哪种 count() 性能最好?
count() 是一个聚合函数,函数的参数可以是字段名或其他任意表达式,作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录有多少个
在通过 count() 函数统计有多少个记录时,server 层会维护一个名叫 count 的变量。server 层会循环向 InnoDB 读取一条记录,如果 count() 函数指定的参数不为 NULL,就会将变量 count++,直到符合查询的全部记录被读完,退出循环,最后将 count 变量的值发送给客户端
按照性能排序:count(*) = count(1) > count(主键) > count(普通字段)
count(主键)
如果表里只有主键索引,没有二级索引时,使用主键索引:
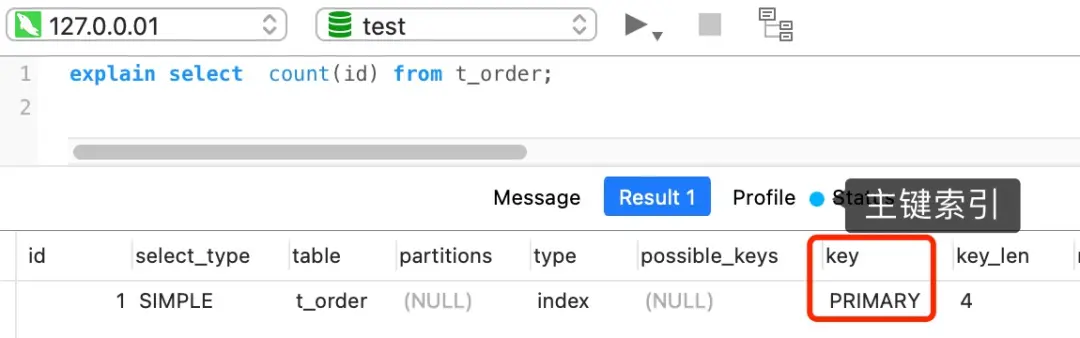
但是,如果表里有二级索引时,InnoDB 循环遍历的对象就不是聚簇索引,而是二级索引:
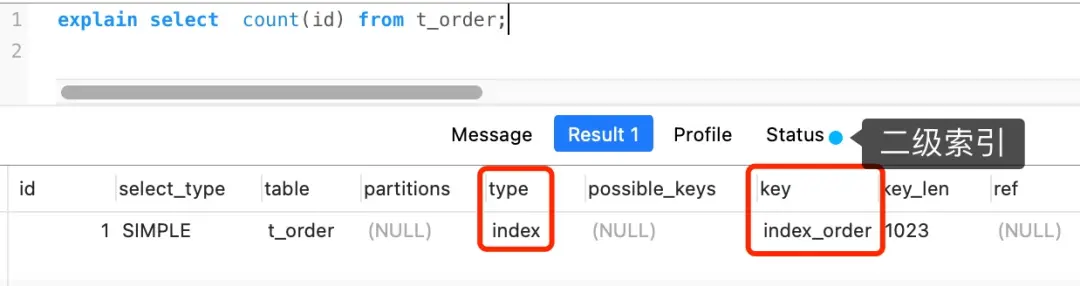
这是因为相同数量的二级索引记录可以比聚簇索引记录占用更少的存储空间,所以二级索引树比聚簇索引树小,遍历二级索引的 I/O 成本比遍历聚簇索引的 I/O 成本小,因此「优化器」优先选择的是二级索引
InnoDB 循环遍历索引,将读取到的记录返回给 server 层,server 层读取记录中的 id 值,判断是否为 NULL,如果不为 NULL,就将变量 count++
count(1)
1 这个表达式就是单纯数字,它永远都不是 NULL,所以其实就是在统计表中有多少个记录
同理,如果表里只有主键索引,没有二级索引就使用主键索引;有二级索引则使用二级索引
但是 InnoDB 循环遍历索引,将读取到的记录返回给 server 层,server 层不会读取记录中的任何值,因为 count() 函数的参数是 1,不是字段,不需要读取记录中的字段值。参数 1 很明显不是 NULL,因此 server 层每从 InnoDB 读取到一条记录,就直接将变量 count++
count(*)
看到 * 这个字符时,是不是觉得是读取记录中的所有字段值?
但其实不是,当使用 count(*) 时,MySQL 会将 * 转化为 0 来处理,即:count(*) 等同于 count(0),也即等同于 count(1)
而且 count(*) 和 count(1) 有个优化:如果有多个二级索引时,优化器会使用 key_len 最小的二级索引进行扫描
count(普通字段)
性能最差,需要全表扫描
为什么要通过遍历的方式来计数?
前面的案例都是基于 Innodb 存储引擎来说明的,但在 MyISAM 存储引擎中,执行 count 函数的方式是不一样的
通常在没有任何查询条件下的 count(),MyISAM 的查询速度要明显快于 InnoDB,这是因为每张 MyISAM 的数据表都有一个 meta 信息存储了 row_count 值,由表级锁保证一致性,直接读取 row_count 值就是 count 函数的执行结果
这是因为 MyISAM 没有事务,而 InnoDB 支持事务,同一个时刻的多个查询,由于 MVCC(多版本并发控制)的原因,InnoDB 表“应该返回多少行”是不确定的,所以无法像 MyISAM 一样,只维护一个 row_count 变量
而当带上条件语句之后,MyISAM 跟 InnoDB 就没有区别了,都需要扫描表来进行记录个数的统计
如何优化 count(*)?
如果对一张大表经常用 count(*) 来做统计,其实是比较慢的
如表共有 1200+ 万条记录,也创建了二级索引,但是执行一次 select count(*) from t_order 要花费差不多 5 秒!
解决方法有:
大概值
如果业务对于统计个数不需要很精确,如:搜索引擎在搜索关键词时,给出的搜索结果条数是一个大概值
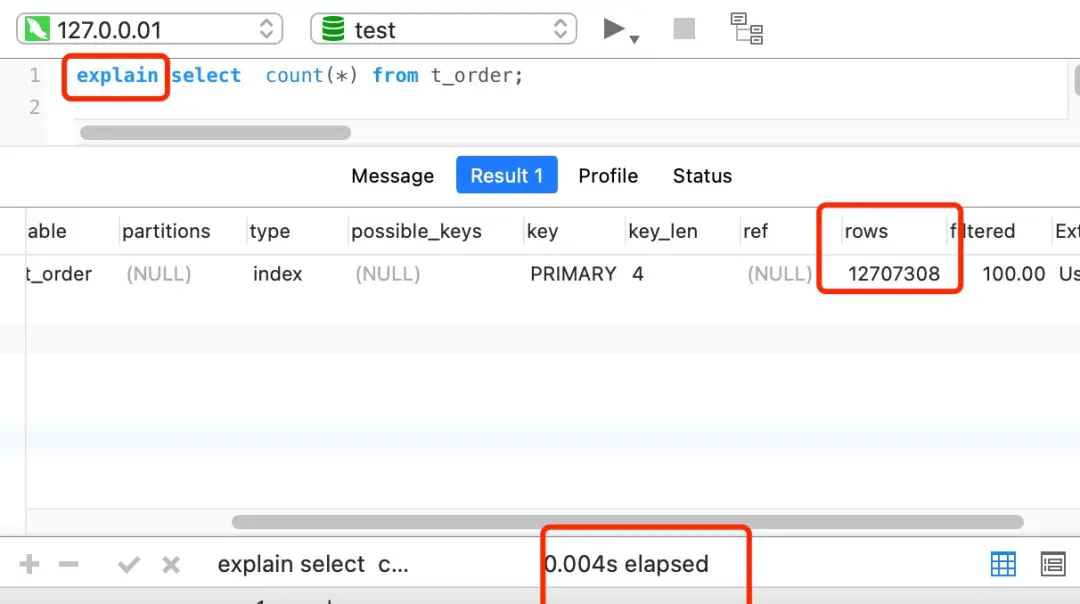
可以使用 show table status 或 explain 命令来进行估算。执行 explain 效率是很高的,因为它并不会真正去查询,而是一个估算值:
额外表保存计数值
如果是想精确的获取表的记录总数,可以将这个计数值保存到单独的一张计数表中,在新增和删除时,需要额外维护这个计数表