DOM 节点层次结构
每个 DOM 节点都属于相应的内建类。
层次结构(hierarchy)如下:
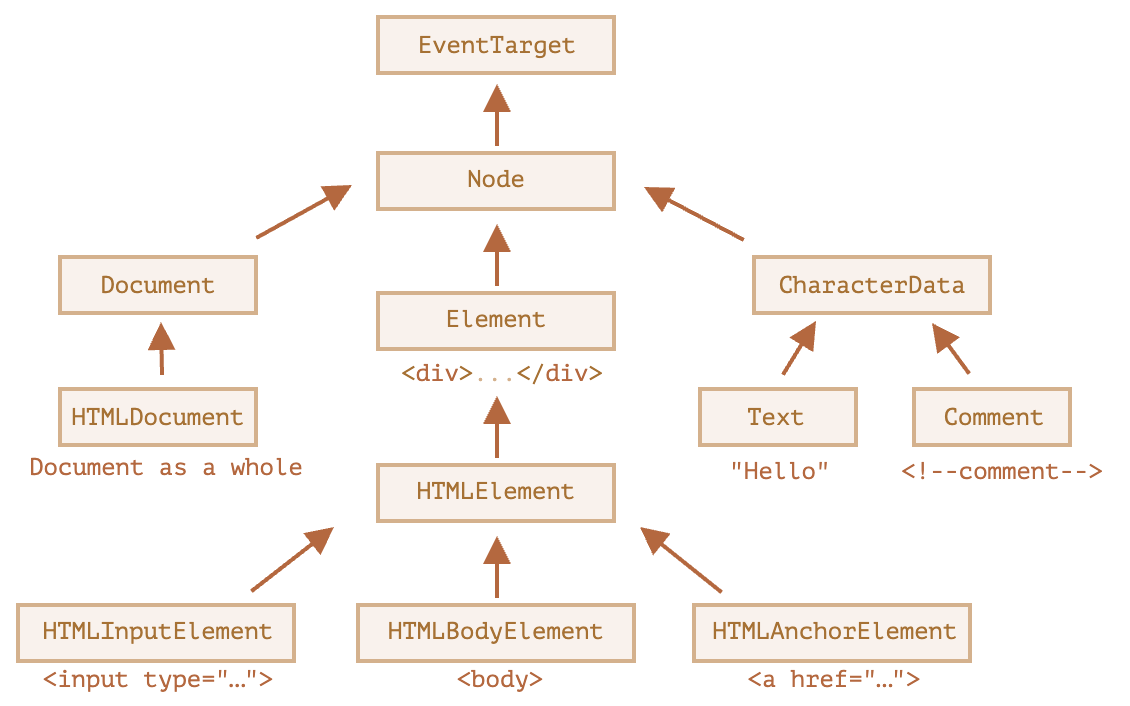
- EventTarget —— 是一切的根“抽象(abstract)”类。
- 该类的对象从未被创建。它作为一个基础,以便让所有 DOM 节点都支持所谓的“事件(event)”。
- Node —— 也是一个“抽象”类,充当 DOM 节点的基础。
- 它提供了树的核心功能:
parentNode,nextSibling,childNodes等(它们都是 getter)。 Node类的对象从未被创建。但是还有一些继承自它的其他类(因此继承了Node的功能)。
- 它提供了树的核心功能:
- Document 由于历史原因通常被
HTMLDocument继承(尽管最新的规范没有规定)—— 是一个整体的文档。- 全局变量
document就是属于这个类。它作为 DOM 的入口。
- 全局变量
- CharacterData —— 一个“抽象”类,被下述类继承:
- Element —— 是 DOM 元素的基础类。
- 它提供了元素级导航(navigation),如
nextElementSibling,children,以及搜索方法,如getElementsByTagName和querySelector。 - 浏览器不仅支持 HTML,还支持 XML 和 SVG。因此,
Element类充当的是更具体的类的基础:SVGElement,XMLElement和HTMLElement。
- 它提供了元素级导航(navigation),如
- HTMLElement —— 是所有 HTML 元素的基础类。
- 它会被更具体的 HTML 元素继承:HTMLInputElement、HTMLBodyElement、HTMLAnchorElement 等。一般都具有特定的属性和方法
- 而一些元素,如
<span>、<section>、<article>等,没有任何特定的属性和方法,所以它们没有更具体的 HTML 继承元素,而是HTMLElement类的实例
console.dir()与console.log()
console.log:友好方式输出到控制台
console.dir:输出到控制台原始值 对于 DOM 元素:
console.log(elem)显示元素的 DOM 树
console.dir(elem)将元素显示为对象对于函数:
console.log(func)显示函数定义字符串console.dir(func)将函数显示为对象
命名空间
HTML/XML 文档在浏览器内均被表示为 DOM 树。
HTML 以外其他网页上常见的 XML:
对应的命名空间:
- XHTML:
http://www.w3.org/1999/xhtml - SVG:
http://www.w3.org/2000/svg - MathML:
http://www.w3.org/1998/Math/MathML
DOM 的很多方法都有相对应的命名空间方法 *NS(namespace, ...) 用来处理非 HTML 的 Element
Node 和 Element
Node:在 DOM 树中,所有的节点都是Node,包括Element,也就是说Node包含了 HTML/XML 元素标签、text、注释等内容,它是所有 DOM 的基类Element:在 DOM 树中,Element是所有 HTML/XML 元素的基类
节点类型
nodeType
nodeType 属性提供了一种“过时的”用来获取 DOM 节点类型的方法。
它有一个数值型值:
- 元素节点:
elem.nodeType === document.ELEMENT_NODE // 1 - 文本节点:
elem.nodeType === document.TEXT_NODE // 3 document对象:document === document.DOCUMENT_NODE // 9,- 注释节点:
elem.nodeType === document.COMMENT_NODE // 8
一共有 12 种节点类型
nodeName 和 tagName
给定一个 DOM 节点,可以从 nodeName 或者 tagName 属性中读取它的标签名:
document.body.nodeName // BODY
document.body.tagName // BODYtagName属性仅适用于ElementnodeName是为任意Node定义的:- 对于元素,它的意义与
tagName相同 - 对于其他节点类型(text,comment 等),它拥有一个对应节点类型的字符串
- 对于元素,它的意义与
- 即:
document.tagName // undefined,document不是Element,是Node
标签名称始终是大写的,除非是在 XML 模式下
浏览器有两种处理文档(document)的模式:HTML 和 XML。通常,HTML 模式用于网页。只有在浏览器接收到带有
Content-Type: application/xml+xhtmlheader 的 XML-document 时,XML 模式才会被启用。
- 在 HTML 模式下,
tagName/nodeName始终是大写的- 在 XML 模式中,大小写保持为“原样”。如今,XML 模式很少被使用。
节点内容
innerHTML
innerHTML 属性仅对元素节点有效,其他节点使用 nodeValue/data
- 读:将元素中的 HTML 获取为字符串形式(删除所有空白字符,保留标签,保留换行)
- 写:解析字符串为 DOM,替换元素中的 HTML
注意:
- 脚本不会执行:用
innerHTML将一个<script>标签插入到 document 中 —— 它会成为 HTML 的一部分,但是不会执行。 innerHTML += ...并不是追加,而是完全重写。- 做了以下工作:
- 移除旧的内容
- 然后写入新的
innerHTML(新旧结合)
- 因为内容已“归零”并从头开始重写,因此所有的图片和其他资源都将重写加载
- 会重新走一遍 渲染流程
- 状态都会重置:鼠标选中状态、
<input>的value等
- 做了以下工作:
outerHTML
- 读:包含了元素的完整 HTML 字符串,就像
innerHTML加上元素本身一样(删除所有空白字符,保留标签,保留换行) - 写:与
innerHTML不同,写入outerHTML不会改变元素。而是在 DOM 中替换它
<div>Hello, world!</div>
<script>
let div = document.querySelector('div');
// 使用 <p>...</p> 替换 div.outerHTML
div.outerHTML = '<p>A new element</p>';
// 蛤!'div' 还是原来那样!
// 但是页面 DOM 已经变成了 <p>
console.log(div.outerHTML); // <div>Hello, world!</div>
</script>在 div.outerHTML = ... 中发生的事情是:
div被从文档(document)中移除- 另一个 HTML 片段
<p>A new element</p>被插入到其位置上 div仍拥有其旧的值
nodeValue/data
innerHTML 属性仅对元素节点有效
文本节点、注释节点,具有它们的对应项:nodeValue 和 data 属性。这两者在实际使用中几乎相同,只有细微规范上的差异。同样,可读可写
元素节点没有 nodeValue 和 data 属性,或者为 null
innerText 和 outerText
只有元素节点有
innerText:
- 读:将元素中的 HTML 获取为字符串形式(删除所有空白字符,删除标签,保留换行)
- 写:写入为纯文本,所有符号(如:标签)均按字面意义处理
outerText:
- 读:将元素(包含元素)的 HTML 获取为字符串形式(删除所有空白字符,删除标签,保留换行)
- 写:写入为纯文本,所有符号(如:标签)均按字面意义处理,替换当前元素
- 从文档(document)中移除当前元素
- 在该位置插入文本
textContent
所有 Node 都有
- 读:将节点中的 HTML 获取为字符串形式(保留所有空白字符,保留标签,保留换行)
- 写:写入为纯文本,所有符号(如:标签)均按字面意义处理
特别说明
以上所有属性 document 节点都没有,或者为 null
节点显隐
hidden 特性(attribute)和 DOM 属性(property)指定元素是否可见。
可以在 HTML 中使用它,或者使用 JS 对其进行赋值:
<div>Both divs below are hidden</div>
<div hidden>With the attribute "hidden"</div>
<div id="elem">JavaScript assigned the property "hidden"</div>
<script>
elem.hidden = true
</script>从技术上来说,hidden 与 style="display:none" 做的是相同的事。
集合:NodeList 和 HTMLCollection
哪些常见操作会返回这二者?
NodeList:
document.getElementsByNamedocument.querySelectorAllelem.childNodes
HTMLCollection:
document.formsdocument.imageselem.getElementsByTagNameelem.getElementsByTagNameNSelem.getElementsByClassNameelem.children
NodeList
Node的集合- 只读
Node是响应式的:修改文档对象,相应的 DOM 视图也会发生更新- 即时更新的集合:DOM 视图发生改变,
NodeList会即时更新- 特殊:
document.querySelectorAll惰性机制,DOM 增删节点不会即时更新返回的集合
- 特殊:
属性和方法:
[index]:通过下标索引,越界返回undefinedlength:节点集合的长度item(index):通过下标索引,越界返回nullforEach(cb):遍历方法entries():返回 key-value 的迭代器keys():返回 key 的迭代器,也就是索引values():返回 value 的迭代器,也就是节点Symbol(Symbol.iterator):迭代器,for...of
forEach 执行流程:
// forEach 执行流程模拟
NodeList.prototype.forEach = function forEach(cb) {
const len = this.length // 先获取到 length 进行保存,之后及时 length 更新了也不会改变
for (let i = 0; i < len; i++) { // 就遍历到 len
if (i in this) { // 当前遍历的元素存在
cb(this[i], i, this)
}
}
}迭代器执行流程:
// 迭代器执行流程模拟
NodeList.prototype[Symbol.iterator] = function* iterator() {
for (let i = 0; i < this.length; i++) {
yield this[i]
}
}
// 或
NodeList.prototype[Symbol.iterator] = function iterator() {
let i = -1
let self = this
return {
next: () => {
i++ // 每次调用 next,游标往下指
return { value: self[i], done: i === self.length }
}
}
}所以:
- 遍历途中增加元素:
forEach只遍历到一开始的长度;迭代器会无限迭代 - 遍历途中删除元素:二者表现一致——跳索引
HTMLCollection
Element的集合- 只读
Element是响应式的(Element属于Node):修改文档对象,相应的 DOM 视图也会发生更新- 即时更新的集合:DOM 视图发生改变,
HTMLCollection会即时更新
属性和方法:
[index]:通过下标索引,越界返回undefinedlength:节点集合的长度item(index):通过下标索引,越界返回nullnamedItem(name):传入节点的name属性,返回特定的节点,不存在返回nullSymbol(Symbol.iterator):迭代器,`for…of
版本说明
HTML5 之前基本没有开放 Node 相关的接口,和 Node 和 NodeList 相关的 API 基本都是 HTML5 新增的(不绝对),如:elem.childNodes、querySelector* 等