机器学习开发的迭代循环
- 首先要确定系统的整体架构,这意味着选择机器学习模型、使用什么数据、选择超参数等
- 然后基于这些决策,实现并训练一个模型
- 当你首次训练模型时,它几乎很难达到你期望的效果
- 那么下一步建议是去实现或看看一些诊断方法,比如看看你算法的偏差和方差,还有误差分析
- 然后根据诊断得出的见解就可以做出如下决定,如是否要扩大神经网络规模、调整 正则化参数、增加更多数据、增加或减少一些特征
- 然后根据新选择的架构再次循环这个过程,通常需要多次循环迭代直到获得理想的性能
误差分析
用垃圾邮件检查为例,假设有 500 个交叉验证示例,你的算法将这 500 个交叉验证示例中的 100 个误分类。错误分析过程就是手动查看这 100 个示例,并尝试深入了解算法哪里出了错
具体而言,我通常会做的是找到一组算法在交叉验证集上错误分类的示例,并尝试将它们归为共同主题、或共同属性、共同特征。比如,若你发现被误分类的垃圾邮件归类为:
- 与药品销售有关:21
- 故意的拼写错误:3
- 邮件路由异常:7
- 试图窃取密码的网络钓鱼邮件:18
- 嵌入图像中的垃圾邮件:5
如果最终得到这些计数,那么表明对于判断药品垃圾邮件和试图窃取密码的网络钓鱼邮件模型似乎存在巨大的问题,而故意拼写错误的情况问题较小。这样你就可以优先解决大问题,而不是花大力气解决小问题
注意几点:
- 这些类别可能会相互重叠,或者说它们非相互排斥。一个误分类的邮件可能既与药品销售有关,又存在路由异常
- 如果误分类的条目太多,可能没有足够的人力和时间都进行误差分析,可以随机抽样一部分(如 100 个)进行误差分析
误差分析的关键在于:手动检查算法误分类的示例,这能为后续的尝试提供思路,并且指示优先需要解决哪些问题
错误分析的局限性:对于人类擅长的问题做起来更容易,但是对于连人类都不擅长的任务,错误分析可能会有点难
增加数据的技巧
专注特定数据
训练机器学习算法时,感觉几乎总是希望能有更多的数据,所以有时会忍不住想获取各类更多数据,但获取各类更多数据可能既慢又费钱
相反,添加数据的另一种方式是专注于添加误差分析显示有帮助的更多特定类型的数据(如上一节误差分析显示医药垃圾邮件问题严重,则添加更多医药相关的数据),与其获取更多各类数据,添加少量特定数据是更高效方式,但能大幅提升算法性能
数据增强
数据增强(Data augmentation):利用现有训练示例创建新的训练示例,可以显著增加训练集规模,尤其适用于图像和音频数据
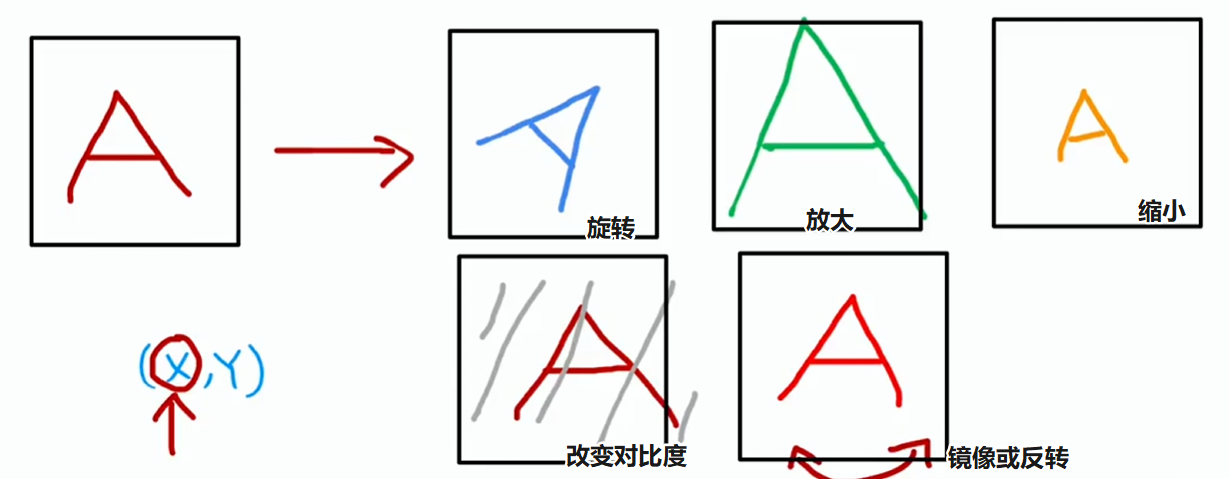

某些数据增强通常没什么用,比如:
- 给图片数据添加纯粹随机的噪声,因为在测试集中这类图像不常见,实际上这可能没多大帮助

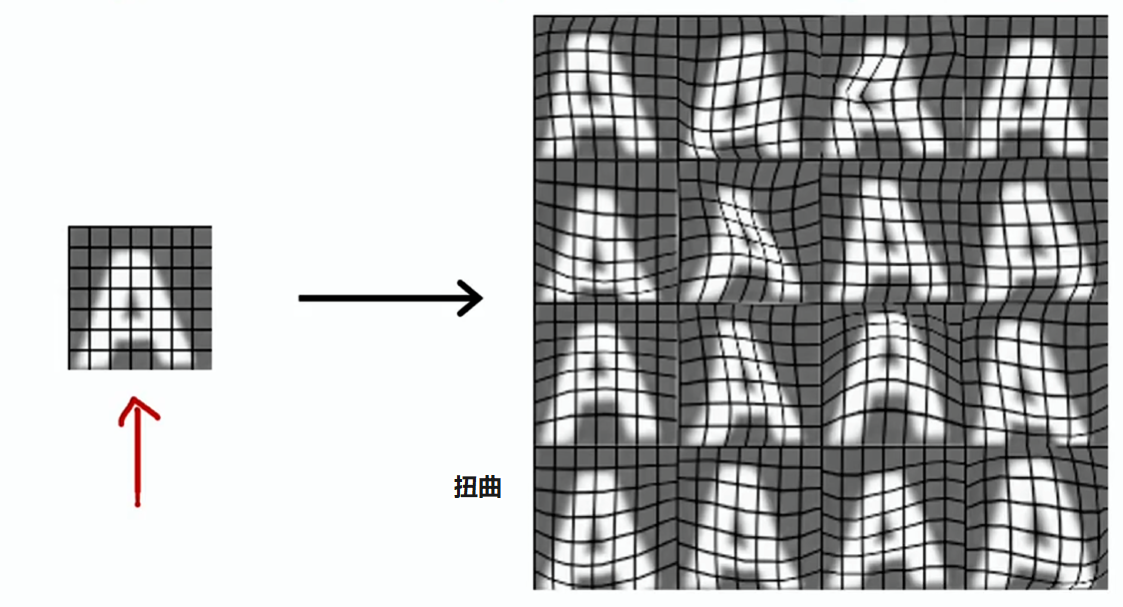
数据合成
数据合成(Data synthesis):从头创建全新的示例,而不是修改现有示例
以照片光学字符识别(OCR:读取图像中的文字)为例,要为这个任务创建人工数据,一种方法是打开电脑的文本编辑器,输入随意的文本,选用不同的字体,用不同颜色和不同的对比度截图

合成数据生成已用于计算机视觉任务、用于其他应用的较少、用于音频任务的也不多
迁移学习
对于一个数据量不足的模型,迁移学习是一项很棒的技术,能让你使用来自其他任务的数据来助力你的模型
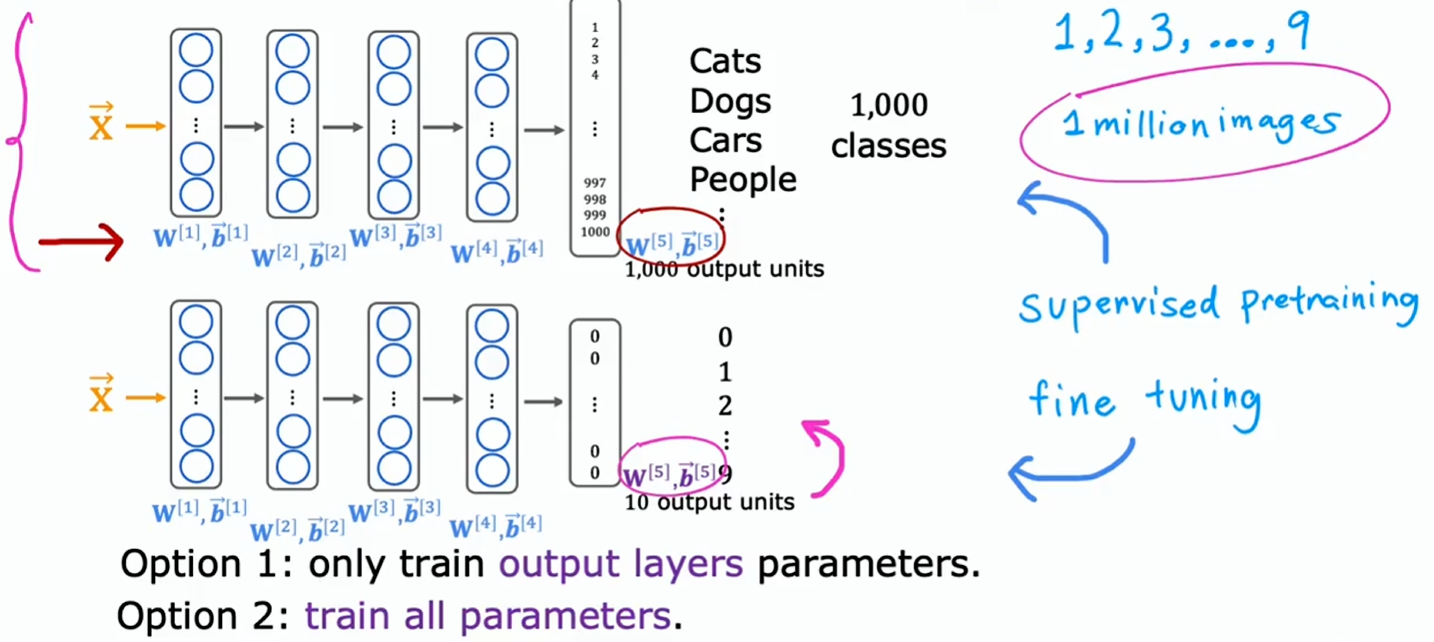
- 假设你要识别 0 到 9 的手写数字,但你没有那么多这些手写数字的标注(数据)
- 假设你找到一个包含一百万张图片,有猫、狗、汽车、人等共 1000 个类别的超大的数据集
- 你可以基于这个大数据集开始训练神经网络,并最终训练出参数
- 接着复制这个神经网络,并保留参数,除了输出层,输出层从之前的 1000 个类别替换为 10 个类别
- 输出层的参数无法复制,因为维度发生了变化,所以需要重新确定输出层的参数
- 在迁移学习中,可以使用除最终输出层之外所有层的参数,然后以最后输出层作为参数的起点,接着运行像梯度下降、Adam 这样的优化算法
- 选择 1:保持之前层的参数不变,仅更新输出层参数以降低成本函数(训练集较小时效果更好)
- 选择 2:允许更新所有参数,但除输出层的参数外都以之前的参数为初始值(训练集较大时效果更好)
其原理是通过学习识别猫、狗、汽车、人等,有望能为早期处理图像输入的层学习到一些合理的参数集,然后将这些参数迁移到新的神经网络,新的神经网络起点更优
这其实就是熟悉的:
- 第一步叫做:监督预训练
- 第二步叫做:微调
迁移学习为何能起作用
为何能采用通过识别猫、狗、汽车得到的参数,去帮助识别手写数字这种截然不同的东西呢?
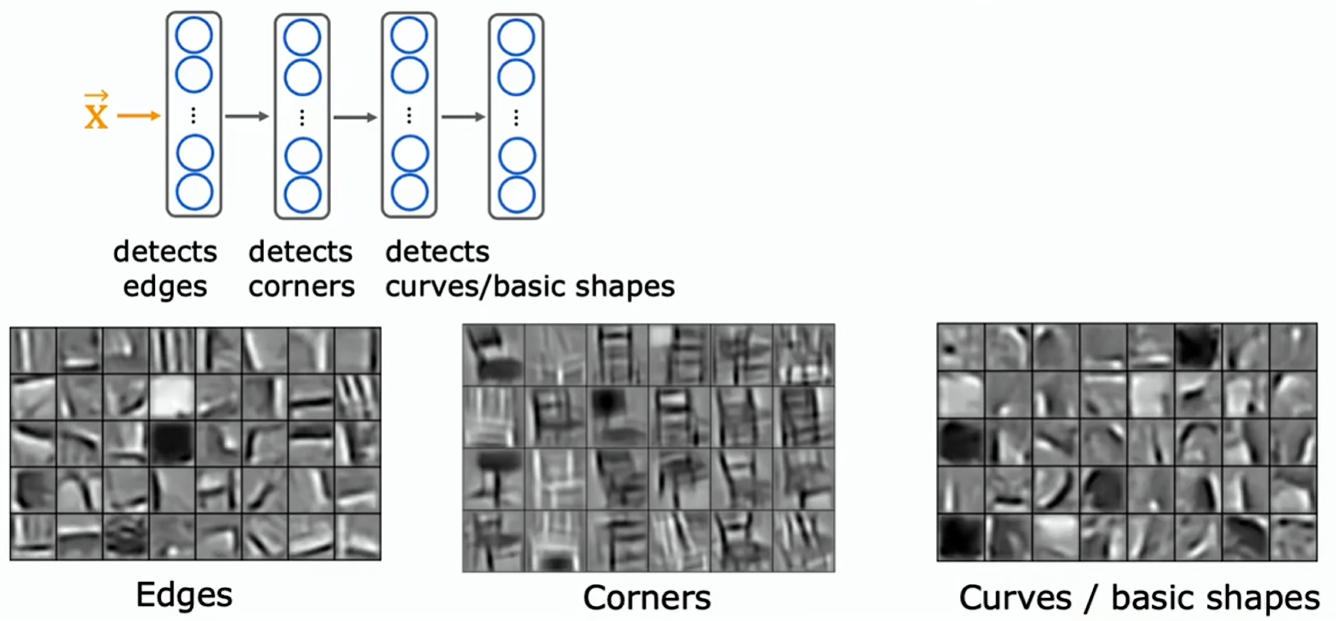
要训练一个神经网络从图像中检测不同物体,那么神经网络:
- 第一层或许会学习去检测图像中的边缘(图像中的低级特征)
- 然后下一层会学习把边缘组合起来以检测角点
- 而之后的下一层可能已学会检测稍微复杂些的,但仍是诸如基本曲线之类的通用形状或小形状
这在帮助模型学习检测这些相当通用的图像特征,如边缘、角落、曲线、基本形状等,这对许多其他计算机视觉任务很有用,比如识别手写数字
不过有一个限制:预训练和微调的输入 必须相同,比如这里都是图片
相反若你的目标是构建一个处理音频的语音识别系统,那么在图像上预训练的神经网络对音频可能用处不大
机器学习项目的完整周期
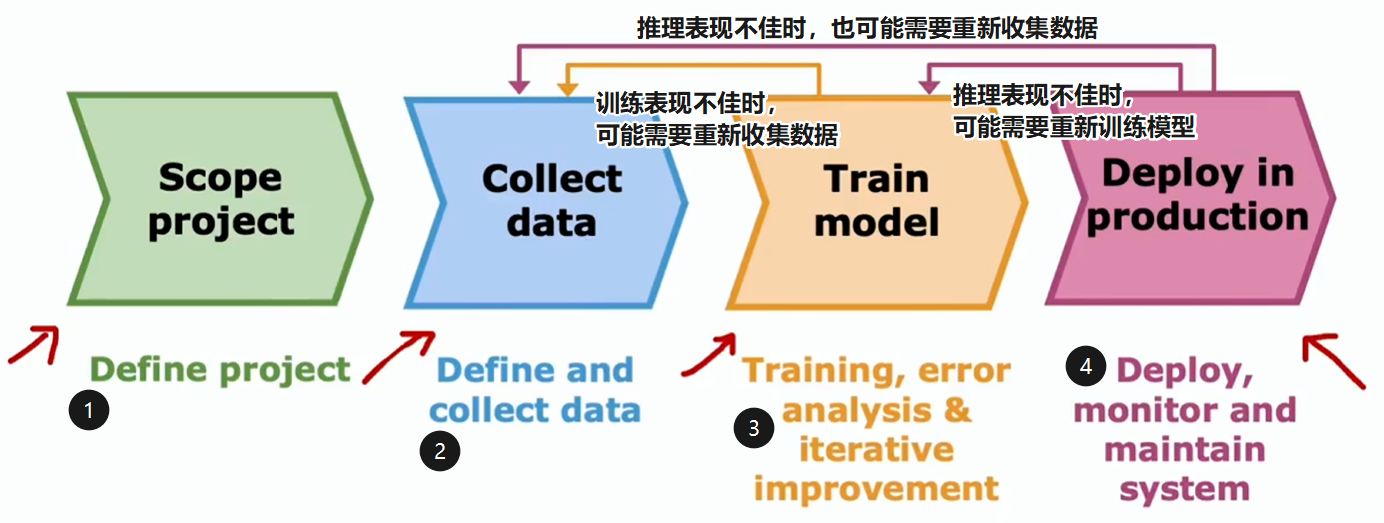
- 界定项目范围,确定项目内容,以及工作方向
- 定义和收集数据
- 训练模型,错误分析,迭代循环(机器学习开发的迭代循环)
- 部署,持续监控系统性能,并在性能变差时维护系统以恢复性能
- 确保可靠和高效的推理
- 记录推理的数据
- 系统监控
- 通过记录推理的数据和系统监控,了解模型表现,并进行更新迭代
- MLOps(machine learning operations)是一个新的领域,研究如何系统地构建、部署和维护机器学习系统的实践,以确保器学习模型可靠、可扩展、日志完善且受到监控
- 例如,当要将系统部署给数百万人时,可能得确保有一个高度优化的做法和一些额外步骤,确保为数百万人提供服务的计算成本不会太高
公平、偏见与伦理
如果你正在构建一个会影响人的机器学习系统,要考虑确保你的系统足够公平,尽量没有偏见,并且在应用中遵循伦理准则
偏见:
- 例如曾有一个招聘工具被发现歧视女性,开发该系统的公司已经停止使用它,但人们希望这个系统压根就没被推出过
- 或者还有一个有详实记录的例子,人脸识别系统将深色皮肤的人误匹配,相比浅肤色的人,深肤色的人被误识别成罪犯照片的情况要频繁得多
- 有些系统发放银行贷款时存在偏见,歧视某些群体
不良用例:
- 比如有一个被广泛引用且被广泛观看的视频,BuzzFeed 公司制作的一段美国前总统巴拉克·奥巴马的深度伪造视频
- 社交媒体有时会传播有害内容又或是煽动性言论,这是因为优化用户参与度致使算法这样做
- 曾经有一些机器人被用来生成虚假内容,如在产品上发布虚假评论。无论是出于商业目的,还是政治目的
- 也有使用机器学习来构建有害产品、进行欺诈等行为
希望学习算法不会强化负面刻板印象,不要构建对社会有负面影响的机器学习系统