回归树
上节仅探讨了作为分类算法的决策树,本节会将决策树推广为回归算法
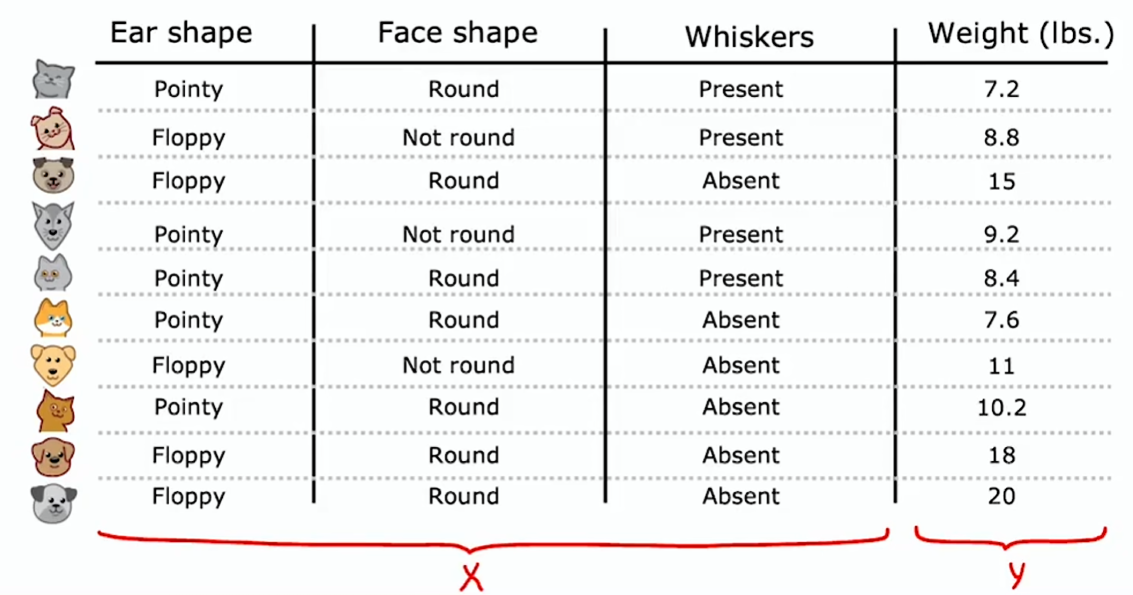
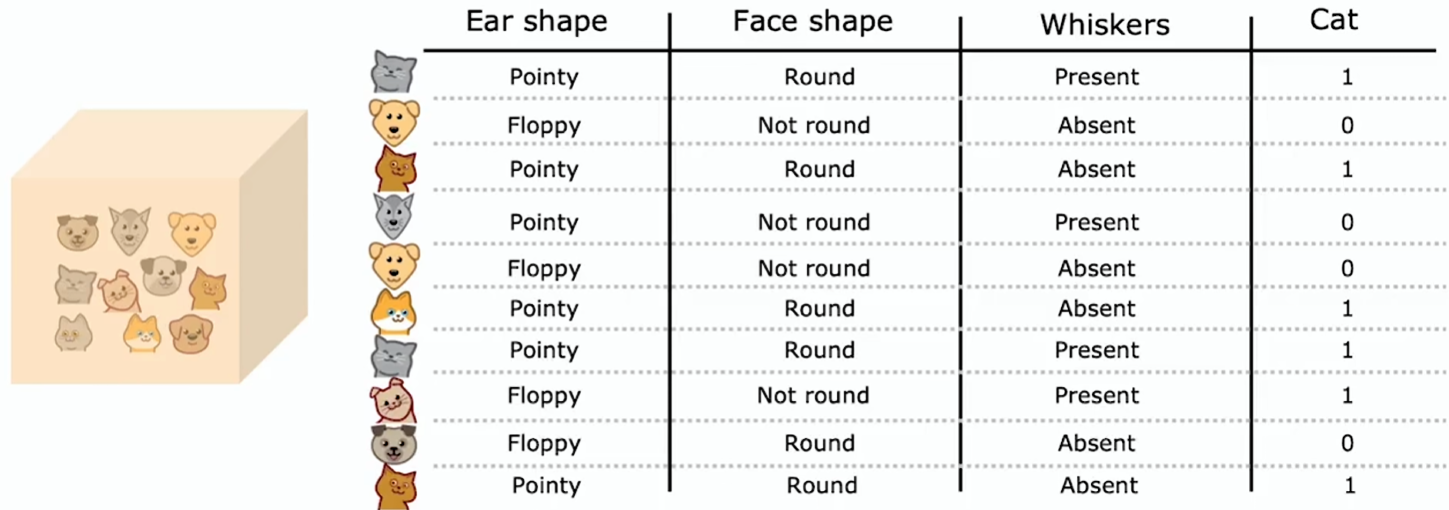
假如通过学习构建出如下决策树:
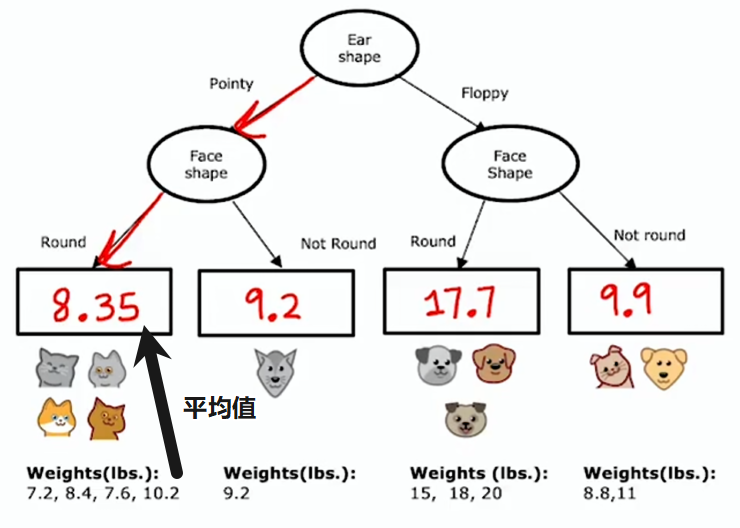
每个节点如何选择用于划分的特征
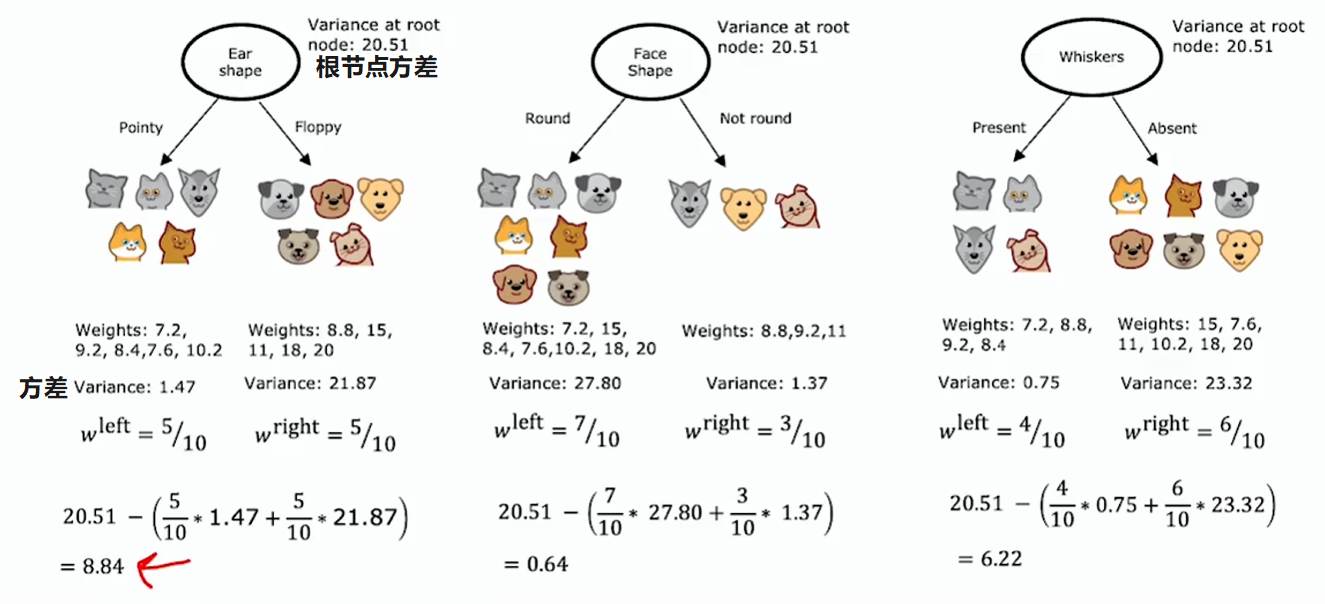
与分类算法决策树的熵类似,使用方差来衡量回归树的信息增益。方差用于大致衡量一组数字的离散程度
这个加权平均方差与我们之前用的加权平均熵作用非常相似,在决定分类问题使用何种划分时,会选择能带来最大信息增益(最大方差降幅)的那个特征
树集成
使用单个决策树的一个缺点是,该决策树可能对数据中的微小变化非常敏感:

仅仅改变一个训练示例,会导致算法在根节点处产生不同的划分,从而产生一棵完全不同的树,这一事实说明该算法并不那么稳健
若不只是训练一棵决策树,而是训练一堆不同决策树,就能得到更准确的预测。这就是树集成,即多棵树的集合
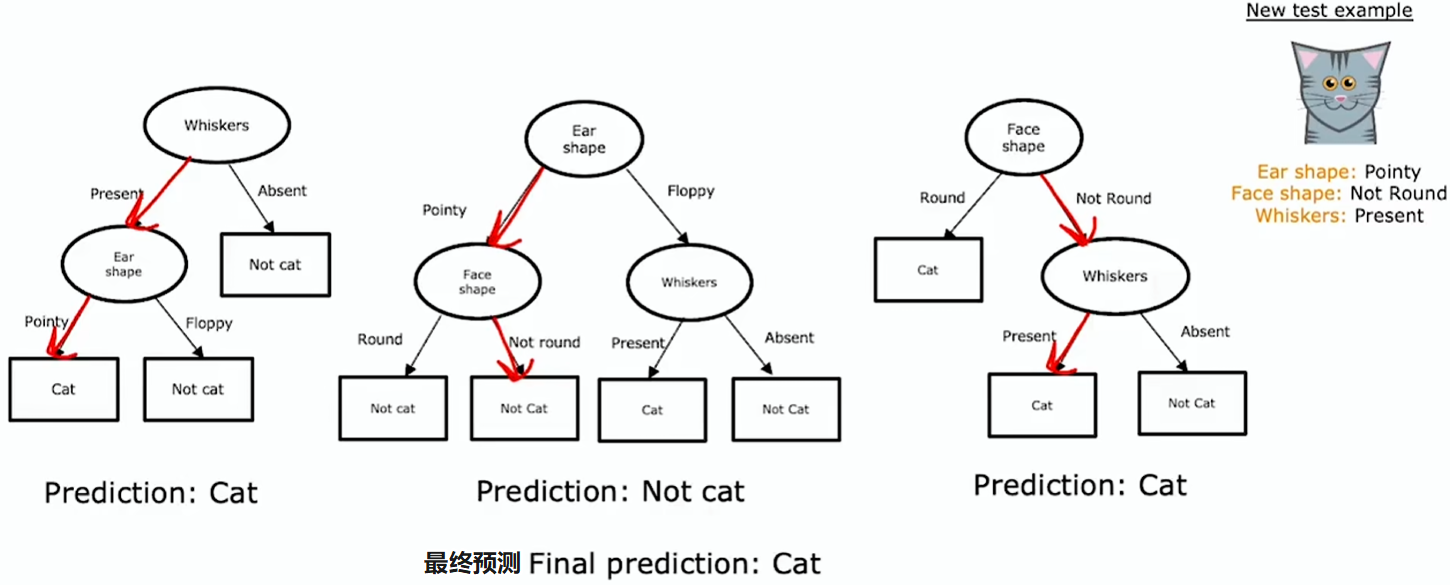
例如有由三棵树组成的集成,其中每一棵都是区分猫与非猫的一种合理办法,那么一个需要分类的新测试示例,需要在该新示例上运行这三棵树,并让它们对最终预测进行投票(少数服从多数)
有放回抽样
我们要构建多个随机训练集,它们都与原始训练集略有不同
使用有放回抽样创建一个新的随机训练集,新的随机训练集由 10 个与原始数据集大小相同的样本组成
假设一个虚拟袋子,将原始训练集放入,之后随机抽取一个作为新的随机训练集的一个示例,之后放回虚拟袋子中,继续随机抽取第二个,直到抽取完成 10 个:
其中有些是重复的,而且这个新的训练集并未包含全部 10 个原始训练示例
随机森林算法
以下是生成一组树的方法:
- 给定一个大小为 m 的训练集,接着令 b = 1~B 依次取值,如此重复执行 B 次
- 每次通过有放回抽样来创建一个大小为 m 的新训练集,然后在这个新训练集上训练一棵决策树
- 总共进行 B 次这样的操作,得到 B 个不同的决策树,这样构成一个树集成
- 当尝试进行预测时,让这些树对正确的最终预测进行投票
其中 B 通常取 64~128 中的任意值。事实证明,将 B 设置得更大不会损害性能,但超过某一程度后收益会递减。比如 1000 棵树只会大幅降低计算速度,而无法显著提升整个算法的性能
以上这个算法叫做袋装决策树算法
这个算法有一个问题:即便采用有放回采样方法,有时最终在根节点和根节点附近的一些节点会一直采用相同的划分方式
对这个算法进行一处修改,进一步使每个节点的特征选择随机化,这会使树集合彼此间变得更加不同,会使其性能更佳,这就将袋装决策树算法转变为了随机森林算法
通常的做法是,在每个节点处选择用于分割的特征时,如果有 n 个特征可用,则选择这 n 个特征的随机子集 k<n 个特征,并允许算法仅从该特征子集中进行选择
换言之,选取 k 个特征作为可用特征,然后从这 k 个特征里选择信息增益最高的特征用于分裂
当 n 很大时,例如 n 为几十、几百甚至更多,k 的典型取值是
增强树
增强树(Boosted trees intuition):每次循环时(除第一次外),采样时不是等概率地从所有 m 个示例中选取,而是更倾向于选取之前训练的树分类效果差的误分类示例
刻意练习:查看目前已训练好的决策树,并看看哪些方面还做得不好,然后在构建下一棵决策树时,会更关注那些做得不好的示例
到底该把概率提高多少,其中的数学细节相当复杂,使用时无需操心这些,只要知道如今使用最广泛的是 XGBoost(eXtreme Gradient Boosting,极端梯度提升):
- 它是增强树的开源实现,速度快且效率高
- 在默认分裂标准和停止分裂的时机标准上也有不错的选择
- 它还内置了正则化以防止过拟合
- 实际上会为不同的训练样本赋予不同权重,而非采用有放回抽样。所以它无需生成大量随机选取的训练集,这使其比使用有放回抽样法更具效率
- 实际上 XGBoost 和深度学习算法,似乎是在众多竞赛中胜出的两种算法

决策树 VS. 神经网络
决策树:
- 决策树和树集成在表格数据上通常效果很好
- 也就是说,如果你的数据集看起来像个超大的电子表格,那决策树就值得考虑
- 不推荐在非结构化数据上使用决策树和树集成方法,神经网络在处理非结构化数据任务时往往表现得更好
- 比如图像、视频、音频、不太可能以电子表格格式存储的文本等数据
- 决策树和树集成的一大优势在于它们的训练速度非常快
- 小型决策树或许人类可解读
神经网络:
- 在各类数据上都表现良好,包括表格数据以及非结构化数据,还有包含结构化与非结构化成分的混合数据
- 不利的是神经网络或许比决策树慢,大型神经网络要花很长时间来训练
- 神经网络能进行迁移学习。这对于许多只有小数据集的应用,能够运用迁移学习并在规模大得多的数据集中进行预训练,这对取得具有竞争力的性能至关重要
- 若要构建一个由多个协同工作的机器学习模型组成的系统,将其串联起来或许会更容易
- 而且相较于多个决策树,训练多介神经网络或许更容易
- 当把多个神经网络连接起来,可以使用梯度下降同时训练它们;而决策树每次只能训练一棵