浏览器渲染整体流程
浏览器在地址栏输入 URL 后显示网页,背后做了诸多的事情。
去除 DNS 查找等这些细枝末节的工作,整个大的部分可以分为两个,那就是网络和渲染。
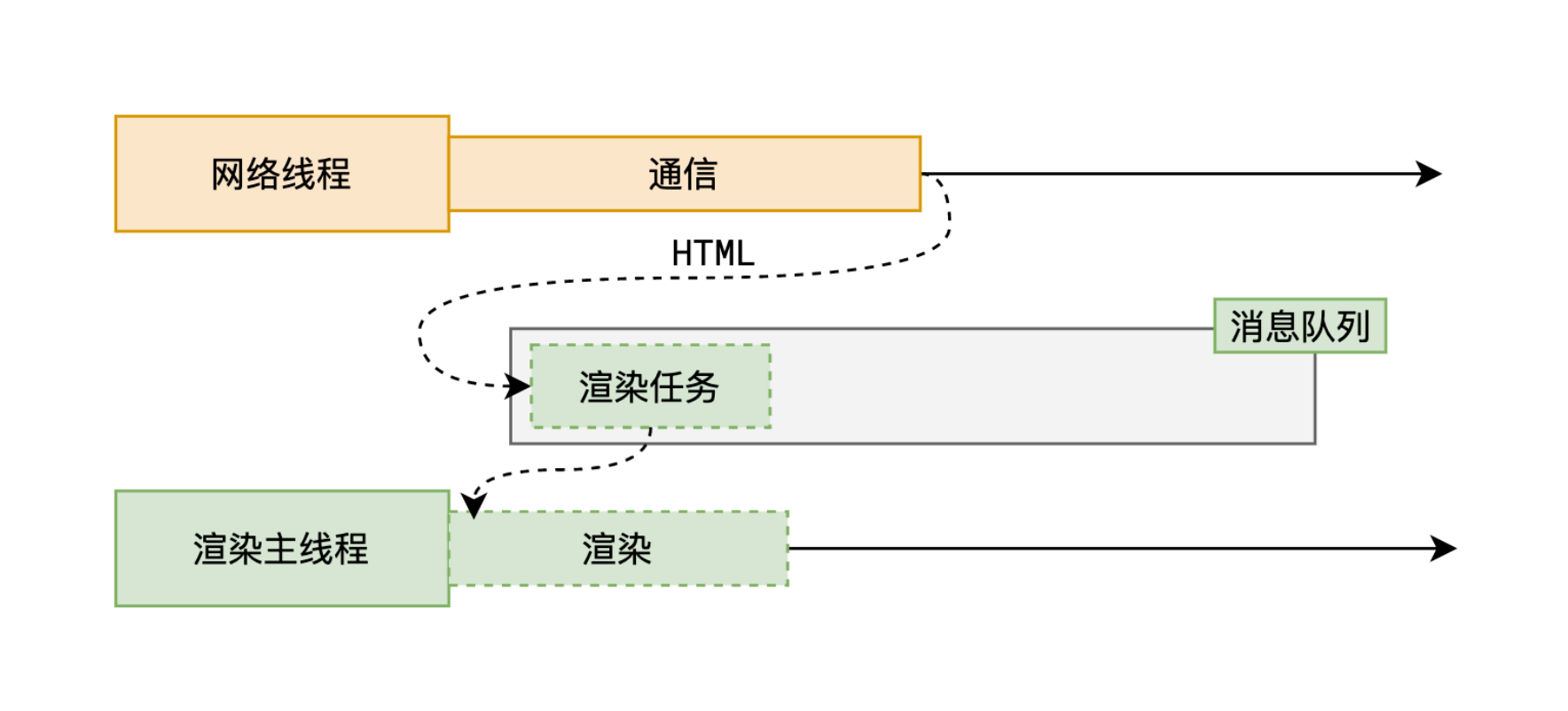
首先,浏览器的网络线程会发送 HTTP 请求,和服务器之间进行通信,之后将拿到的 HTML 封装成一个渲染任务,并将其传递给渲染主线程的消息队列。在事件循环机制的作用下,渲染主线程取出消息队列中的渲染任务,开启渲染流程。
网络线程和服务器之间通信的过程并非本节要讨论的,本节主要研究浏览器的渲染进程如何将一个密密麻麻的 HTML 字符串渲染成最终的页面。
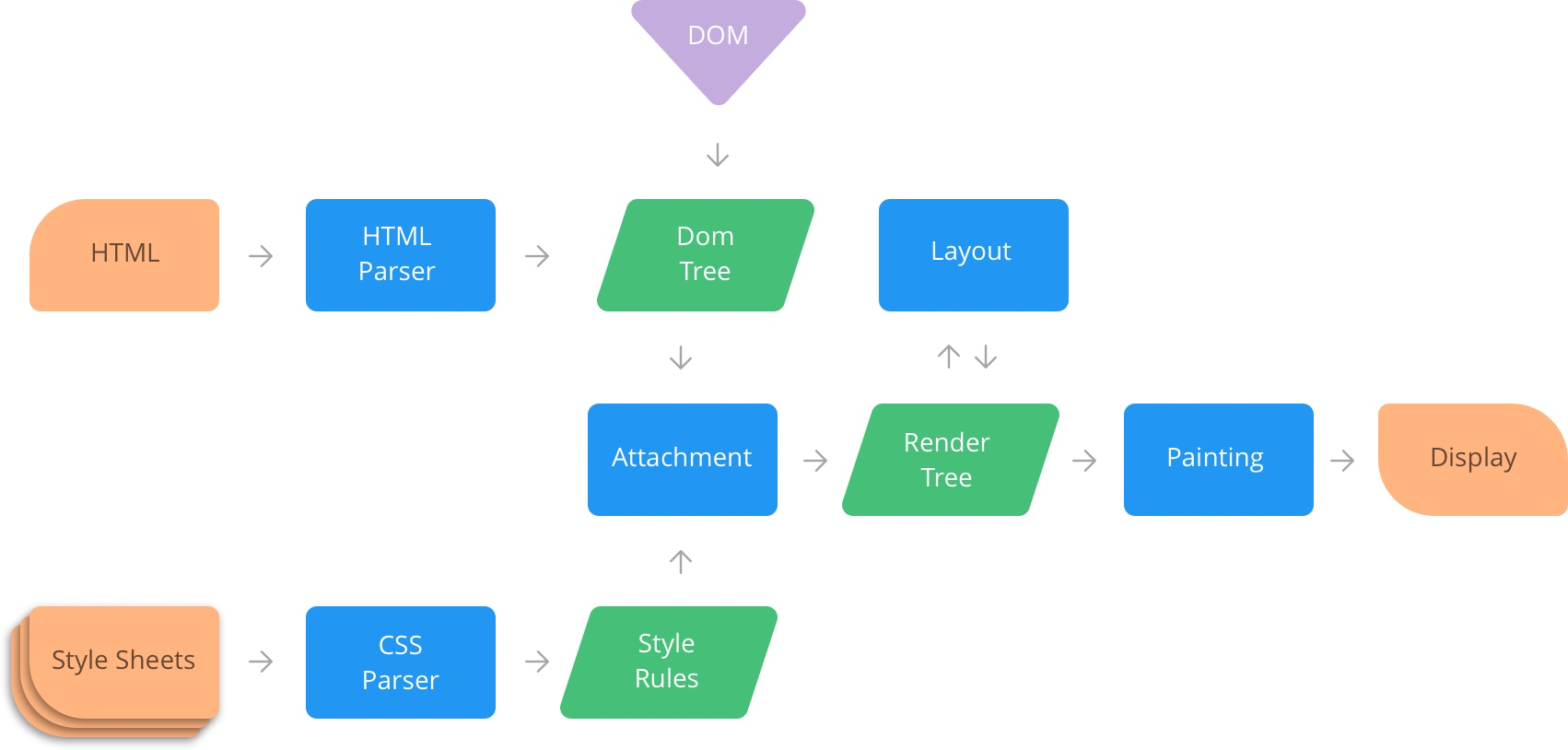
整体流程:整个渲染流程分为多个阶段,分别是: HTML 解析、样式计算、布局、分层、生成绘制指令、分块、光栅化、绘制:
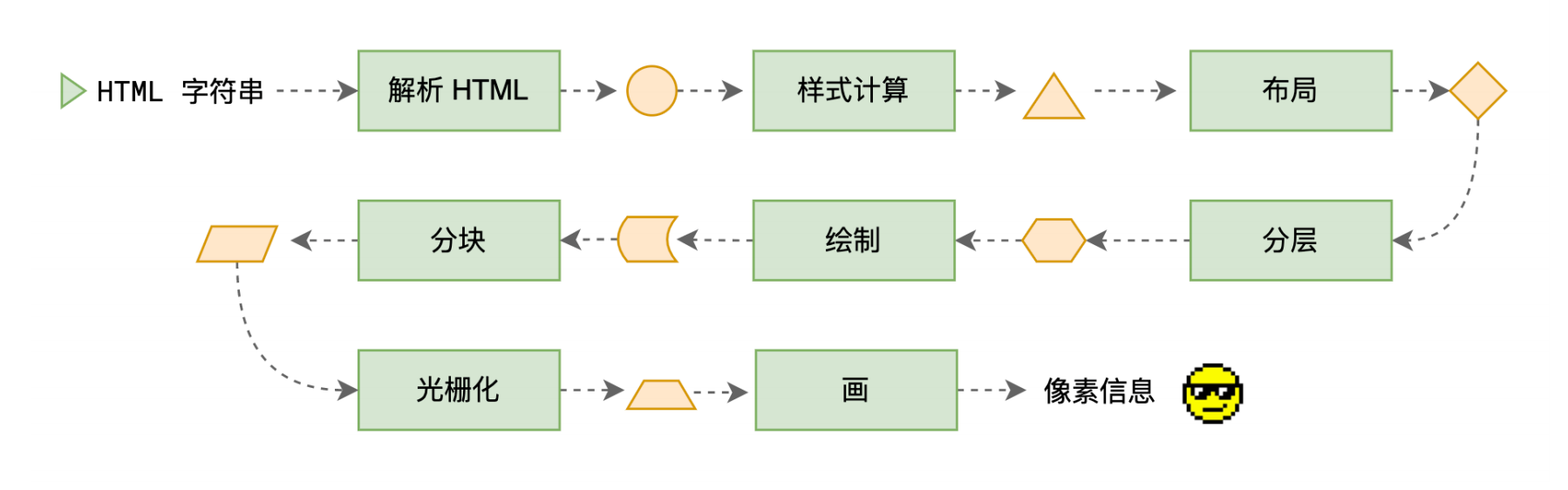
每个阶段都有明确的输入输出,上一个阶段的输出会成为下一个阶段的输入。
这样,整个渲染流程就形成了一套组织严密的生产流水线。
第一步:解析 HTML
输入:HTML 字节数据
输出:DOM 树和 CSSOM 树
参与者:渲染主线程、预解析线程、网络线程
通过网络请求获得 HTML 文件,将 0 和 1 组成的字节数据按照指定的字符集(<meta charset='utf-8'>)编码为字符串
浏览器先将这些字符串通过词法分析转换为标记(token),这一过程在词法分析中叫做标记化(tokenization)。本质就是要将这长长的字符串分拆成一块块,并给这些内容打上标记,便于理解这些最小单位的代码是什么意思。
以什么规范进行标记化?依靠 <!DOCTYPE html>
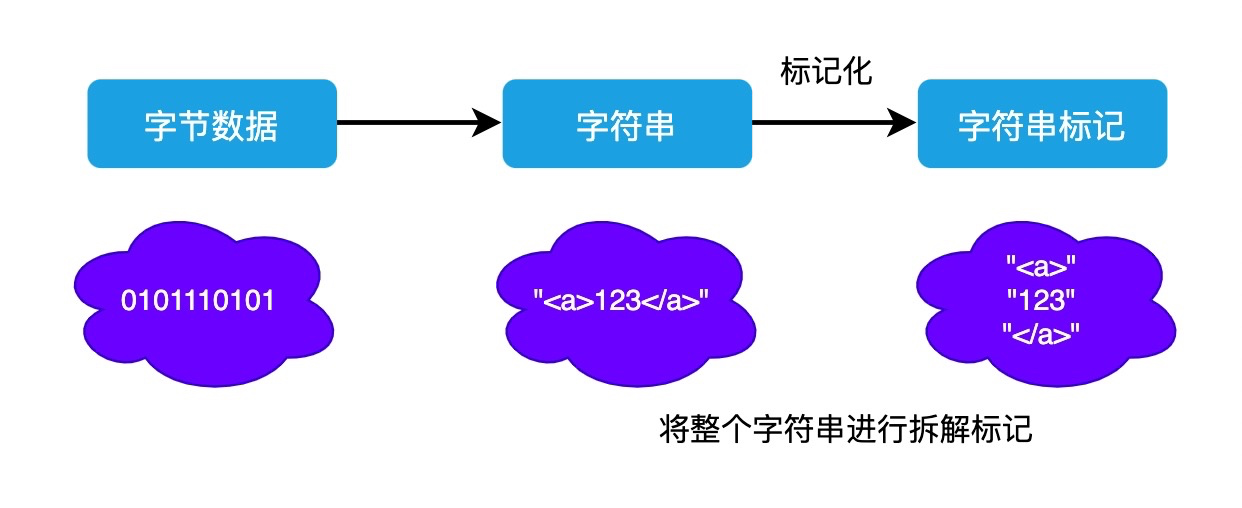
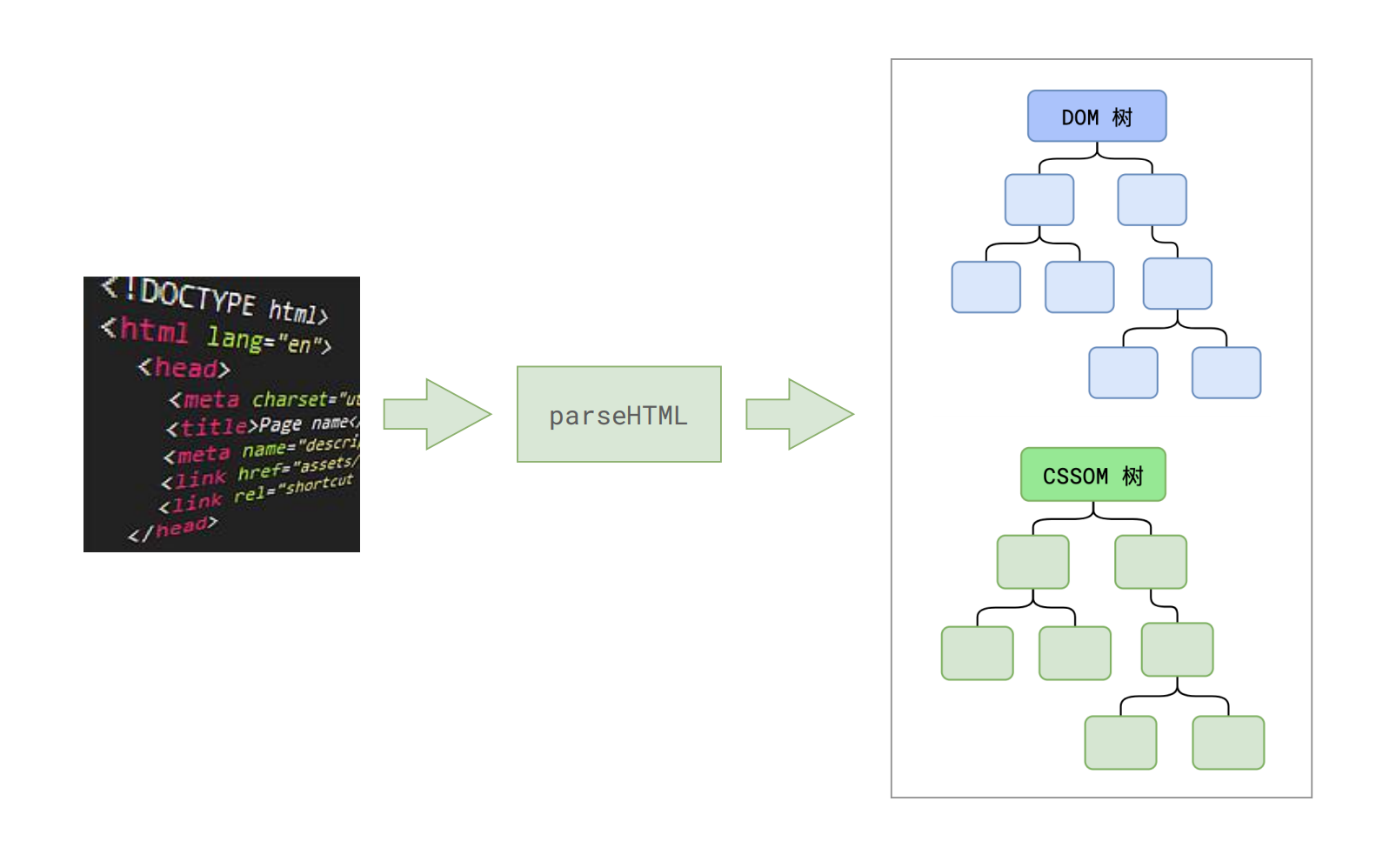
将整个字符串进行了标记化之后,就能够在此基础上构建出对应的 DOM 树出来。
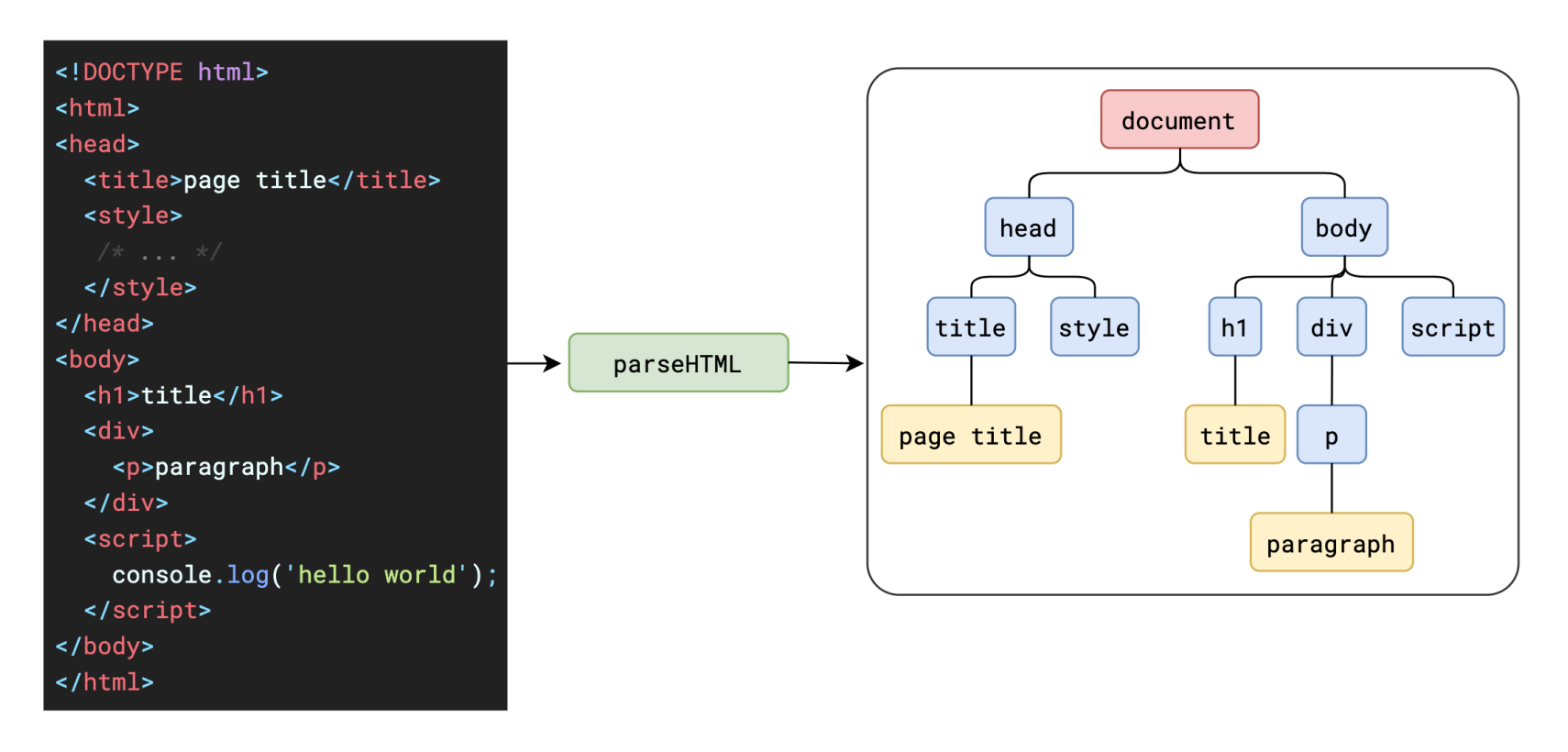
上面的步骤,我们就称之为解析 HTML。整个流程如下图:
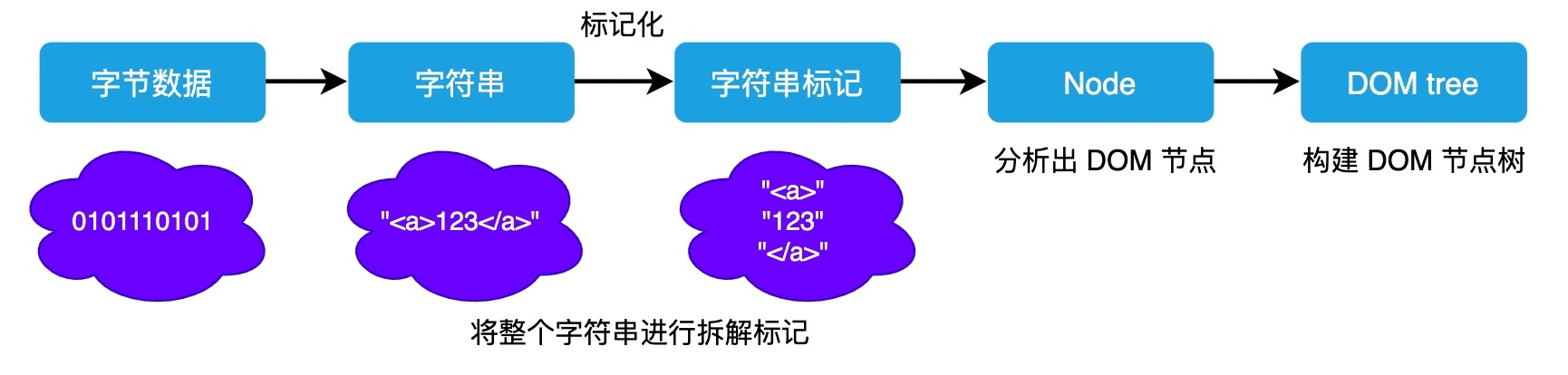
在解析 HTML 的过程中,我们可以能会遇到诸如 style、link 这些标签,这是和网页样式相关的内容。此时就会涉及到 CSS 的解析。
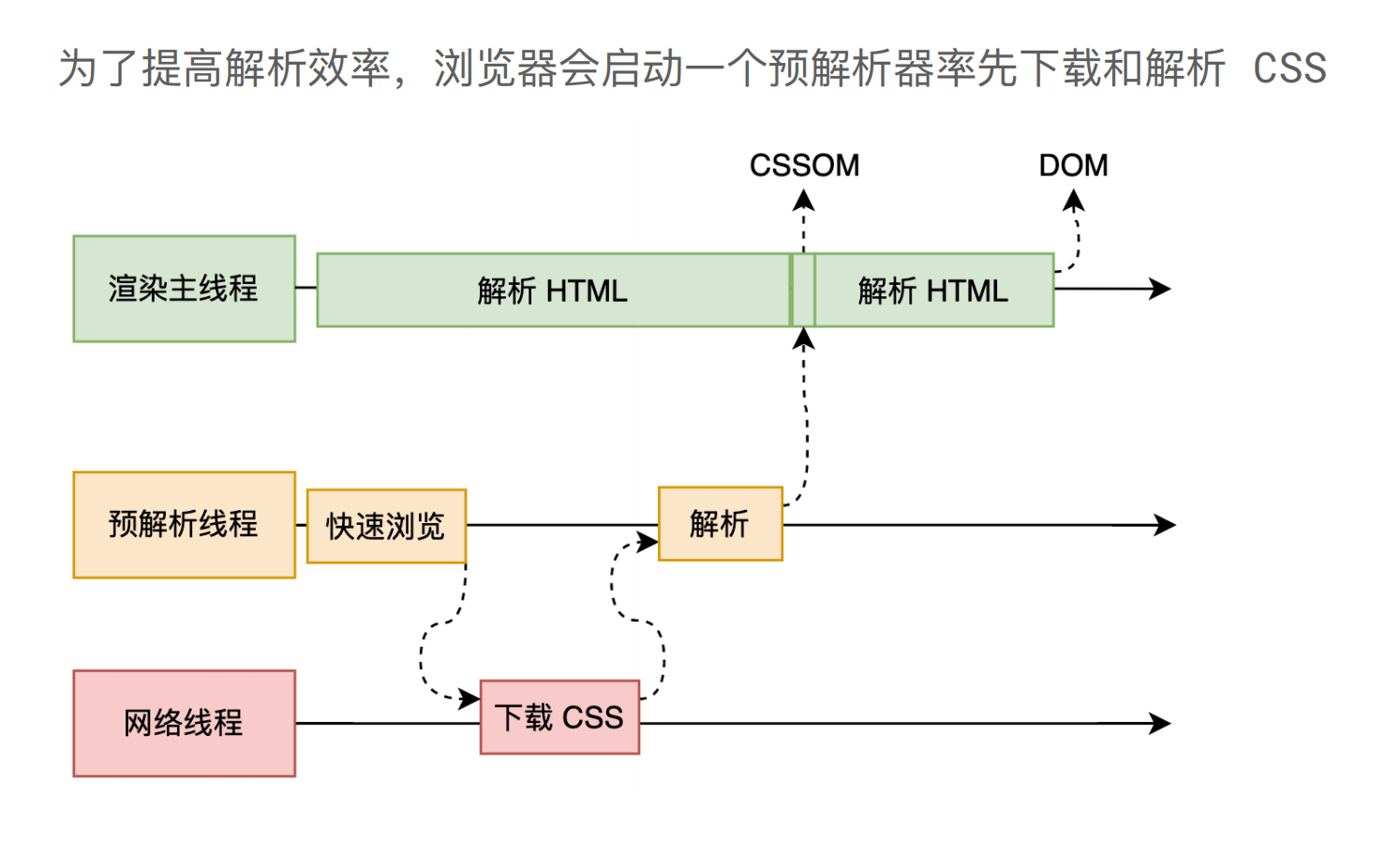
为了提高解析效率,浏览器在开始解析前,会启动一个预解析的线程,率先下载 HTML 中的外部 CSS 文件和外部的 JS 文件。
预解析线程负责:快速浏览获取外部链接(如:CSS、JS)对其进行下载、解析 CSS(style、link)后提供给渲染主线程
如果主线程解析到 link 位置,此时外部的 CSS 文件还没有下载解析好,主线程不会等待,继续解析后续的 HTML。这是因为下载和解析 CSS 的工作是在预解析线程中进行的。这就是 CSS 不会阻塞 HTML 解析的根本原因。
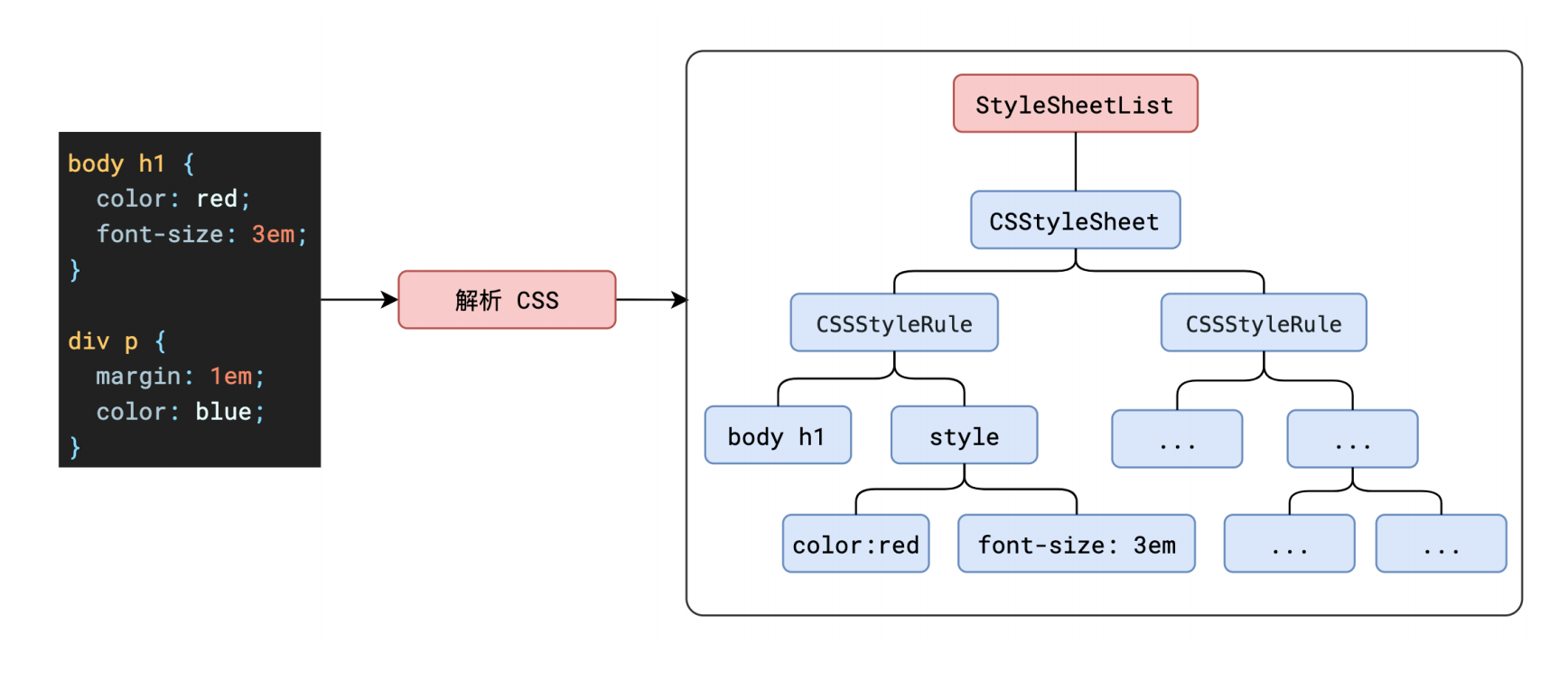
最终,CSS 的解析在经历了从字节数据、字符串、标记化后,最终也会形成一颗 CSSOM 树。
上面也有提到,预解析线程除了下载外部 CSS 文件以外,还会下载外部 JS 文件,那么浏览器是如何处理外部 JS 文件的?
如果主线程解析到 script 位置,会停止解析 HTML,转而等待 JS 文件下载好,并将 JS 全局代码解析执行完成后,才能继续解析 HTML。
为什么呢?
这是因为 JS 代码的执行过程可能会修改当前的 DOM 树,所以 DOM 树的生成必须暂停。这就是 JS 会阻塞 HTML 解析的根本原因。
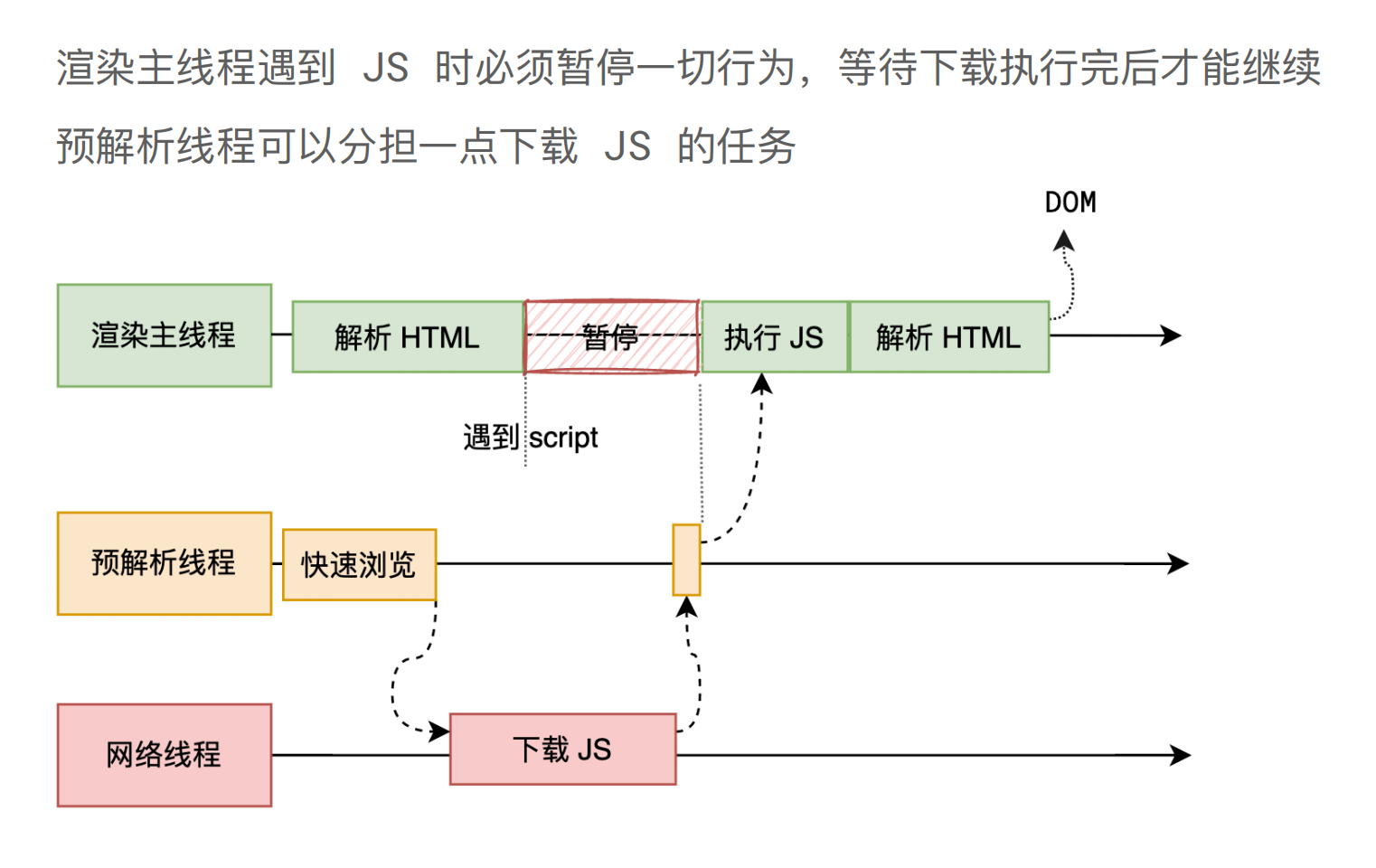
因此,如果想首屏渲染的越快,就越不应该在最前面就加载 JS 文件,这也是都建议将 script 标签放在 body 标签底部的原因。
另外,在现代浏览器中,为我们提供了新的方式来避免 JS 代码阻塞渲染的情况:
asyncdeferprefetchpreload- …
详见 资源提示关键词
最后总结一下此阶段的成果,第一步完成后,会得到 DOM 树和 CSSOM 树,浏览器的默认样式、内部样式、外部样式、行内样式均会包含在 CSSOM 树中。
得到了两棵树,如下图所示:
第二步:样式计算
输入:DOM 树和 CSSOM 树
输出:渲染树(带样式信息的 DOM 树)
参与者:渲染主线程
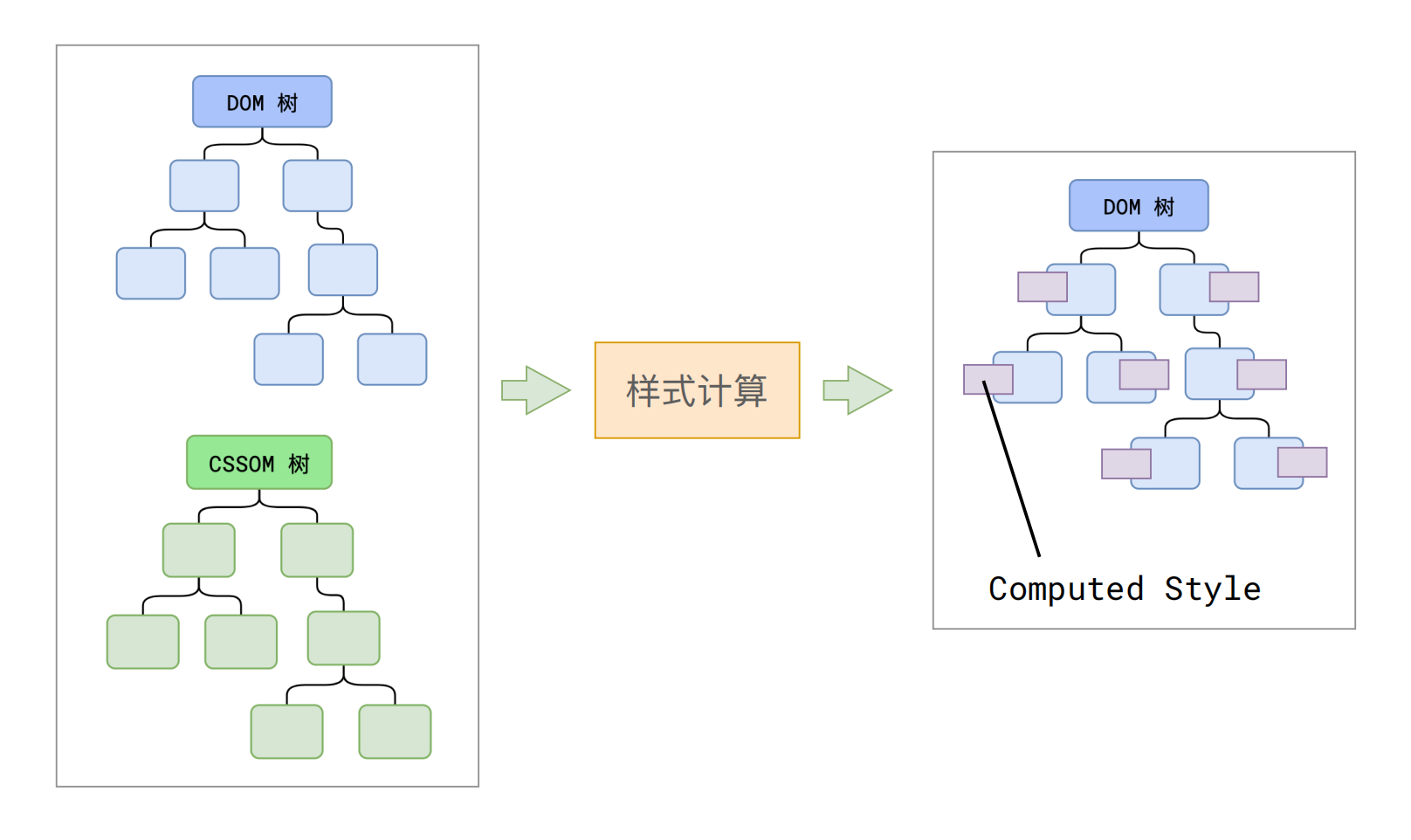
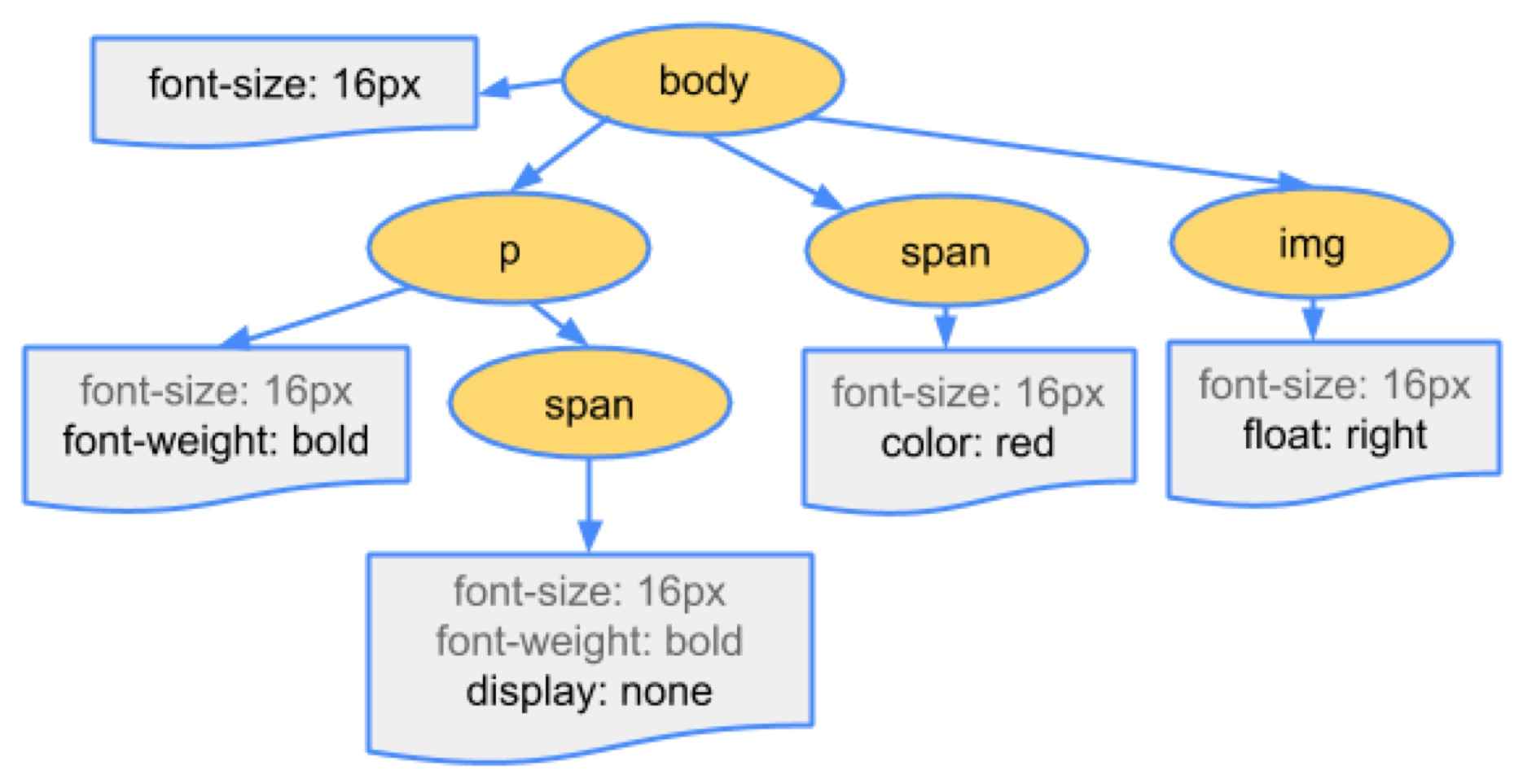
拥有了 DOM 树还不足以知道页面的外貌,因为通常页面的元素会设置一些样式。渲染主线程会遍历得到的 DOM 树,结合 CSSOM 树,依次为树中的每个节点计算出它最终的样式,称之为样式计算(Computed Style)。
在这一过程中,很多预设值会变成绝对值,比如 red 会变成 rgb(255, 0, 0);相对单位会变成绝对单位,比如 em 会变成 px。
浏览器会确定每一个节点的样式到底是什么,并最终生成一颗样式规则树,这棵树上面记录了每一个 DOM 节点的样式。
需要注意的是,这里所指的浏览器确定每一个节点的样式,是指在样式计算时会对所有的 DOM 节点计算出所有的样式属性值。如果开发者在书写样式时,没有写某一项样式,那么可能会使用其继承来的值或默认值(具体规则参考:CSS 属性值的计算过程)。
这一步完成后,就得到一棵带有样式的 DOM 树。也就是说,经过样式计算后,之前的 DOM 树和 CSSOM 树合并成了一颗带有样式的 DOM 树,称之为“渲染树”。
第三步:布局
输入:渲染树(带样式信息的 DOM 树)
输出:布局树(带几何信息和样式信息的节点树)
参与者:渲染主线程
前面这些步骤完成之后,渲染进程就已经知道页面的具体文档结构以及每个节点拥有的样式信息了,可是这些信息还是不能最终确定页面的样子。
只知道网页的文档流以及每个节点的大小颜色等样式是远远不足以渲染出页面内容的,还需要通过布局(layout)来计算出每个节点的几何信息(geometry)。
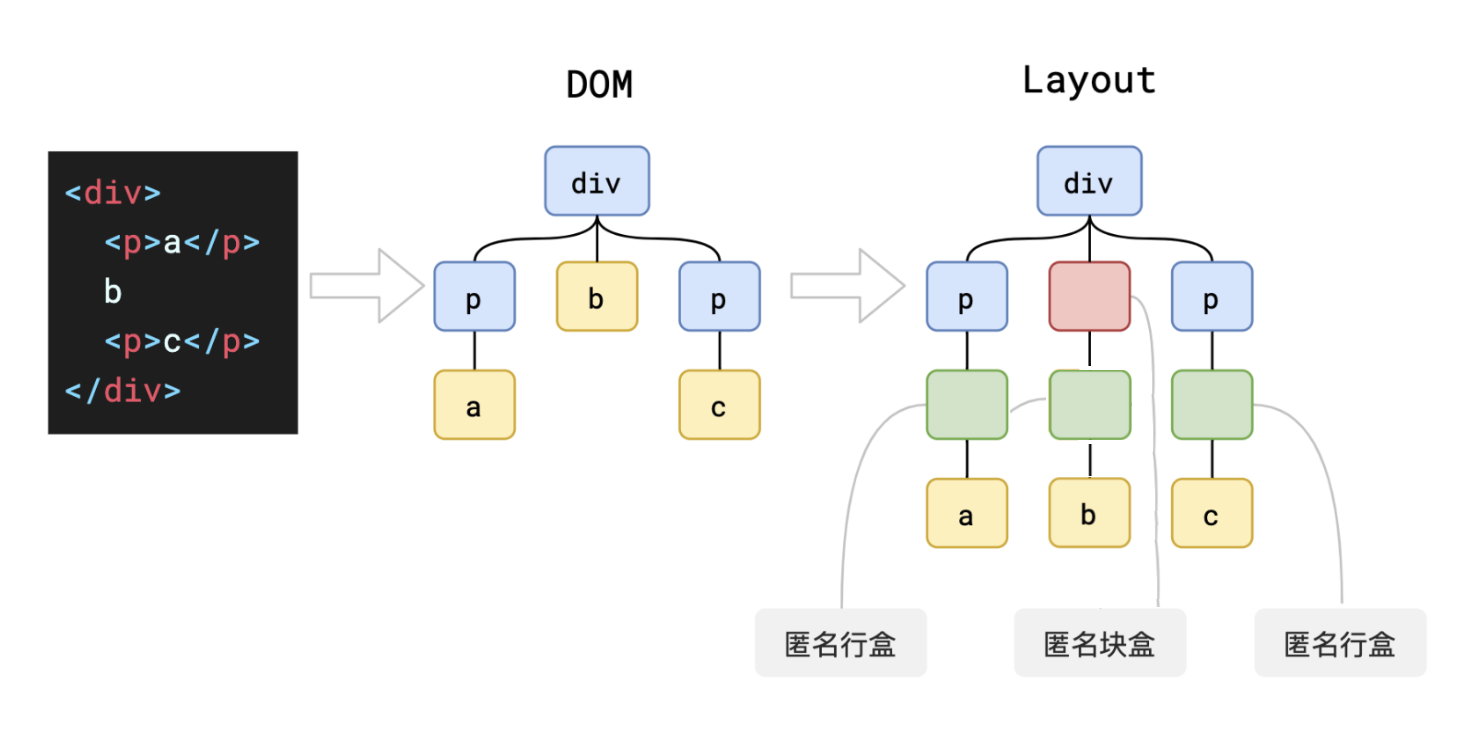
生成布局树的具体过程是:主线程会遍历刚刚构建的渲染树,根据 DOM 节点的计算样式算出一个布局树(layout tree)。布局树上每个节点会有它在页面上的 x, y 坐标(有些节点有 z 坐标)以及盒子大小(bounding box sizes)的具体信息。
布局树大部分时候和渲染树并非一一对应。虽然它长得和先前构建的 DOM 树差不多,但是不同的是这颗树只有那些可见的(visible)节点信息。
如:display: none; 的节点没有几何信息,不会生成到布局树;使用了 ::before、::after 等伪元素选择器虽然 DOM 树中不存在这些伪元素节点,但它们拥有几何信息,所以会生成到布局树中;还有匿名行盒、匿名块盒等都会导致渲染树和布局树无法一一对应。
第四步:分层
输入:布局树(带几何信息和样式信息的节点树)
输出:层次树
参与者:渲染主线程
在确认了布局树后,接下来就是绘制了么?
还不急,这里还会有一个步骤,就是分层。
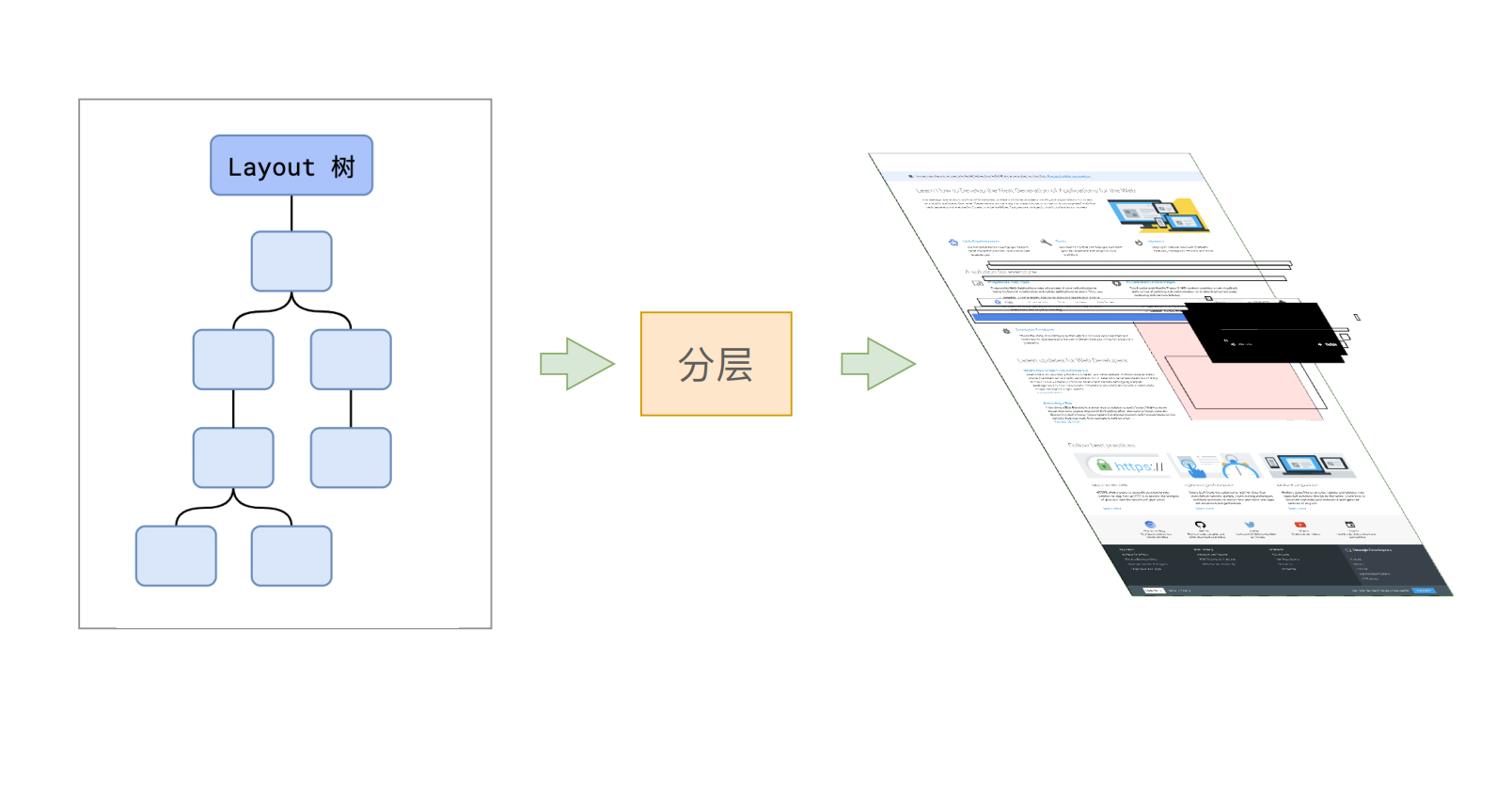
分层的好处在于,将来某一个层改变后,仅会对该层进行后续处理,从而提升效率。
为了确定哪些元素需要放置在哪一层,主线程需要遍历整颗布局树来创建一棵层次树(Layer Tree)
滚动条、视频播放器、堆叠上下文(和 z-index 有关,但不仅仅是)、transform、opacity 等样式都会或多或少的影响分层结果,也可以通过使用 will-change 属性来告诉浏览器对其分层。
第五步:生成绘制指令
输入:层次树
输出:每个层的绘制指令集
参与者:渲染主线程
主线程会为每个层单独产生绘制指令集,用于描述这一层的内容该如何画出来。
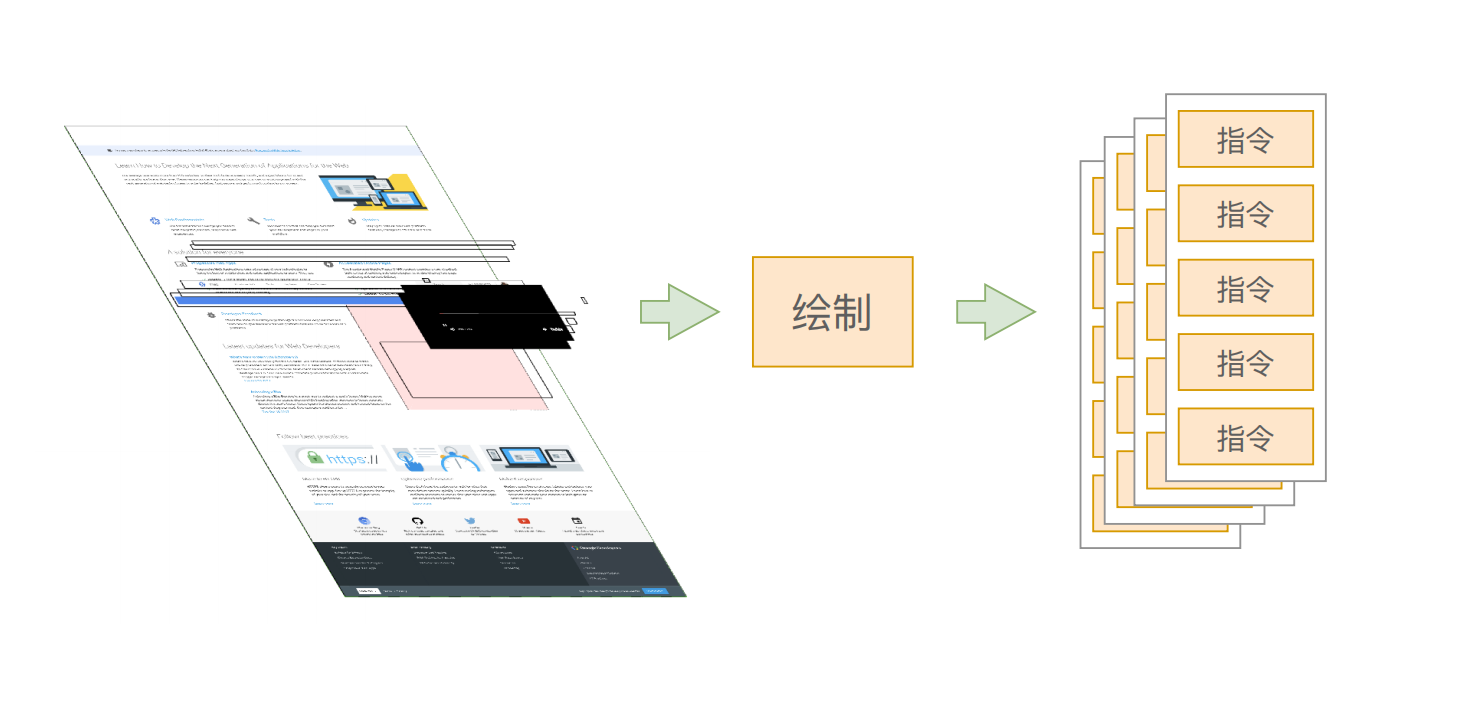
这里的绘制指令,类似于“将画笔移动到 xx 位置,放下画笔,绘制一条 xx 像素长度的线”,我们在浏览器所看到的各种复杂的页面,实际上都是这样一条指令一条指令的执行所绘制出来的。
如果熟悉 canvas,那么这样的指令类似于:
context.beginPath(); // 开始路径
context.moveTo(10, 10); // 移动画笔
context.lineTo(100, 100); // 绘画出一条直线
context.closePath(); // 闭合路径
context.stroke(); // 进行勾勒注意,这一步只是生成诸如上面代码的这种绘制指令集,还没有开始执行这些指令。
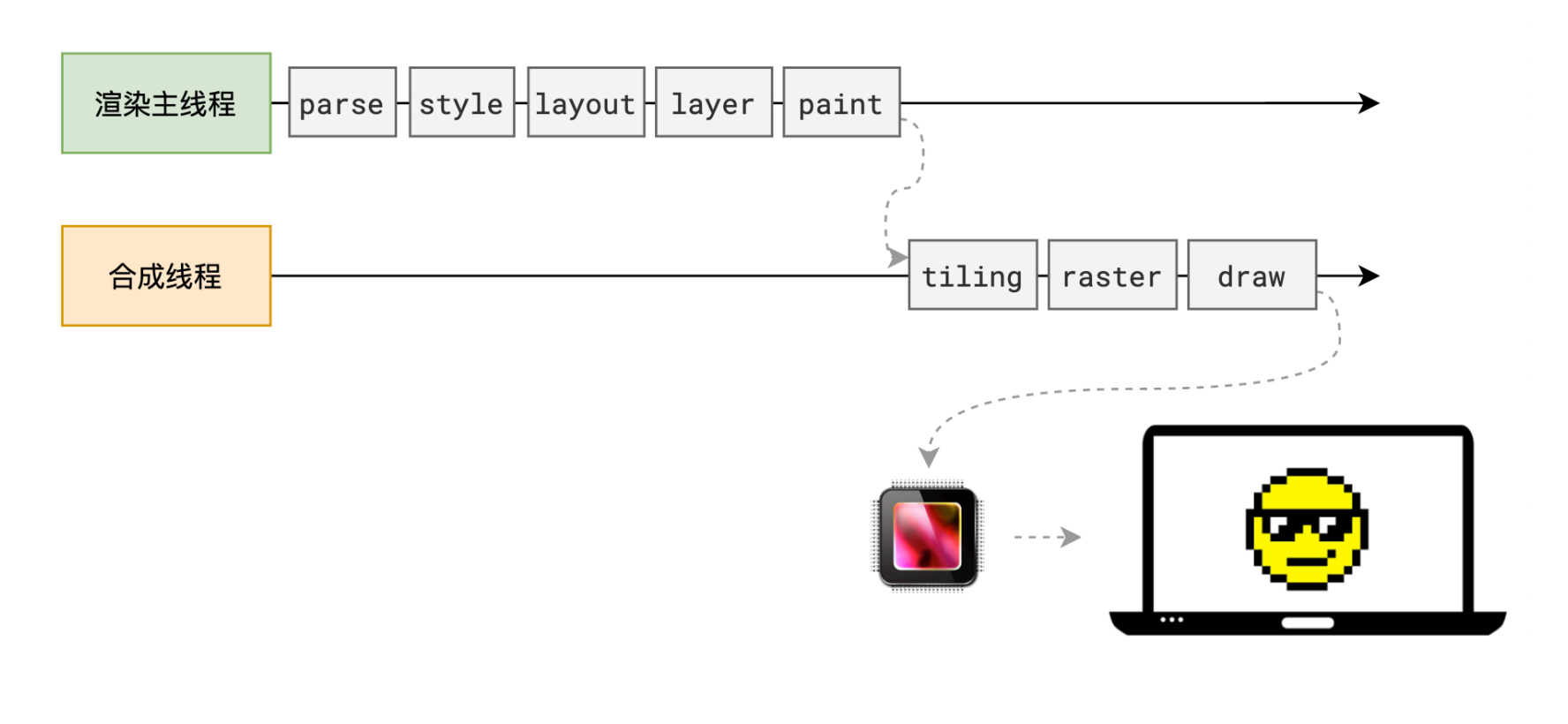
另外,还有一个重要的点需要知道,生成绘制指令集后,渲染主线程的工程就暂时告一段落,接下来主线程将每个图层的绘制信息提交给合成线程,剩余工作将由合成线程完成。
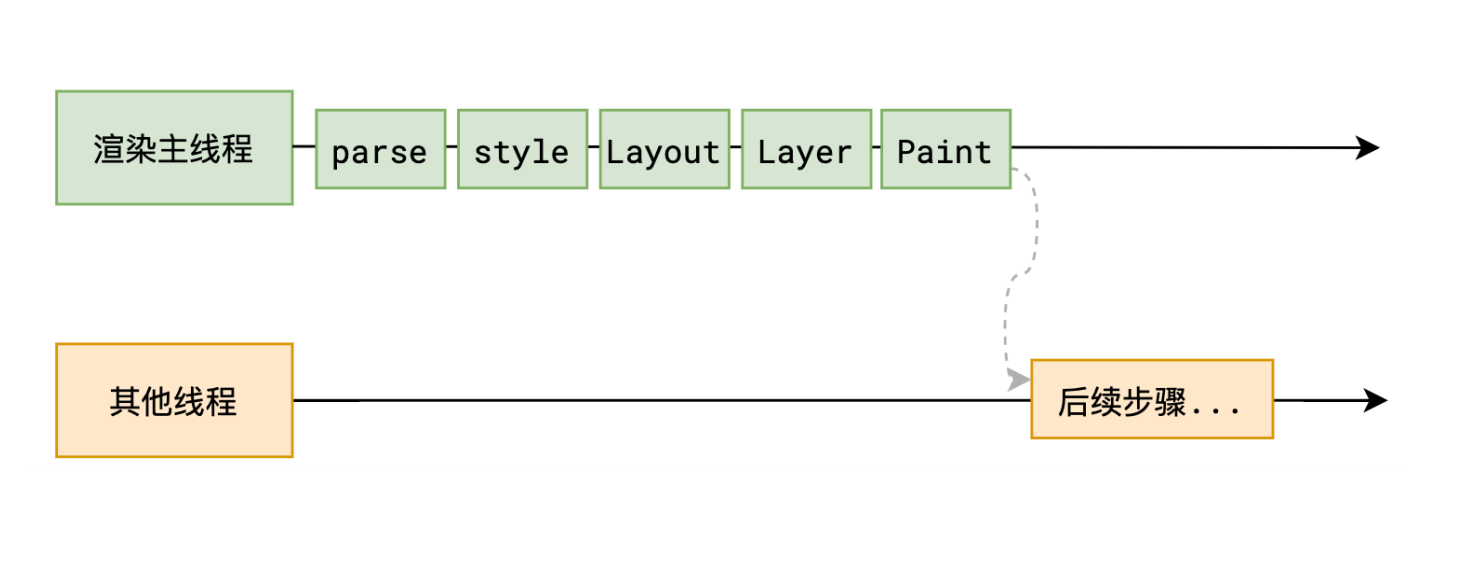
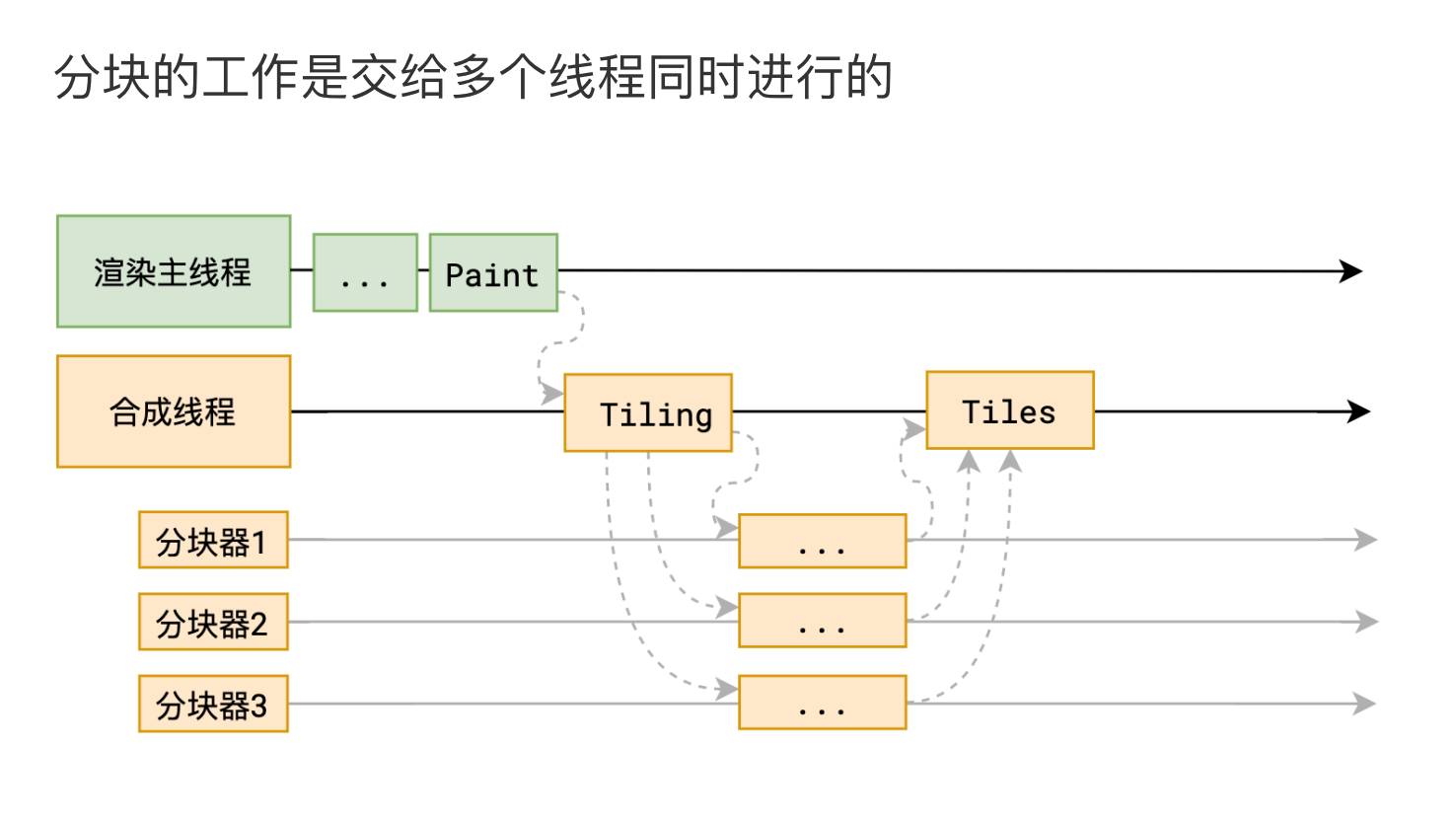
第六步:分块
输入:每个层的绘制指令集
输出:块信息
参与者:合成线程、若干分块器
合成线程首先对每个图层进行分块,将其划分为更多的小区域。
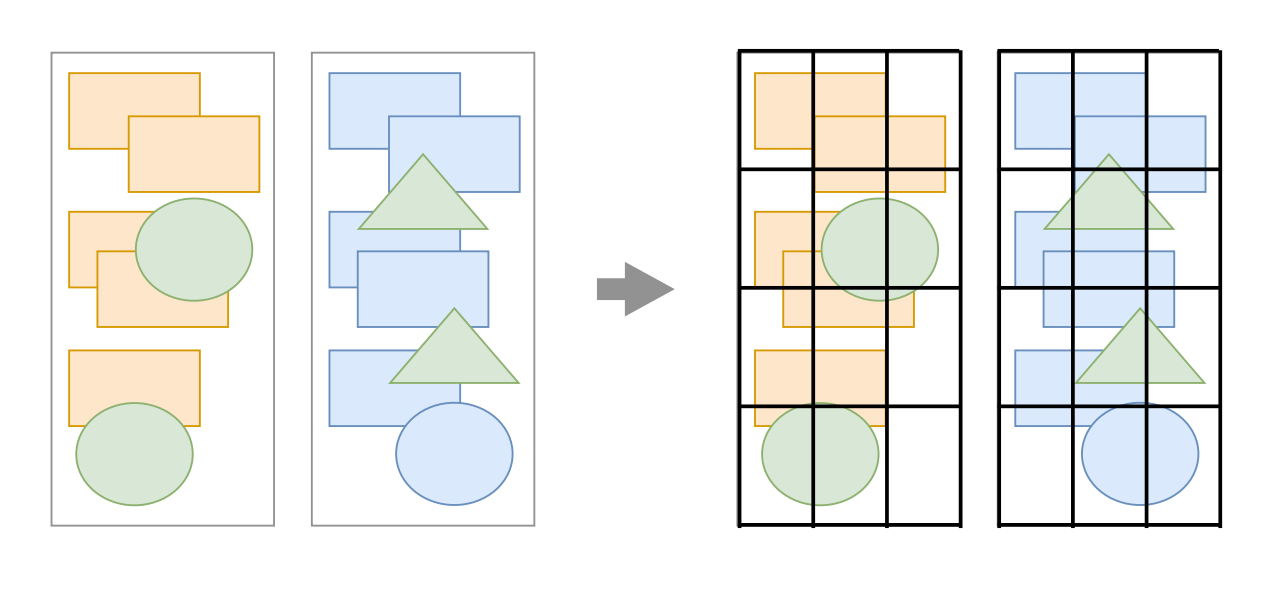
此时,它不再是像主线程那样一个人在战斗,它会从线程池中拿取多个线程来完成分块工作。
第七步:光栅化
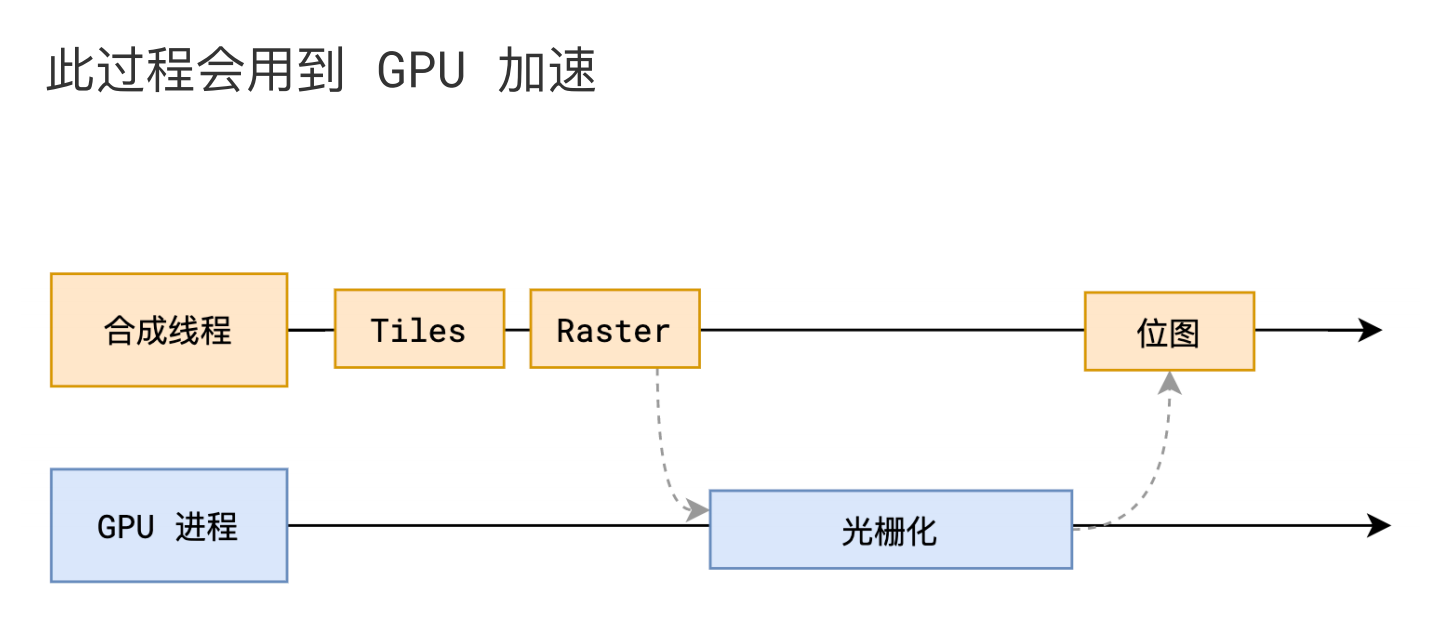
输入:块信息
输出:位图
参与者:GPU 进程、GPU 进程中若干线程
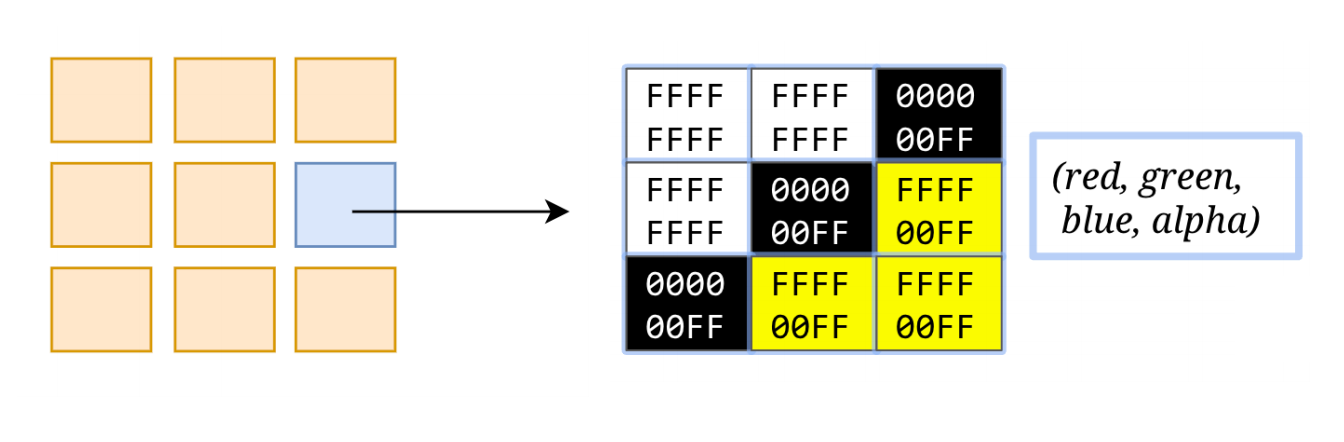
分块完成后,进入光栅化阶段。所谓光栅化,就是将每个块变成位图。
更简单的理解就是确认每一个像素点的 RGBA 信息。
光栅化的操作,并不由合成线程来做,而是会由合成线程将块信息交给 GPU 进程,以极高的速度完成光栅化。
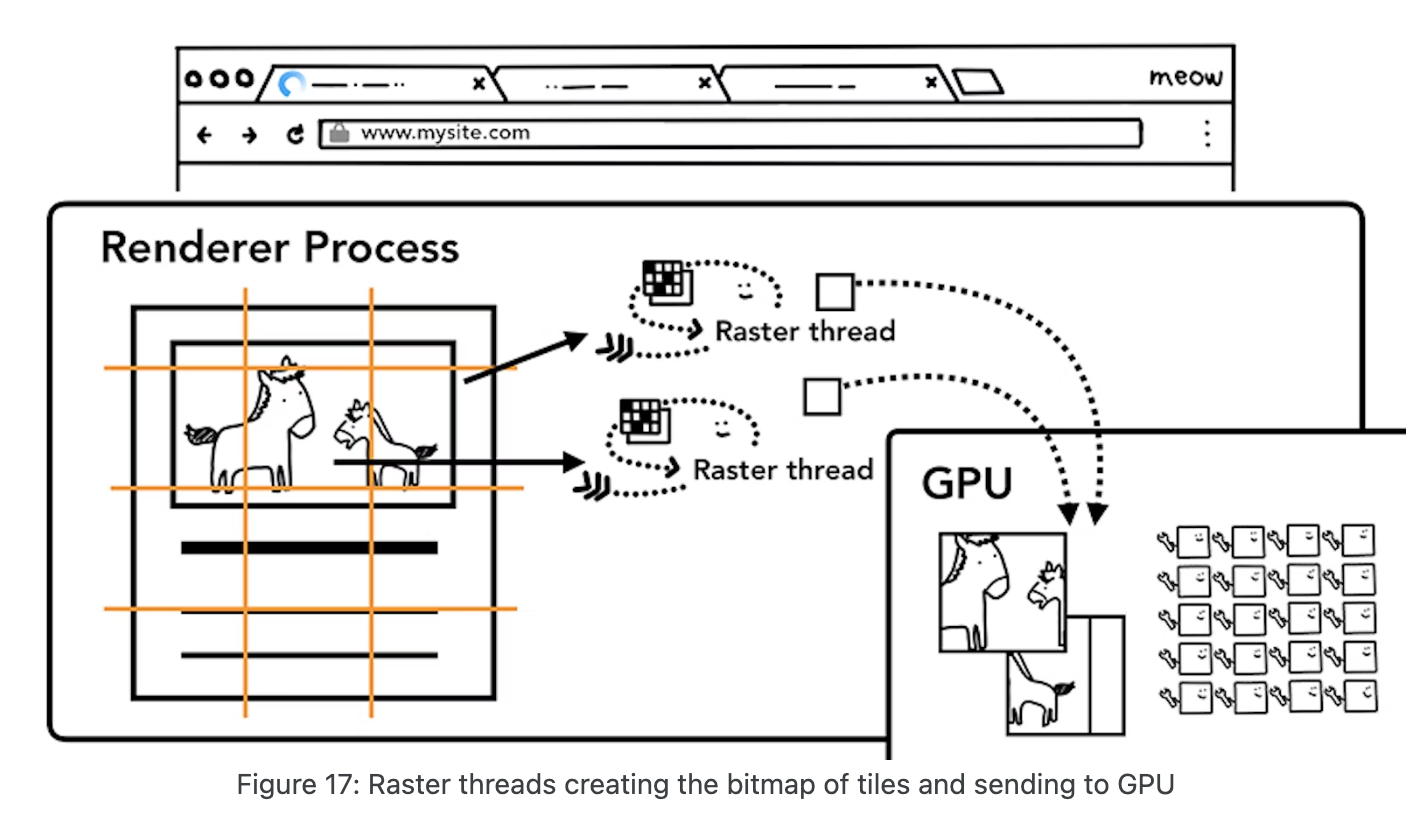
GPU 进程会开启多个线程来完成光栅化,并且优先处理靠近视口区域的块。
第八步:绘制
输入:位图
输出:屏幕成像
参与者:合成线程、浏览器进程、UI 线程、GPU
最后一步,我们总算迎来了真正的绘制。
当所有的图块都被光栅化后,合成线程会拿到每个层、每个块的位图,从而生成一个个「指引(quad)」信息。
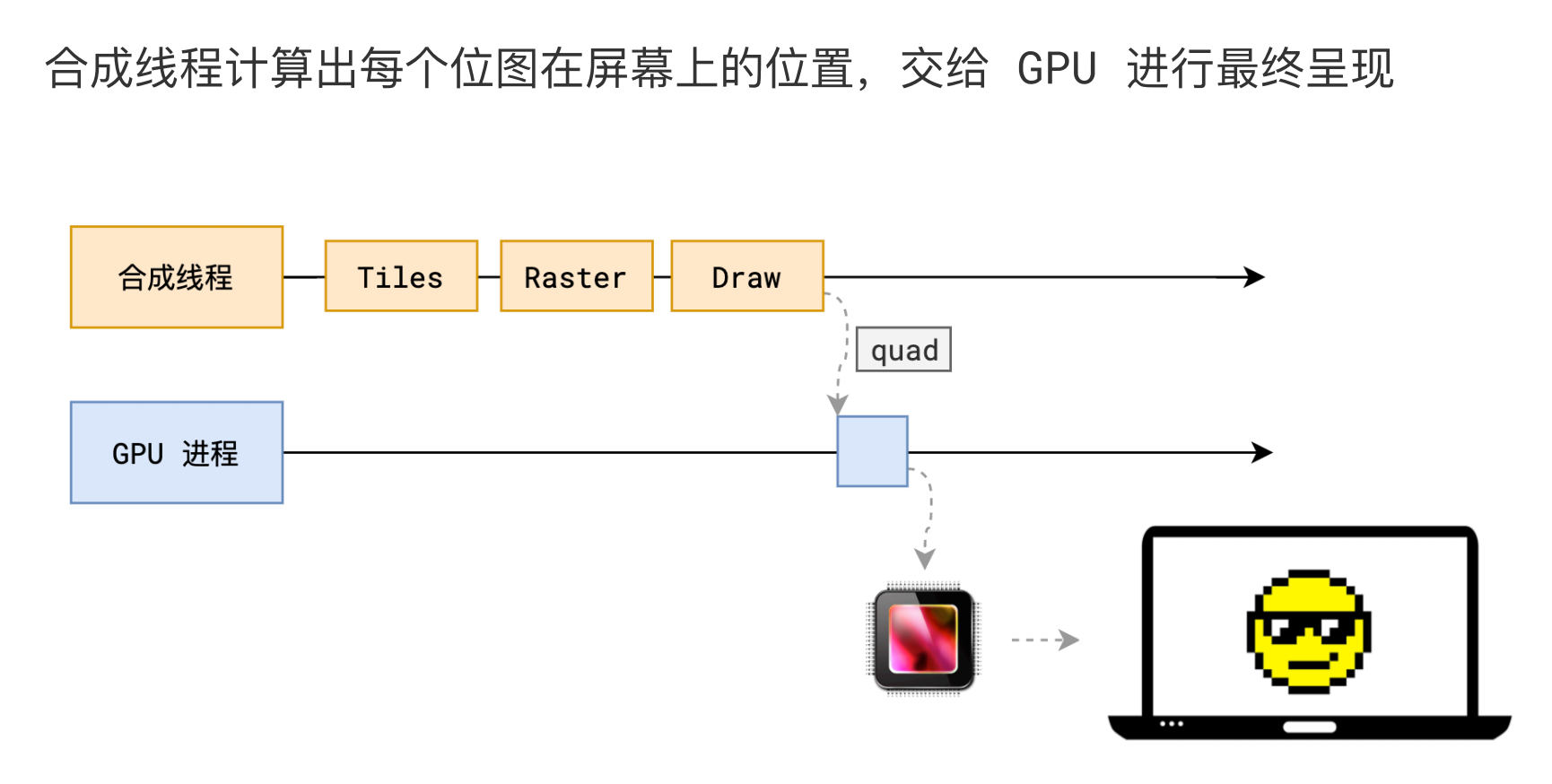
指引会标识出每个位图应该画到屏幕的哪个位置,以及会考虑到旋转、缩放等变形。
变形发生在合成线程,与渲染主线程无关,这就是 transform 效率高的本质原因。
合成线程会通过 IPC 向浏览器进程(browser process)提交(commit)一个渲染帧。这个时候可能有另外一个合成帧被浏览器进程的 UI 线程(UI_thread)提交以改变浏览器的 UI。这些合成帧都会被发送给 GPU 完成最终的屏幕成像。
如果合成线程收到页面滚动的事件,合成线程会构建另外一个合成帧发送给 GPU 来更新页面。
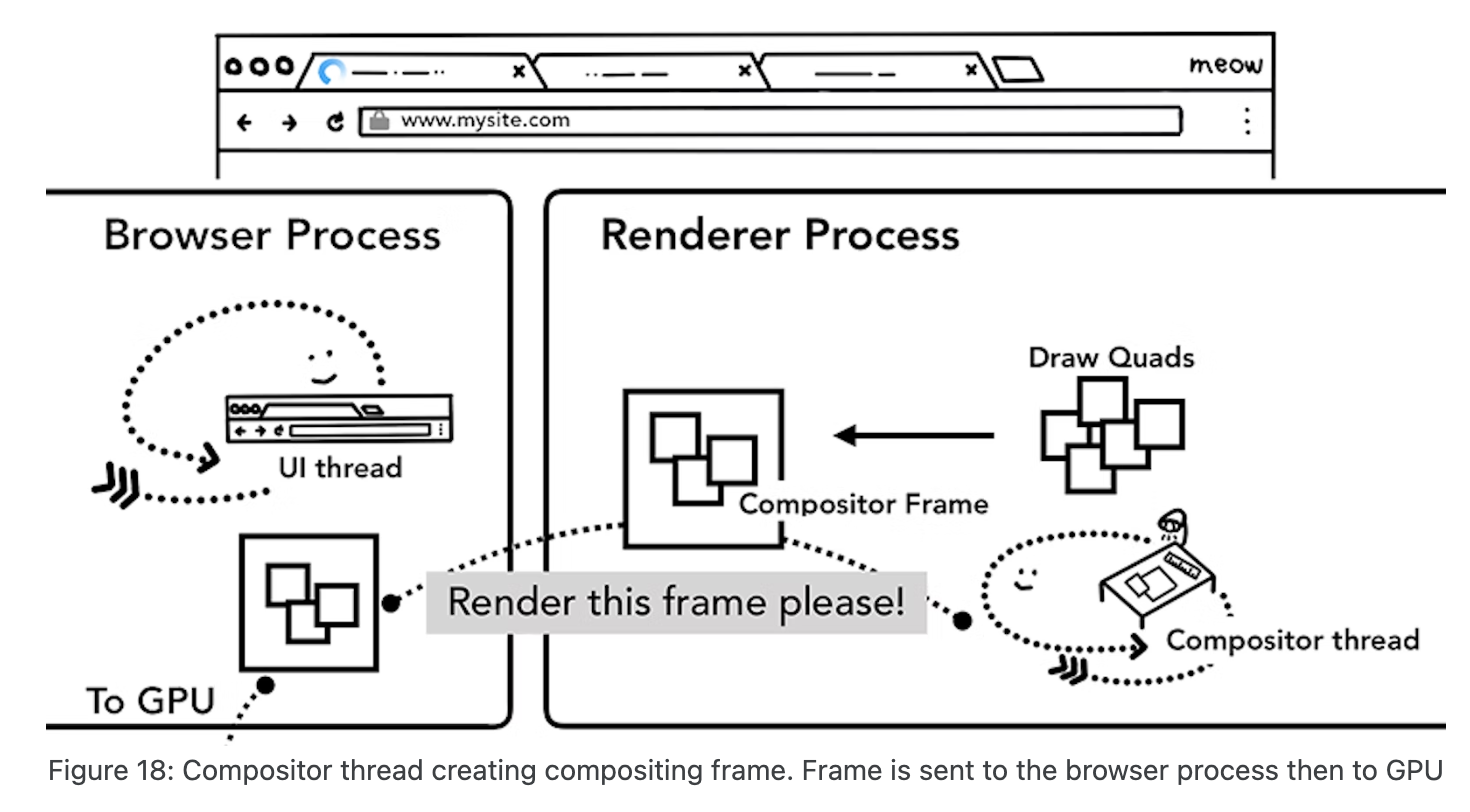
大体流程回顾
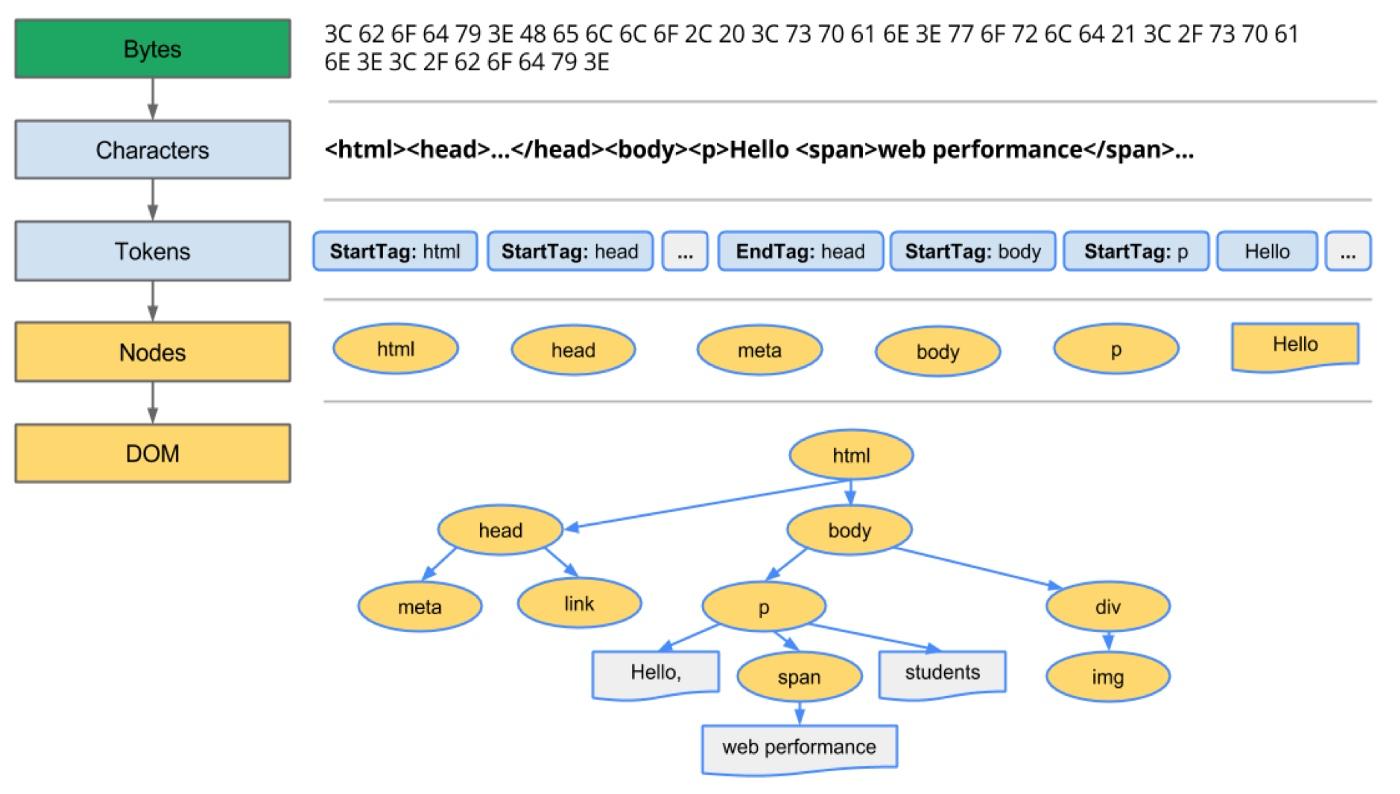
从数据到 DOM
来自网络层的请求内容以二进制流格式在渲染引擎中接收(通常为 8KB 块),然后将原始字节转换为 HTML 文件的字符(基于字符编码)。
然后将字符转换为标记(基于 DOCTYPE)。词法分析器执行词法分析,将输入分解为标记。在标记化期间,文件中的每个开始和结束标记都被考虑在内。它知道如何去除不相关的字符,如空格和换行符。然后解析器进行语法分析,通过分析文档结构,应用语言语法规则来构建解析树。
解析过程是迭代的。它将向词法分析器询问新的标记,如果语言语法规则匹配,则该标记将被添加到解析树中。然后解析器将要求另一个令牌。如果没有规则匹配,解析器将在内部存储令牌并不断询问令牌,直到找到与所有内部存储的令牌匹配的规则。如果未找到规则,则解析器将引发异常。这意味着该文档无效并且包含语法错误。
这些节点在称为 DOM(文档对象模型)的树数据结构中链接,该结构建立了父子关系、相邻兄弟关系。
CSS 数据到 CSSOM
CSS 数据的原始字节被转换成字符、标记、节点,最后在 CSSOM(CSS 对象模型)中。 因为 CSS 存在层叠机制,该机制决定了将什么样式应用于元素,也就是说,元素的样式数据可以来自父项(通过继承)或设置为元素本身。因此浏览器必须递归遍历 CSS 树结构并确定特定元素的样式。
DOM 和 CSSOM 合成渲染树
DOM 树包含有关 HTML 元素关系的信息,而 CSSOM 树包含有关如何设置这些元素样式的信息。
渲染引擎会将样式信息和 HTML 元素关系信息进行汇总,用于创建另一棵树,称为“渲染树”。
渲染树包含具有视觉属性(如颜色和尺寸)的矩形。矩形按正确的顺序显示在屏幕上。
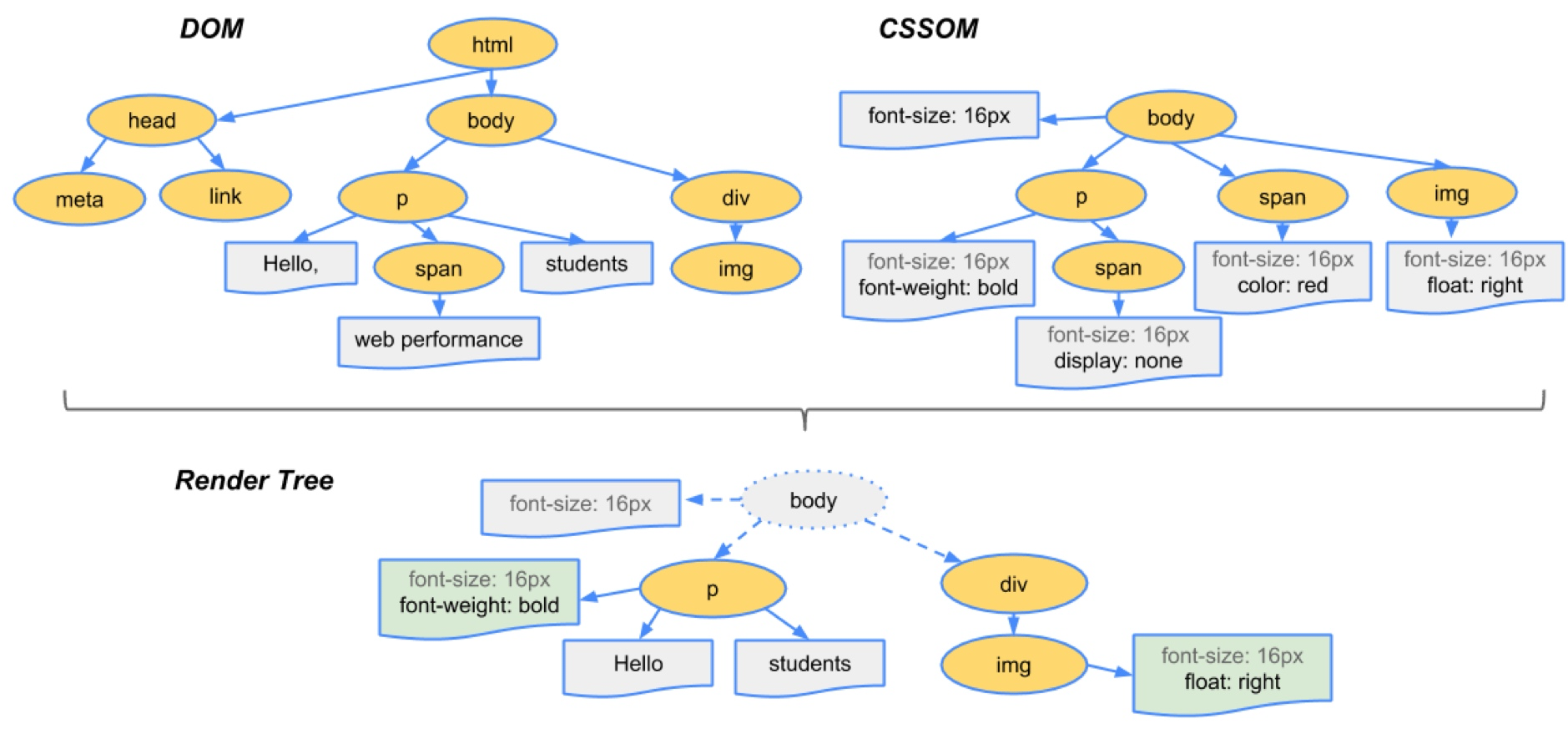
布局
在构建渲染树之后,它会经历一个“布局”过程。布局过程的输出是一个“盒子模型”,它精确地捕获视口内每个元素的确切位置和大小:所有相对测量值都转换为屏幕上的绝对像素。
在下面的屏幕截图中,您可以看到为 body 元素计算的“盒子模型”(边距、边框、填充、宽度和高度)信息。
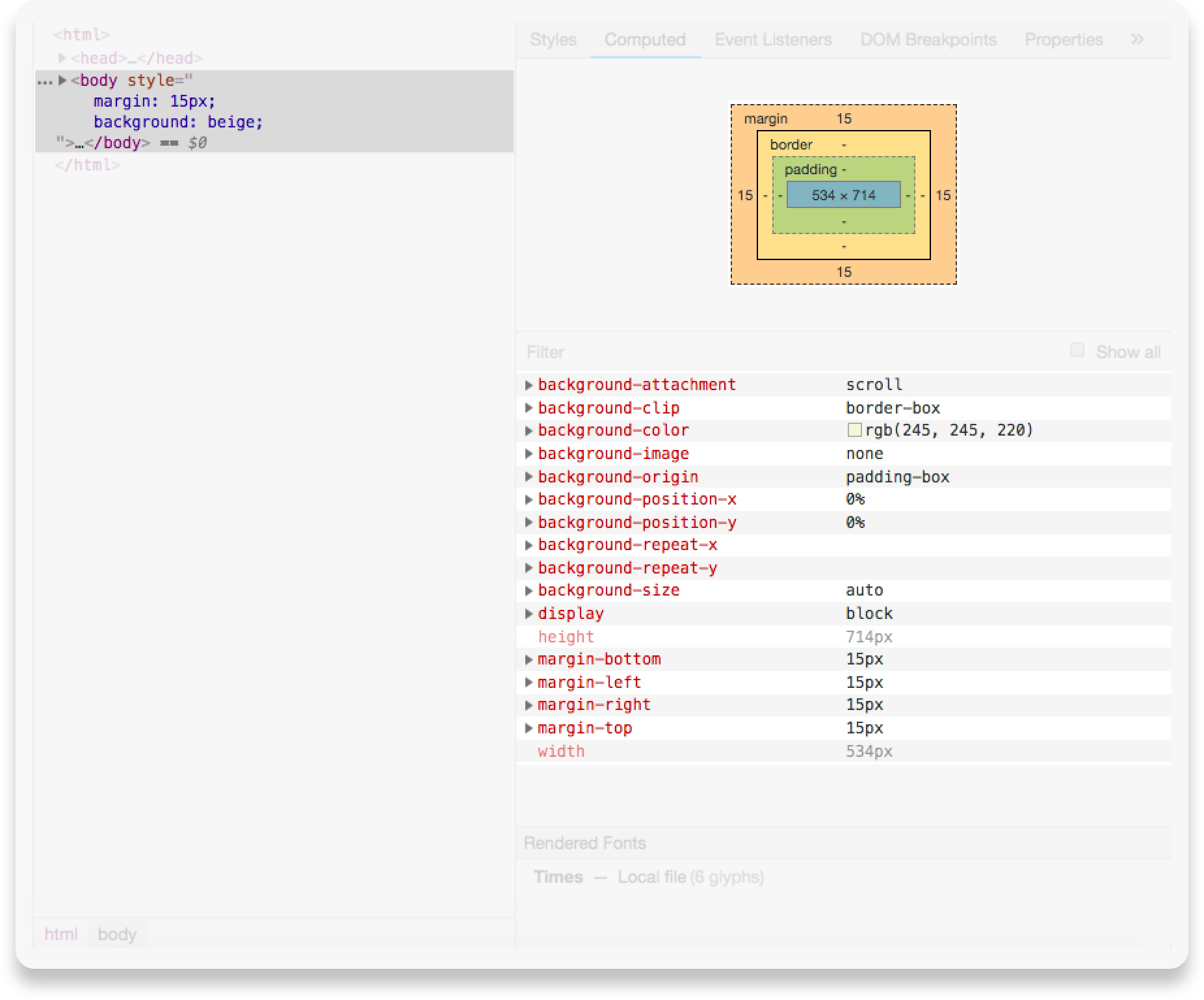
绘制
在这一阶段渲染树会被遍历,并且会只用 UI 后端层绘制每个节点。这个过程也被称为“光栅化”。在这个阶段,渲染树中每个节点的计算布局信息被转换为屏幕上的实际像素。
绘画是一个渐进的过程,其中一些部分被解析和渲染,而该过程继续处理来自网络的项目的其余部分。
整体流程图
常见面试题
什么是 Reflow?
Reflow(回流、重排)的本质就是重新计算 layout 树。
当进行了会影响布局树的操作(margin、padding、border-width、width、height 等)后,需要重新计算布局树,引发 layout。
浏览器优化:为了避免连续的多次操作导致布局树反复计算,浏览器会合并这些操作,当 JS 代码全部完成后再进行统一计算。所以,改动属性造成的 Reflow 是异步完成的。
代码会导致浏览器优化失效:也同样因为如此,当 JS 获取布局属性时,就可能造成无法获取到最新的布局信息。浏览器在反复权衡下,最终决定获取属性立即 Reflow。
什么是 Repaint?
Repaint(重绘)的本质就是重新根据分层信息计算了绘制指令。
当改动了可见样式后,就需要重新计算,会引发 Repaint。
由于元素的布局信息也属于可见样式,所以 Reflow 一定会引起 Repaint。
为什么 transform 的效率高?
因为 transform 既不会影响布局也不会影响绘制指令,它影响的只是渲染流程的最后一个绘制(draw)阶段
由于 draw 阶段在合成线程中,所以 transform 的变化几乎不会影响渲染主线程。反之,渲染主线程无论如何忙碌,也不会影响 transform 的变化。
如下代码,两个小球移动动画,一个通过 transform,一个通过 left,当渲染主线程忙时(执行死循环)transform 动画正常、left 动画卡死:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
.ball {
width: 100px;
height: 100px;
background: #f40;
border-radius: 50%;
margin: 30px;
}
.ball1 {
animation: move1 1s alternate infinite ease-in-out;
}
.ball2 {
position: fixed;
left: 0;
animation: move2 1s alternate infinite ease-in-out;
}
@keyframes move1 {
to {
transform: translate(100px);
}
}
@keyframes move2 {
to {
left: 100px;
}
}
</style>
</head>
<body>
<button id="btn">死循环</button>
<div class="ball ball1"></div>
<div class="ball ball2"></div>
<script>
function delay(duration) {
var start = Date.now();
while (Date.now() - start < duration) {}
}
btn.onclick = function () {
delay(5000);
};
</script>
</body>
</html>