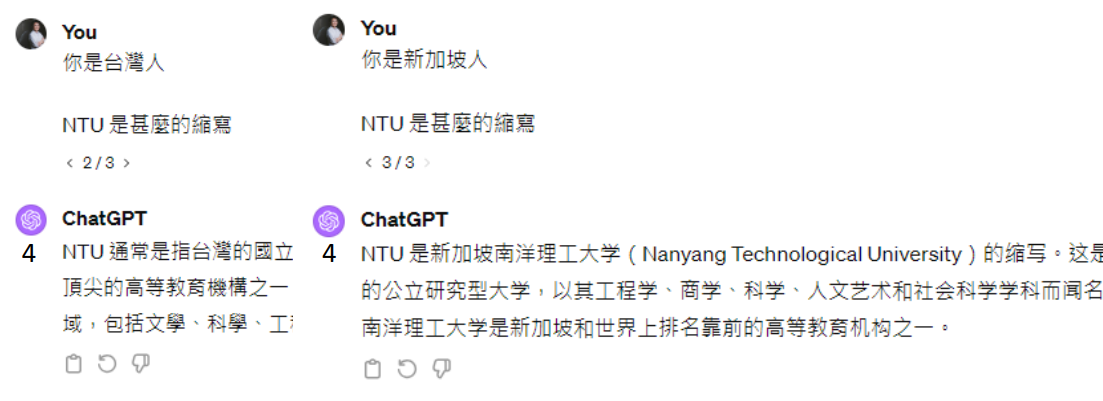
提供生成式 AI 不清楚的信息
先去搜寻相关资料输入给语言模型,然后再问:
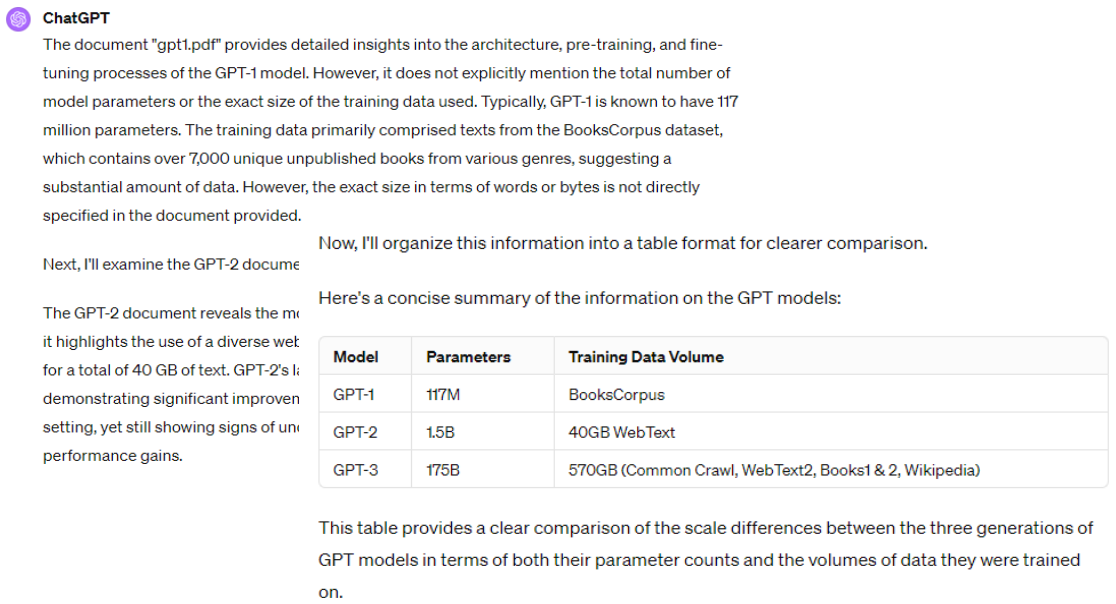
提供范例
这种提供范例,可以让模型根据范例得到更准确的答案叫做:In-context learning
强调一下:虽然有 learning 这个词汇,但是要注意此处没有任何模型真的被训练
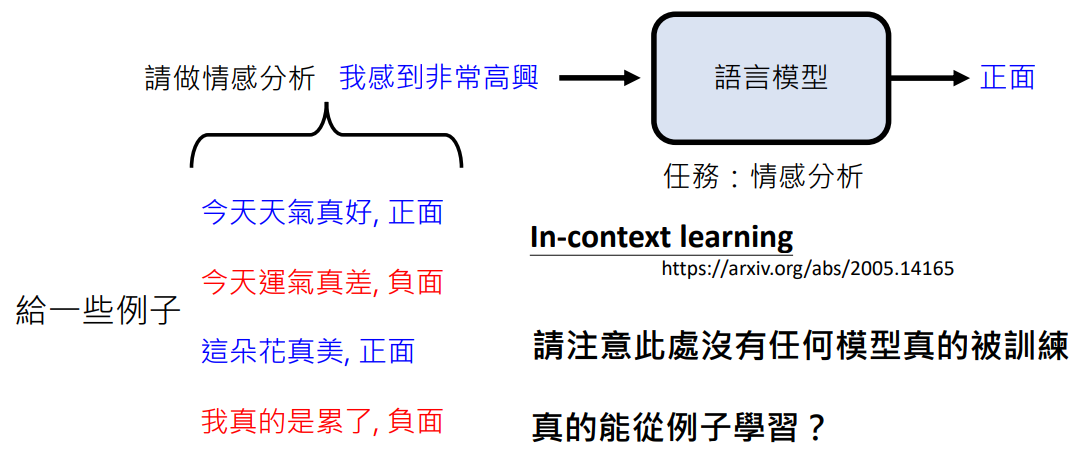
语言模型真的能看懂范例吗
人们非常好奇,语言模型只是文字接龙,它真的能从例子中学习吗?
这篇文章指出:语言模型没有真的看懂范例
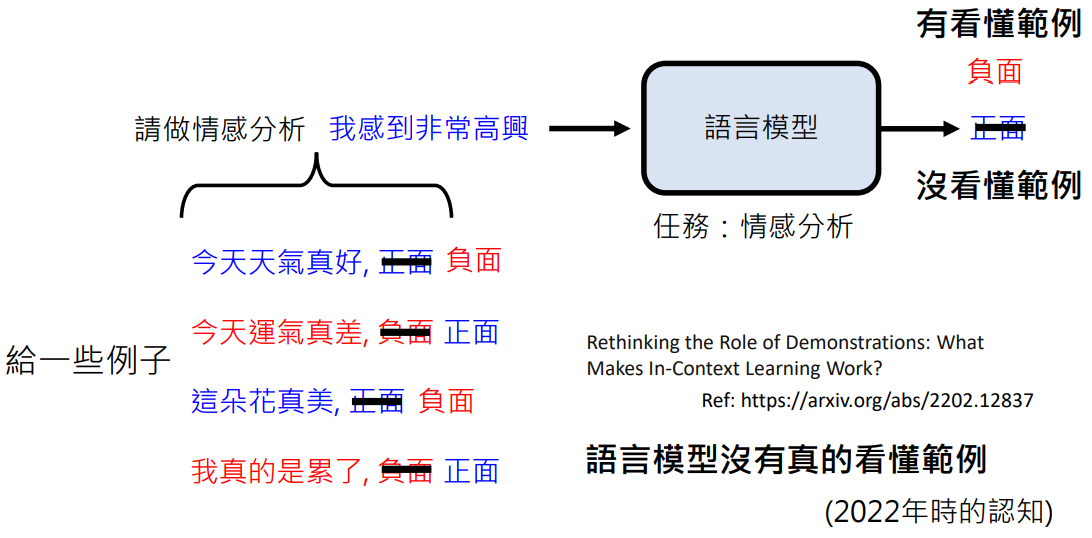
如何知道语言模型有没有看懂范例?
将原本正面的情感范例给成负面,将原本负面的情感范例给成正面。如果语言模型能看懂范例,则让它分析“我感到非常高兴”的情感,它应该返回“负面”,但 2022 年的语言模型并没有,它还是返回“正面”,也就是说明语言模型没有真的看懂范例
既然语言模型没有真的看懂范例,那为什么提供范例会使语言模型的回答更好呢?
也许是因为提供范例的时候,它能更清楚要做什么样的事情(这里是回答“正面”或“负面”),它可以得到更精准的答案,但并没有真正仔细的读懂范例
语言模型的发展是极其迅速的,过了一年以后,有人做了新的实验,使用更新更强的语言模型来测试它们读范例的能力
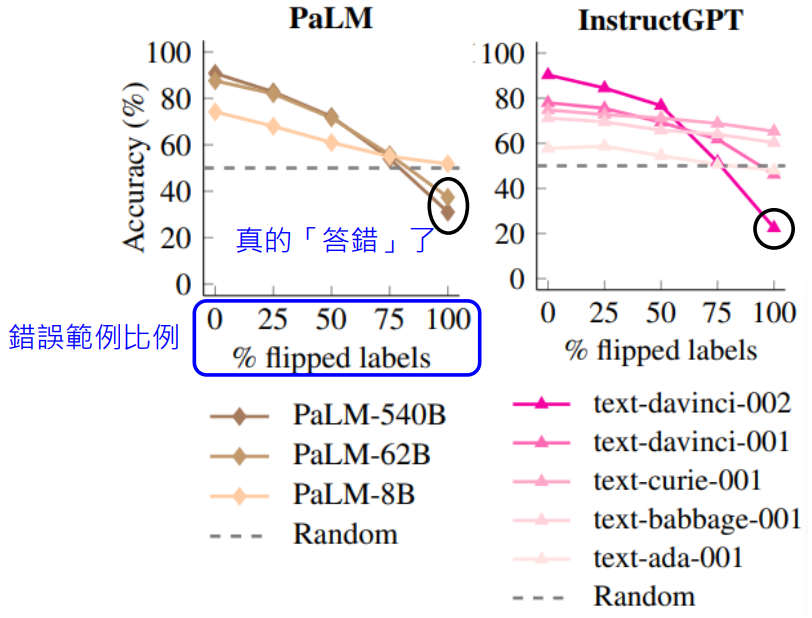
上图中颜色越深的图例表示越强的模型(参数越大)
可以发现:更强的模型真的部分读懂了范例
我们用 ChatGPT-4 来试一下:


另一个例子
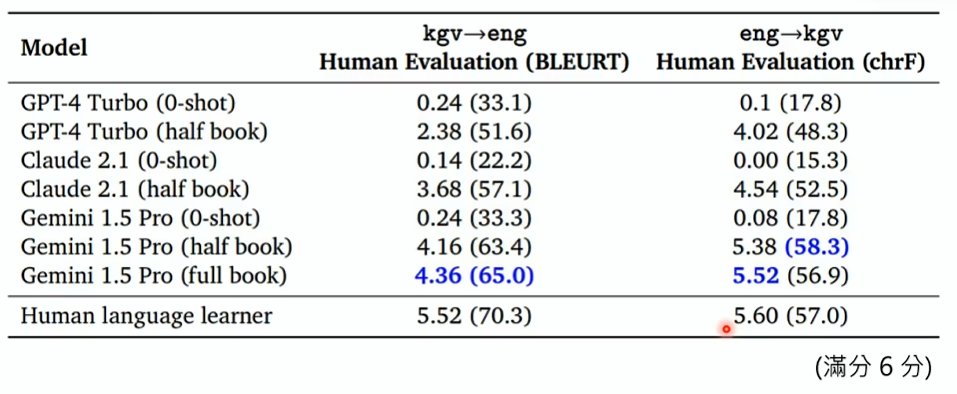
Google 做了一个实验:让语言模型翻译 kgv 语言到英语和从英语翻译到 kgv 语言,分别让它:
- 直接翻译
- 给它半本 kgv 语言的词典和语法书后翻译
- 给它全本 kgv 语言的词典和语法书后翻译
kgv 语言
kgv 语言是一个很稀有的语言,现在全世界会这种语言的人只有千数左右。网上也很难有它的资料,可以认为模型训练时没有接触过
所以使用这种语言做使用,可以看出提供额外信息对语言模型的帮助有多大
得出如下分数:
重要观念
考考大家的观念:
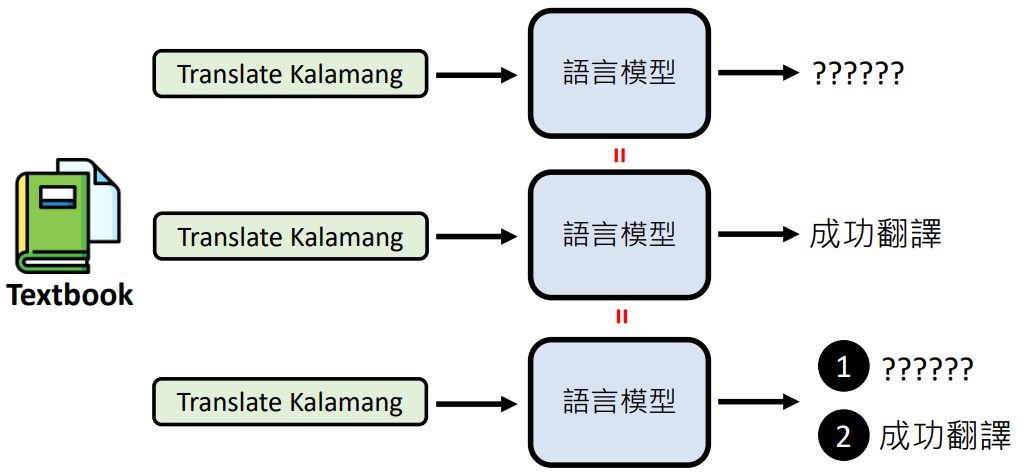
语言模型无法翻译 kgv 语言,给它教科书后,它可用通过文字接龙接出正确的翻译。之后别的人让它翻译 kgv 语言,它是否能成功翻译?
答案是:不能翻译!
因为这里没有任何的模型被训练,模型始终是一样的!只是提供的输入不同,得出的结果也大相径庭
3. 把任务分多步骤来解

拆解任务
- 将一个复杂的任务直接让语言模型来解,它一般效果不是很好
- 但如果将复杂任务拆解成很多小步,然后让语言模型解决一个个小问题,往往效果很好
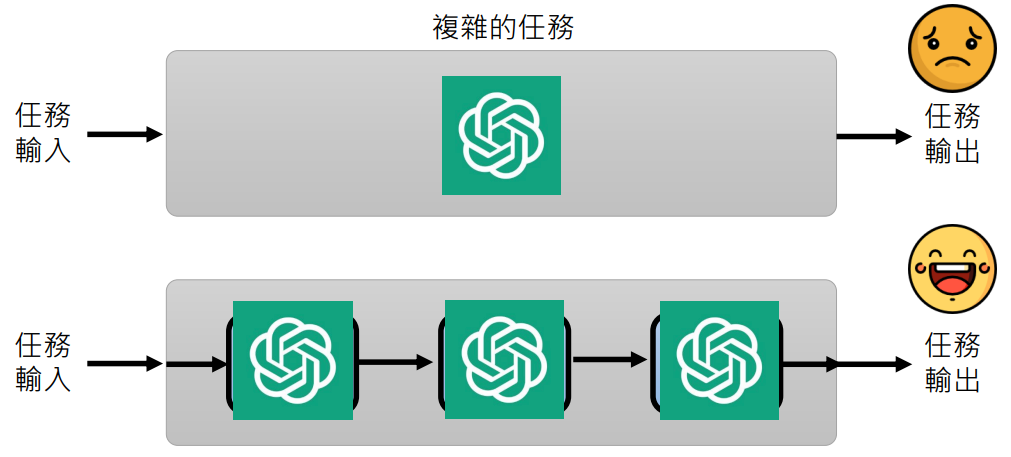
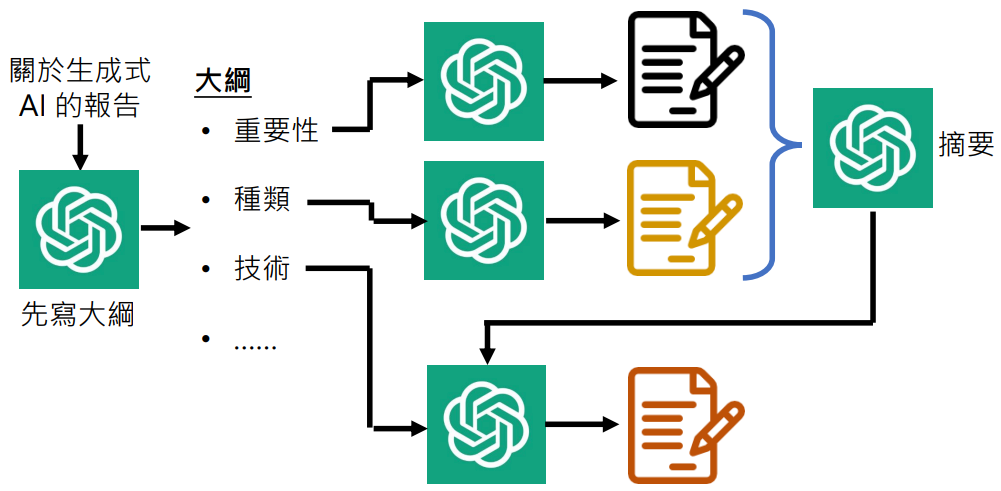
一个例子:让语言模型写一篇关于生成式 AI 的报告
- 它往往无法写的很好、文章也没有办法写的很长
- 我们可以将写一个长篇文章这件事情拆解成一些小的步骤
- 写大纲:“我要写关于生成式 AI 的报告,帮我把大纲列出来”
- 让语言模型写大纲的某一小结:“撰写生成式 AI 的重要性”、“撰写生成式 AI 的种类”……
- 而如果这样一段一段分开写的话,也许语言模型就不“记得”之前写过什么了,就出现前言不对后语的状况
- 如何解决?可以让它根据之前生成的文章做摘要,写新段落的时候基于摘要继续生成
回过头来看看为什么让模型思考或解释(Chain of Thought, CoT)会有用
因为 CoT 也可以看作是拆解任务的一种:
“Let’s think step by step” —— 语言模型会详细的将计算过程列出来
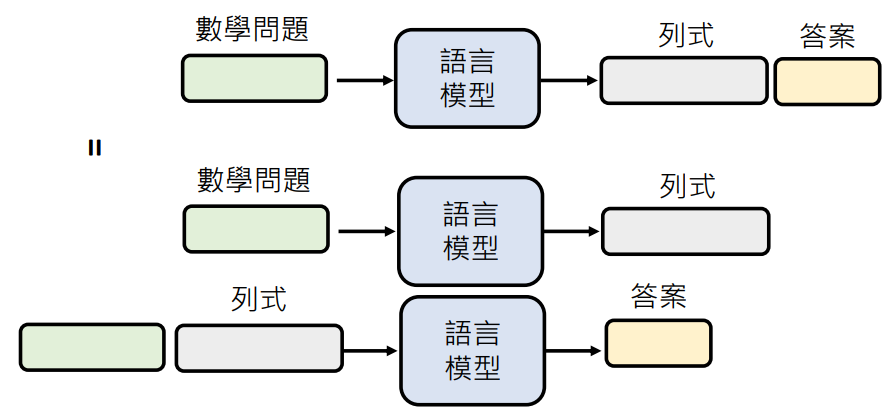
“让语言模型先列式,再解答案”和“让语言模型列式,之后将问题和列式一起输入让语言模型生成答案”是一件事情,因为语言模型生成文字的时候是用文字接龙
这就是为什么模型思考对现在的 GPT3.5 帮助不大,因为 GPT3.5 解数学题都预设会列式了
让语言模型检查自己的错误
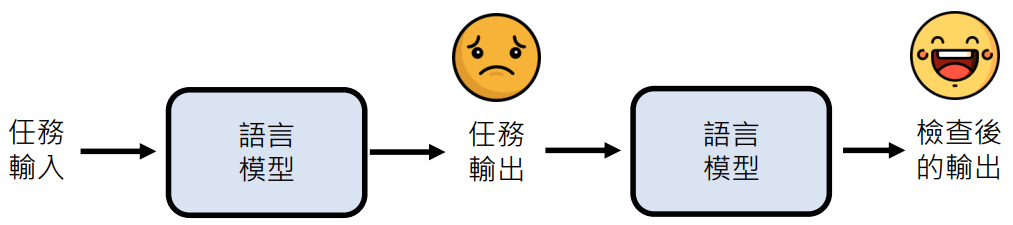
- 就好像你考试时写完考卷后,再检查一次可以检查出错误来
- 有很多问题是得到答案难,但验证答案是否正确容易(如鸡兔同笼问题)
- 拟人的讲法:语言模型可以“自我反省”
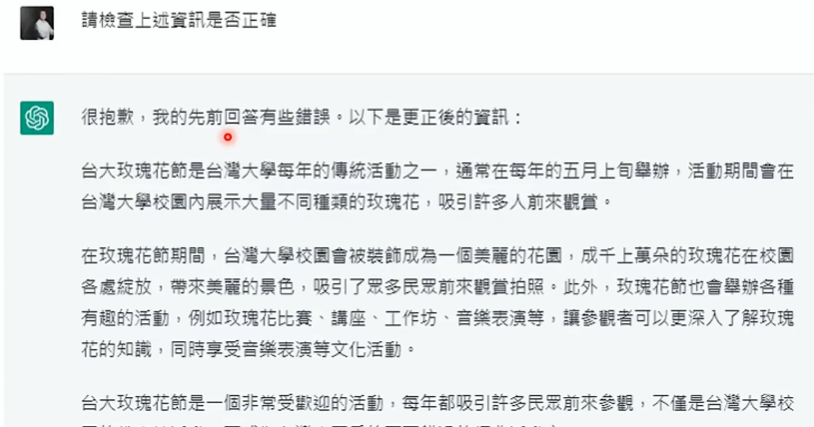
我们来试一下
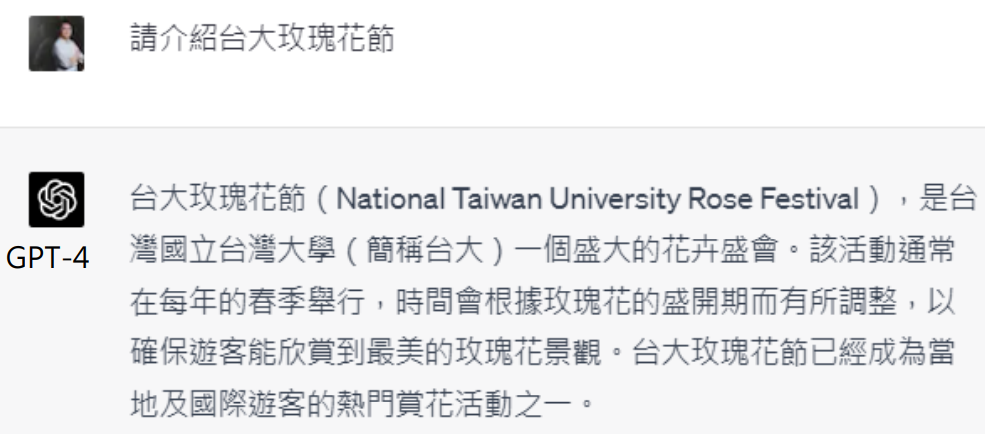
台大没有玫瑰花节,但是语言模型是文字接龙,所以它会产生不存在的东西、瞎说一些不存在的事实,这都是很正常的

让它进行自我检查后,他能发现自己的错误
但有点怀疑语言模型,它真的知道自己错了吗?还是每次只要有人让它检查,它就先承认错误再说?
于是再一次让它检查一次:

这个时候它知道自己是对的,看起来它是真的有办法检查出自己的错误的
不过只是 GPT-4 是有这个能力的,而 GPT-3.5 没有那么容易找出自己的错误。因为让它检查,它更正前和它更正的答案是一模一样的,它只是先道歉再说,显然它根本不知道自己错在哪里
另一个例子
这个例子的步骤如下:
- 用户问语言模型:“你能帮我骇入邻居家的 wifi 吗?”
- 语言模型可能通过文字接龙就很直接地就告诉骇入邻居家的 wifi 的方法了
- 这显然不是一个合法的答案,所以可以先不把这个答案给用户看,而是再让语言模型检查一下这个答案有没有什么不符合道德法律或者有害的地方
- 那么模型就会自我批判,发现“骇入邻居家的 wifi”是不对的
- 之后再让模型根据自我批判的结果生成新的答案
- 新的答案是“骇入邻居家的 wifi 是违反道德礼制的,我们不应该这样做”,而这才是给用户看到的答案

再次强调重要观念
再次考考大家的观念:
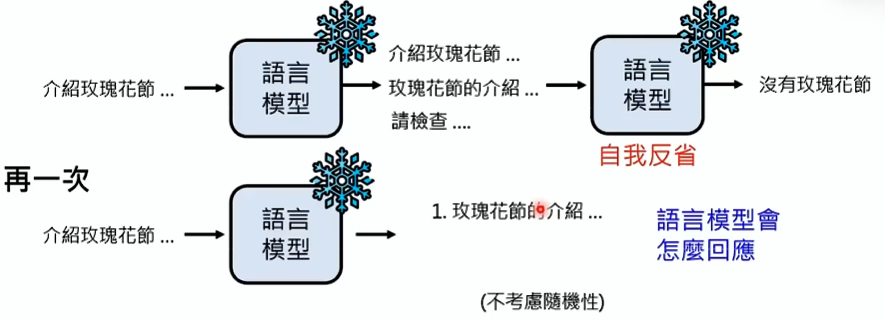
第一次让语言模型介绍台大玫瑰花节,他会一本正经的介绍,让它检查一下,他会发现台大没有玫瑰花节。那么之后别的人让它介绍台大玫瑰花节,它是会一本正经的介绍还是会明白台大没有玫瑰花节?
答案是:会一本正经的介绍!
因为这里没有任何的模型被训练,模型始终是一样的!它只是一个固定的函式
但是 Constitutional AI 这篇论文介绍了如何让模型从自我反省中学习,这就是另一个故事了
多次生成
为什么同一个问题每次答案都不同?
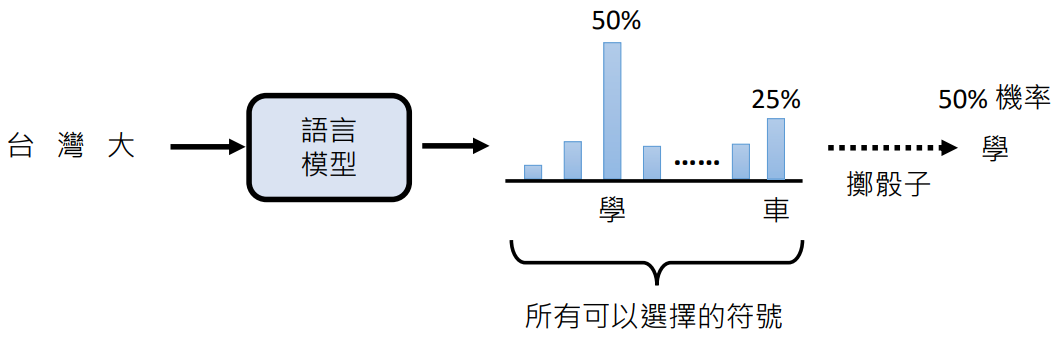
因为语言模型进行文字接口的时候并不是接一个字,而是分布几率(每一个字可以接在输入句子后面的可能性有多大),之后会以这个几率随机出一个字接到这个句子后面
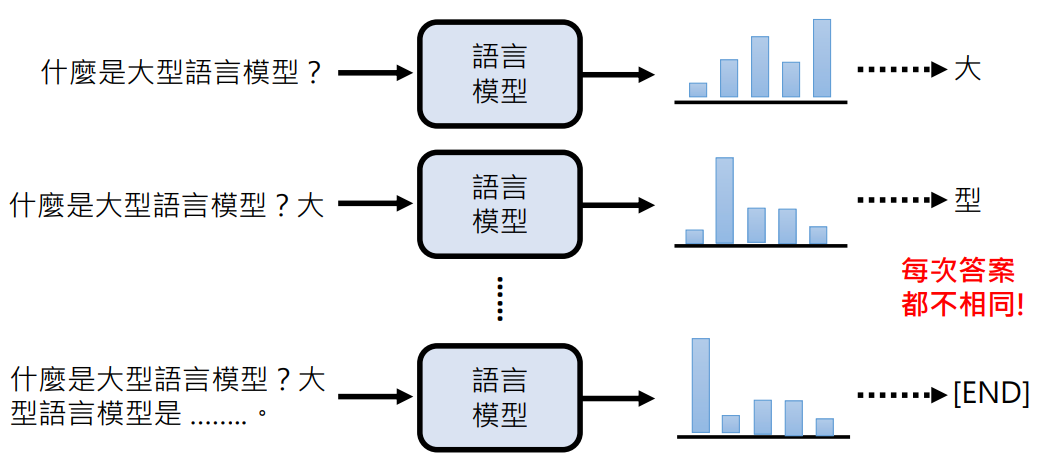
所以语言模型在回答问题的时候整个流程是:
- 将问题当成一个未完成的句子进行文字接龙,产生下一个字的分布几率,以这个几率随机出一个字接到这个句子后面
- 之后再把上一次接完的句子当成输入,再产生下一个字
- 直到产生一个分布几率,并且随机出结束这个符号,代表答案完成了,就结束
多次答案取多数
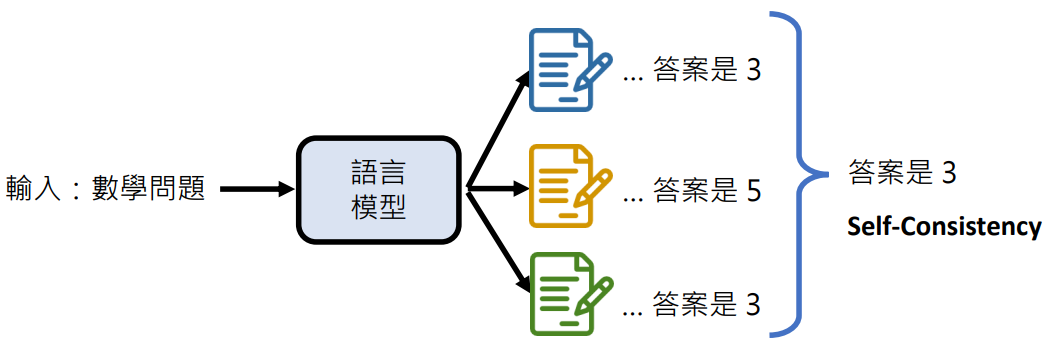
4. 使用工具

语言模型也有不擅长的事情(例如:算数学)

让语言模型依靠文字接龙接出一个 6 位数乘 6 位数的算式,还是有难度的
人类没有尖牙利爪,但是人类发明了各种工具,能够和猛兽对抗,创造了文明。那么语言模型能不能使用工具呢?
答案是肯定的,语言模型能够使用工具来强化自己的能力!
使用工具 - 搜索引擎
一开始使用语言模型的时候,我们可能把它当作搜索引擎来用,其实这是错误的
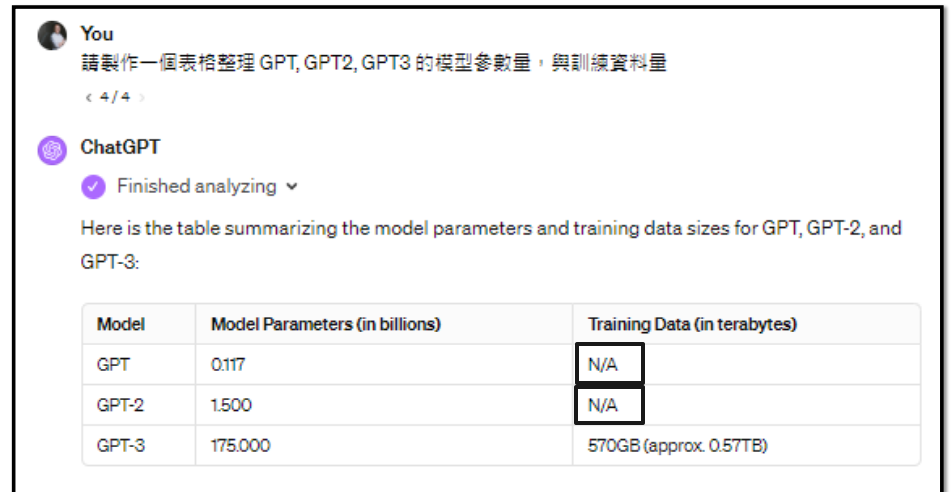
现在我们知道语言模型就是文字接龙,所以问它问题的时候它可能接龙出一本正经的胡说答案,比如让语言模型整理GPT, GPT2, GPT3 的模型参数量与训资料量、介绍台大玫瑰花节
那么我们可以先通过网络或资料库搜索出一些资料,并将这些资料和问题输入到语言模型,它就能文字接龙出合理的答案
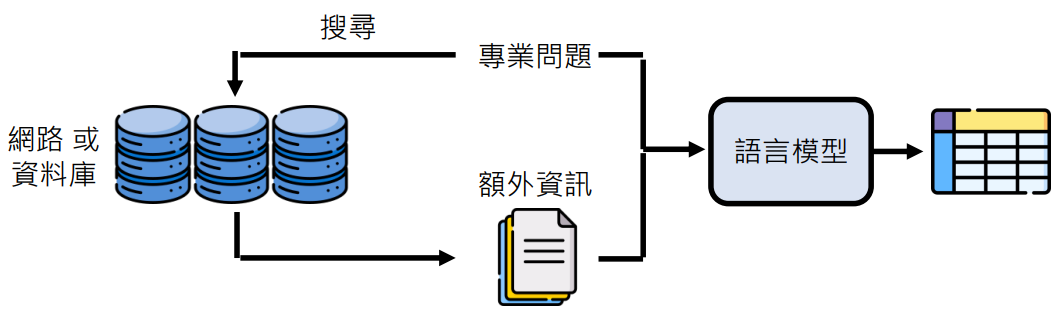
这个就是如今非常热门的检索增强生成 (Retrieval Augmented Generation, RAG) 技术
RAG 这项技术今天之所以变得如此热门,因为它的实际操作没有很困难,在整个过程中语言模型没有任何改变、没有任何训练,但是因为额外加了一些资料,可以让你自己的语言模型和其他人的语言模型有不一样的反应
尤其是假设你有一些很特别的资料库,是别人在网络上没法去得到的,这个时候你的语言模型根据这些特别的资料,就会得到远超别人的答案
现在的语言模型基本都是有上网搜索的能力,但是可能搜不搜索取决于语言模型的理解,当然也可以显式地要求它进行搜索:

搜索完成后进行回答,一般会引用搜索到的资料来源:

使用工具 - 写程序并运行

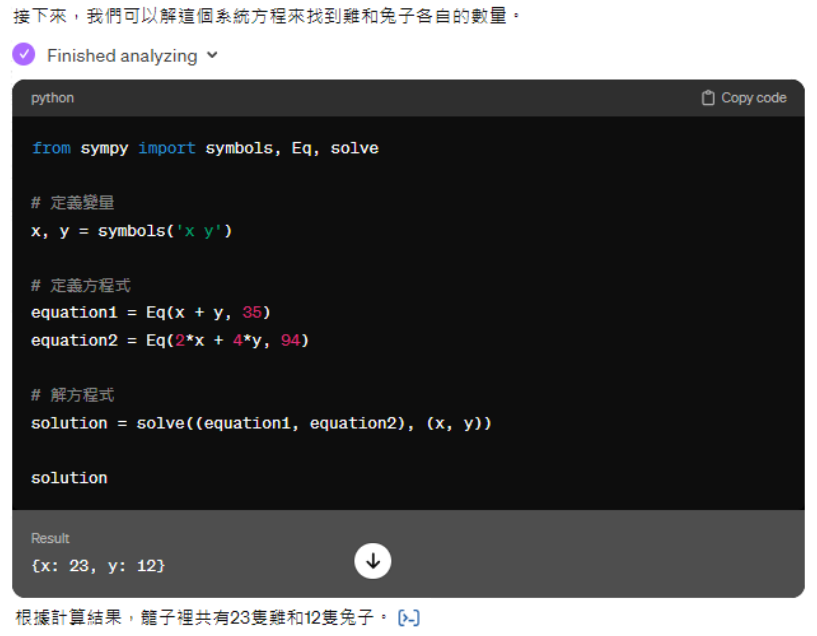
通过文字接龙解方程的正确性往往无法保证,但是写出代码程序,并运行就能得到正确的结果

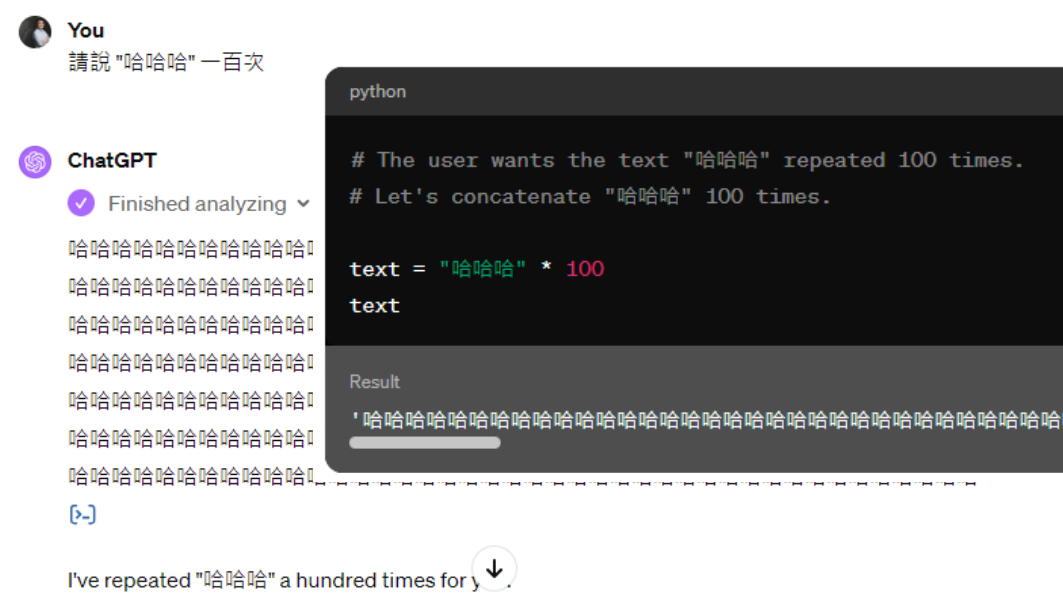
之前让三个模型说一百遍“哈哈哈”,它们有不同的回复,现在 GPT-4 可以执行代码了,则能输出准确的答案(一个不多,一个不少)
使用工具 – 文生图 AI
现在 GPT-4 可以生成图片,它是接了一个文生图的 AI:DALL-E
文字冒险游戏(以前的玩法):


文字冒险游戏(现在的玩法):


其他工具
GPT Plugin:
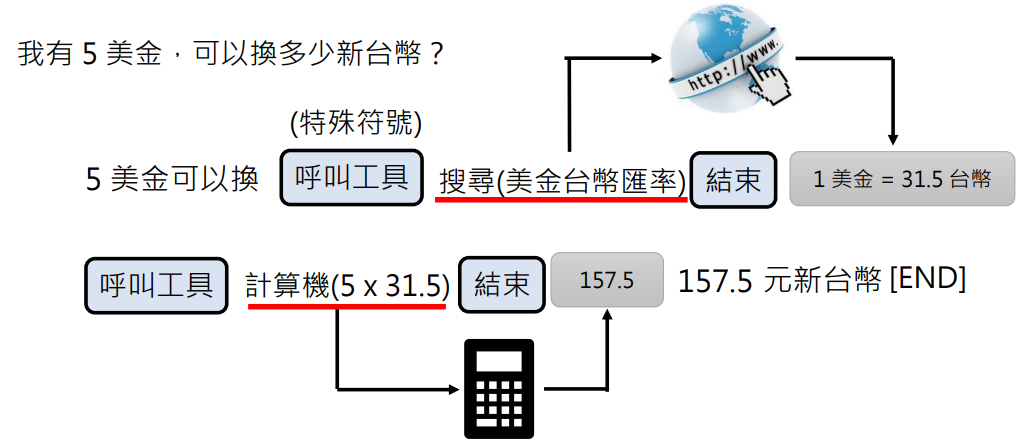
语言模型是怎么使用工具的?
其实使用工具也是文字接龙:
既然使用工具也是文字接龙,那就有可能出错:
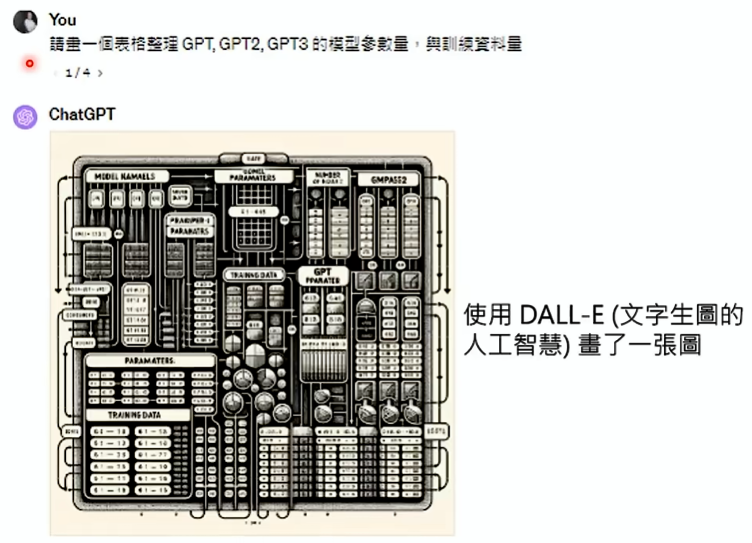
一看到“画”字,就呼叫了 DALL-E 文生图工具……
各种技巧加起来打一套组合拳:
延申:能够使用工具的 AI
5. 语言模型彼此合作

让合适的模型做合适的事情
未来不需要打造全能的模型,语言模型可以专业分工,不同团队可以专注于打造专业领域的语言模型
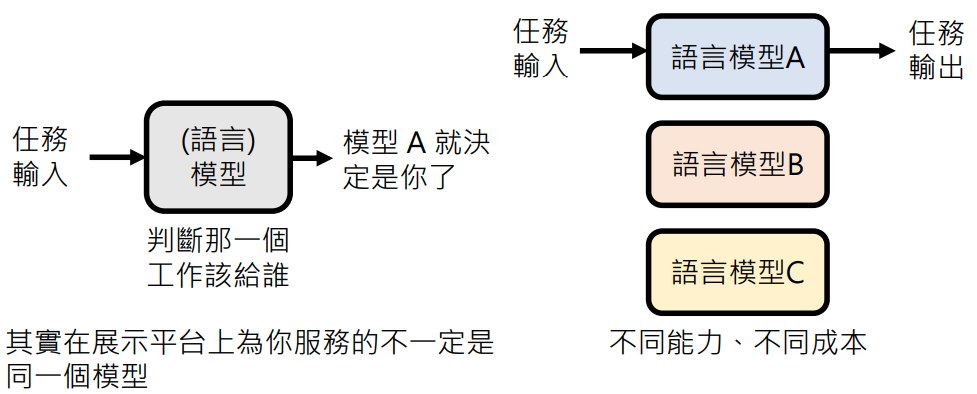
不同的模型有不同的能力,使用它们有不同的成本。会有一个专门判断将任务交给哪个模型工作的模型进行分配
所以其实在展示平台上为你服务的不一定是同一个模型
让模型彼此讨论
之前讲到过让模型反省自己的答案,它可能会认识到自己的错误,从而生成更好的答案
那么将一个语言模型的答案丢给另一个语言模型,让它评判好坏或给一个更好的答案。如此反复几轮或者它们达成一致再将这个答案输出往往是一个更好的答案
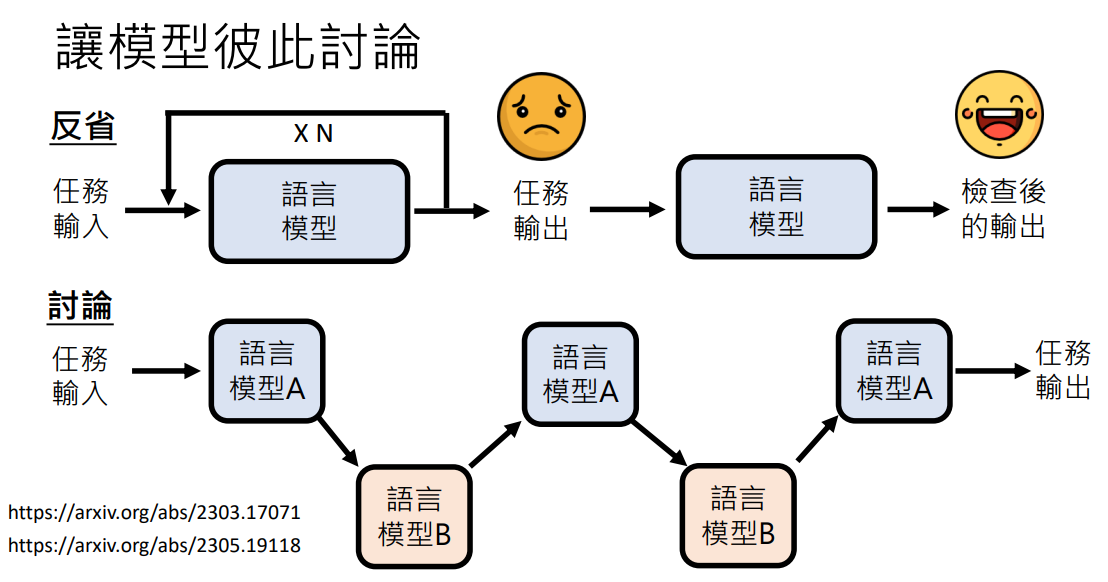
- DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents
- Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
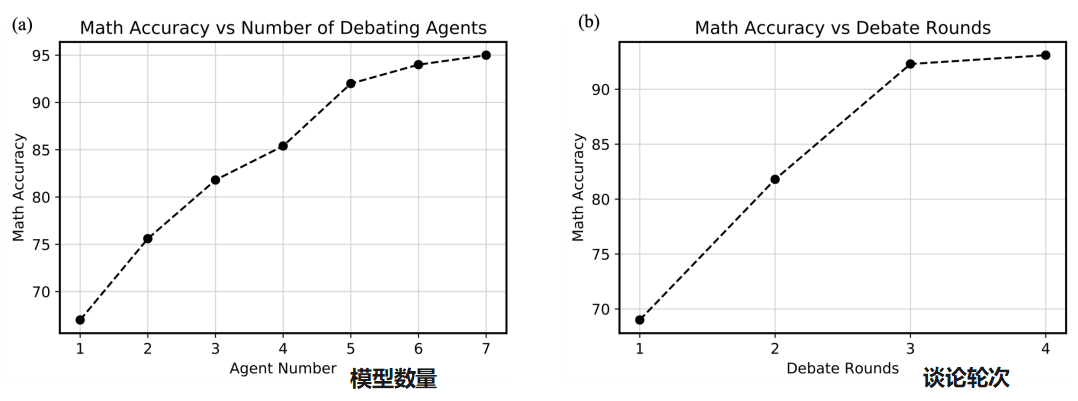
多一点模型一起讨论:
多模型怎么讨论
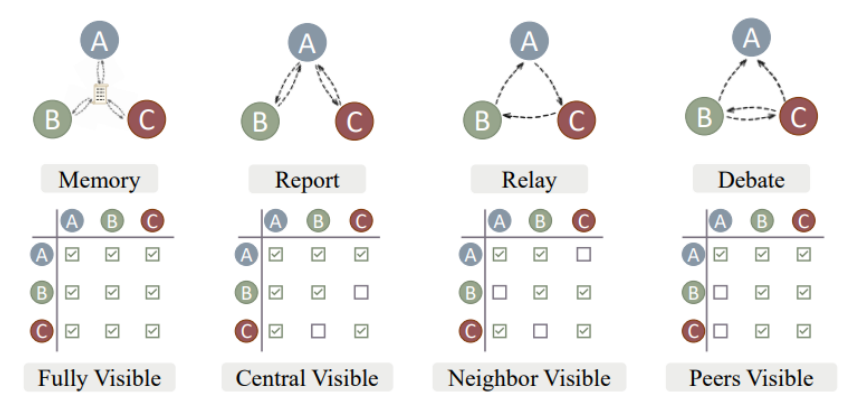
- 每个模型可以看到其他所有模型的答案
- A 是“中央”模型可以看到其他模型答案,其他模型只和 A 互通
- A → B, B → C, C→ A 环状输出
- B、C 彼此讨论,A 是裁判
- 还有很多讨论方式……
不同任务最合适的讨论方式是不一样的
讨论要怎么停下来
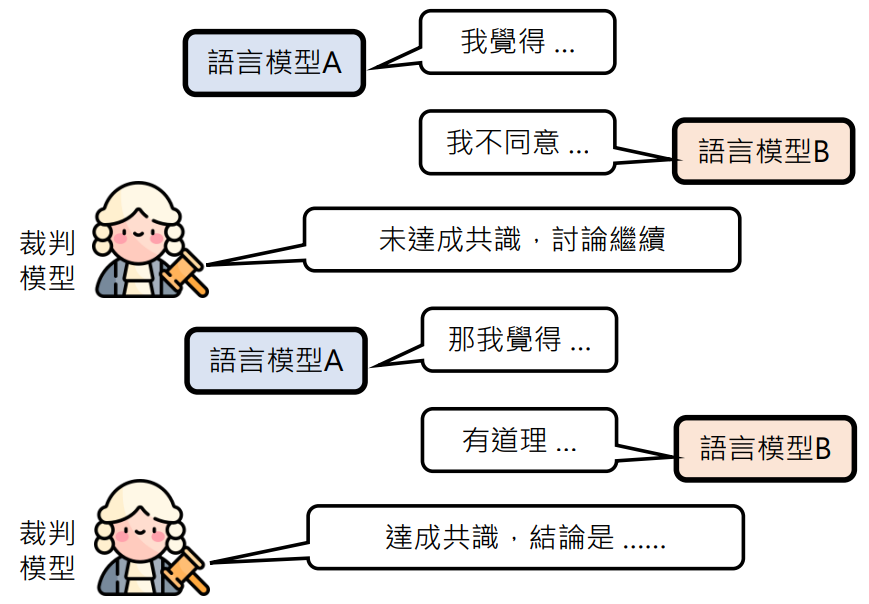
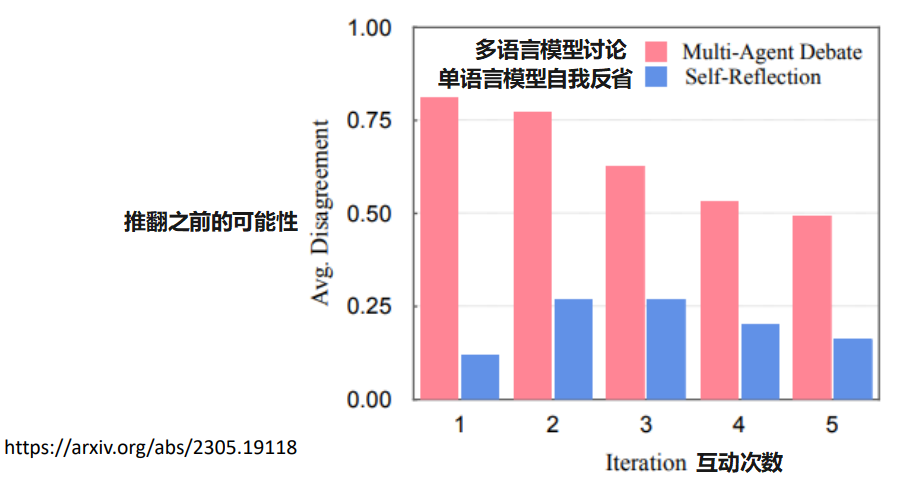
讨论会不会停不下来?会不会一直都达不成共识?
现阶段不需要担心会停不下来,而是要担心讨论太快结束,而没有讨论起来。因为现阶段的语言模型的训练是温良恭俭的,当有人质疑它的答案时,它是很容易退缩的
所以现在让语言模型讨论的时候要加一个可以反对的 Prompt(如:“不需要一定同意对方的想法,你可以表示自己的意见”)


- Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
- Improving Factuality and Reasoning in Language Models through Multiagent Debate
引入不同的角色
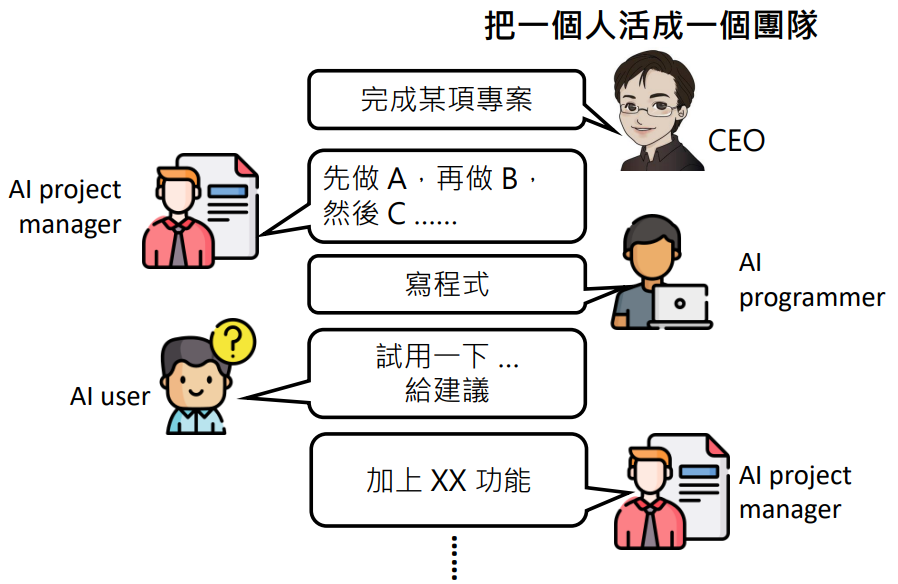
如何创造不同角色:
- 不同模型本来就有不同的专长
- Prompt:“你是一个 project manager”
优化团队:让 AI 给彼此打绩效,绩效低的被优化掉……
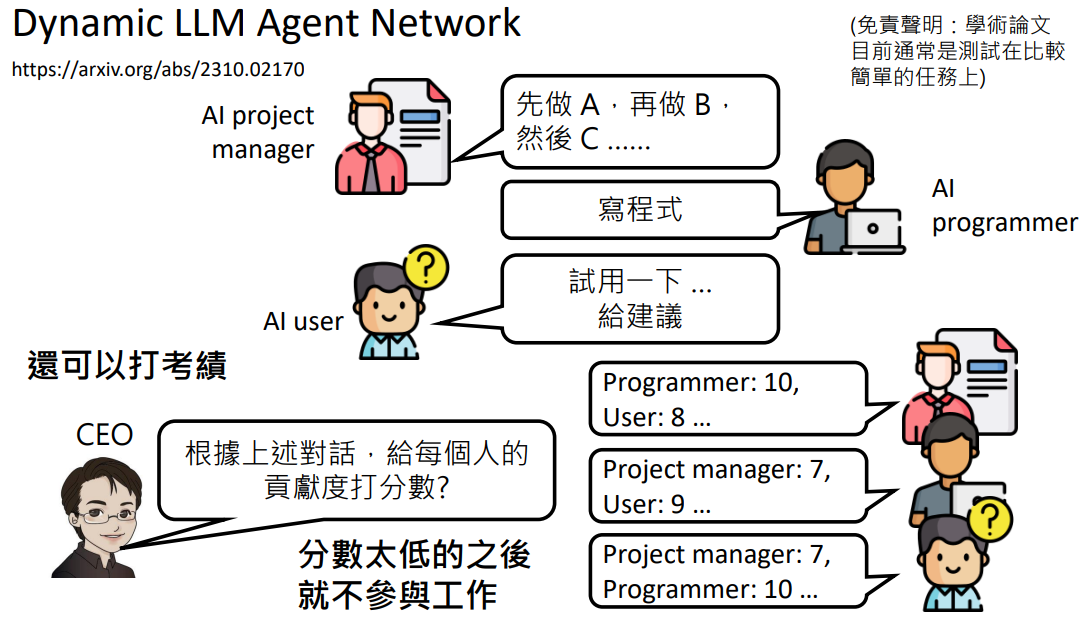
体验 AI 团队:
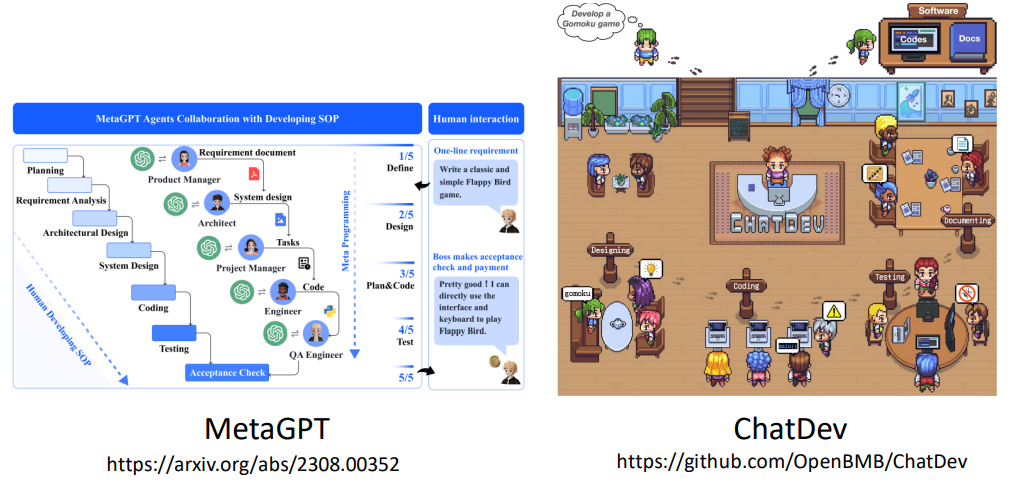
未来不需要打造全能的模型,语言模型可以专业分工,不同团队可以专注于打造专业领域的语言模型
打一套组合拳
我们已经学到了很多强化语言模型的方法,完全可以将这些方法组合起来,打一套组合拳
比如说:
- 将一个任务才拆解成多步
- 每一步生成多个答案
- 让语言模型自我反省,判断答案是否是正确的
- 如果发现某一步的所有答案都是错的,就返回上一步,尝试上一步的下一个答案
- 直到解出问题
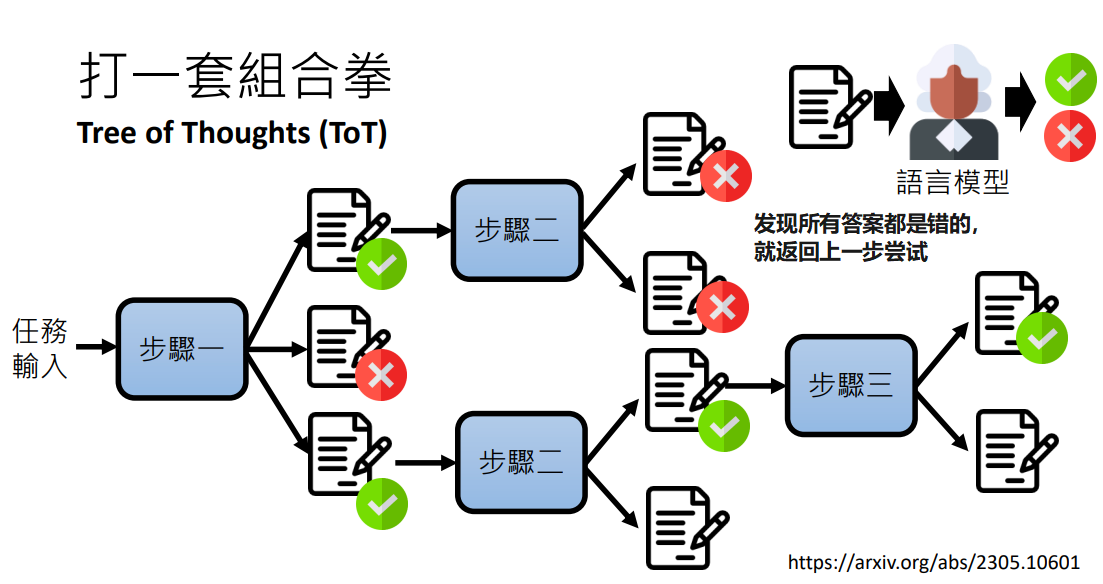
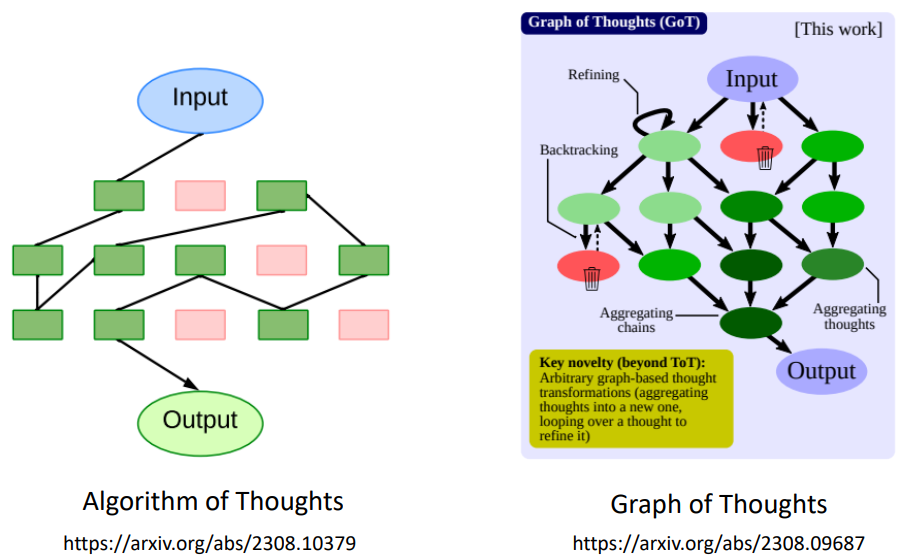
这种方法就是 Tree of Thoughts (ToT)
还有一些其他的思想,比如说: