设置了索引并不意味着查询时会使用到,所以要清楚有哪些情况会导致索引失效,从而避免写出索引失效的查询语句
实际过程中,除了下面的情况还可能会出现其他的索引失效场景,需要查看执行计划,通过执行计划显示的数据判断查询语句是否使用了索引
使用左或左右模糊匹配
使用左或左右模糊匹配时(like %xx 或 like %xx%),会造成索引失效
因为索引 B+Tree 是按照「索引值」有序排列存储的,只能根据前缀进行比较
使用函数
因为索引保存的是索引字段的原始值,而不是经过函数计算后的值,自然就没办法走索引了
不过,从 MySQL 8.0 开始,索引特性增加了函数索引,即可以针对函数计算后的值建立一个索引,也就是说该索引的值是函数计算后的值,就可以通过扫描索引来查询数据
如:
# 对 length(name) 的计算结果建立一个名为 idx_name_length 的索引
table t_user add key idx_name_length ((length(name)));进行表达式计算
如,下面这条查询语句,索引会失效:
select * from t_user where id + 1 = 10;改成这样就可以走索引了:
select * from t_user where id = 10 - 1;MySQL 为什么没有帮忙转换?
可能是因为表达式计算的情况多种多样,每种都要考虑的话,代码可能会很臃肿,所以干脆让程序员自己保证
隐式类型转换
# phone 的类型为 varchar,用整型查询,索引失效
select * from t_user where phone = 1300000001;
# 但是,id 的类型为整型,用字符串查询,索引不会失效
select * from t_user where id = '1';这是因为 MySQL 隐式类型转换规则:遇到字符串和数字比较时,会自动把字符串转为数字,然后再进行比较
# 第一个语句相当于
select * from t_user where CAST(phone AS signed int) = 1300000001;
# 第二个语句相当于
select * from t_user where id = CAST("1" AS signed int);联合索引非最左匹配
联合索引范围查询
联合索引的最左匹配原则,在遇到范围查询(如:>、<)时,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引
但是,对于 >=、<=、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配
例一:
select * from t_table where a > 1 and b = 2
- 联合索引(二级索引)先按照
a字段的值排序,所以符合a > 1条件的二级索引记录肯定相邻,可以使用索引 - 但是在符合
a > 1条件的二级索引记录的范围内,b字段的值是无序的,无法使用索引

例二:
select * from t_table where a >= 1 and b = 2
- 联合索引(二级索引)先按照
a字段的值排序,所以符合a >= 1条件的二级索引记录肯定相邻,可以使用索引 - 虽然在符合
a >= 1条件的二级索引记录的范围里,b字段的值是「无序」的- 但对于符合
a = 1的二级索引记录的范围里,b字段的值是「有序」的,可以使用索引 - 而对于符合
a > 1的二级索引记录的范围里,b字段的值是「无序」的,无法使用索引
- 但对于符合

例三:
SELECT * FROM t_table WHERE a BETWEEN 2 AND 8 AND b = 2
a BETWEEN 2 AND 8 是查询 a 字段的值在 2 和 8 之间的记录,不同的数据库的处理方式有差异:
- MySQL:BETWEEN 包含边界值,类似于
>= and <= - 有些数据库:不包含边界值,类似于
> and <

例四:
SELECT * FROM t_user WHERE name like 'j%' and age = 22
联合索引(二级索引)是先按照 name 字段的值排序的,所以前缀为 'j' 的 name 字段的二级索引记录都是相邻的,于是在进行索引扫描时,可以定位到符合前缀的第一条记录,然后沿着记录所在的链表向后扫描,直到某条记录前缀不符合为止,形成的扫描区间是 ['j', 'k')
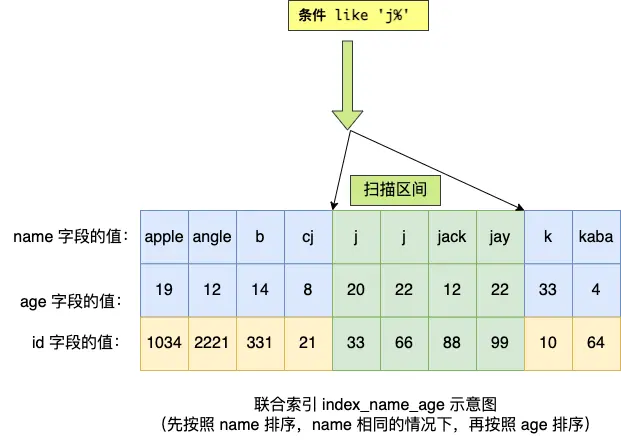
虽然在符合前缀为 'j' 的 name 字段的二级索引记录的范围里,age 字段的值是「无序」的,但是对于符合 name = 'j' 的二级索引记录的范围里,age 字段的值是「有序」的

name字段的类型是varchar(30)且不为 NULL,数据库表使用了 utf8mb4 字符集,一个字符占 4 个字节,因此name字段的实际数据最多占用的存储空间长度是 120 字节,又因为name是变长类型的字段,需要再加 2 字节(用于存储该字段实际数据的长度值),也就是name的key_len为 122age字段的类型是int且不为 NULL,key_len为 4
Question
name是变长类型的字段,需要再加 2 字节?之前说「如果变长字段允许存储的最大字节数小于等于 255 字节,就会用 1 字节表示变长字段的长度」,而这里为什么是 2 字节?
因为
key_len的显示比较特殊,行格式是由 InnoDB 存储引擎实现的,而执行计划是在 server 层生成的,所以它不会去问 InnoDB 存储引擎可变字段的长度占用多少字节,而是不管三七二十一都使用 2 字节表示可变字段的长度
索引下推
对于联合索引 (a, b),在执行 select * from table where a > 1 and b = 2 时,只有 a 字段能用到索引,那在联合索引的 B+Tree 找到第一个满足条件的主键值后,还需要判断其他条件是否满足(b = 2),是在联合索引里判断?还是回主键索引去判断呢?
- MySQL 5.6 之前,只能从第一个满足条件的主键值开始一个个回表,到「主键索引」上找出数据行,再对比
b字段值 - 而 MySQL 5.6 引入的索引下推优化(index condition pushdown),可以在联合索引遍历过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数
当查询语句的执行计划里,出现了 Extra 为 Using index condition,那么说明使用了索引下推的优化
WHERE 子句中的 OR
在 WHERE 子句中,如果在 OR 的条件中只要有一个不是索引列,其他条件中的索引都会失效
因为 OR 的含义就是只要满足一个即可,因此只要有条件列不是索引列,就会进行全表扫描