介绍
Stream(流)是 Redis 5.0 版本新增的数据类型,专门为消息队列设计的数据类型
在 Redis 5.0 Stream 没出来前,消息队列的实现方式都有着各自的缺陷,如:
基于以上问题,Redis 5.0 推出了 Stream,用于完美地实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠
常见命令
Stream 消息队列操作命令:
XADD:插入消息,保证有序,可以自动生成全局唯一 IDXLEN:查询消息长度XREAD:用于读取消息,可以按 ID 读取数据XDEL: 根据消息 ID 删除消息DEL:删除整个 StreamXRANGE:读取区间消息XREADGROUP:按消费组形式读取消息XPENDING:查询每个消费组内所有消费者「已读取、但尚未确认」的消息XACK:向消息队列确认消息处理已完成
应用场景
消息队列
生产者通过 XADD 命令插入一条消息:
# 往 mymq Stream 中插入一条消息,消息的键是 name,值是 xiaolin
# 其中 * 表示让 Redis 为插入的数据自动生成一个全局唯一的 ID
> XADD mymq * name xiaolin
"1654254953808-0"插入成功后会返回全局唯一的 ID,其由两部分组成:
- 第一部分“1654254953808”是数据插入时,以毫秒为单位的当前服务器时间
- 第二部分表示插入消息在当前毫秒内的消息序号(从 0 开始编号)
消费者通过 XREAD 命令从消息队列中读取消息,可以指定一个消息 ID,并从这个消息 ID 的下一条消息开始进行读取:
# 从 ID 号为 1654254953807-0 的消息开始,读取后续的所有消息(示例中一共 1 条)
> XREAD STREAMS mymq 1654254953807-0
1) 1) "mymq"
2) 1) 1) "1654254953808-0"
2) 1) "name"
2) "xiaolin"阻塞读:
# 阻塞 10000 毫秒(10 秒)读取消息
# 其中 $ 表示读取最新的消息
> XREAD BLOCK 10000 STREAMS mymq $
(nil)
(10.00s)Stream 消息队列的交互流程是:生产者使用 XADD 存入消息,消费者使用 XREAD 循环阻塞读取消息
消费组
创建消费组:
# 创建一个名为 group1 的消费组,0-0 表示从第一条消息开始读取
> XGROUP CREATE mymq group1 0-0
OK
# 创建一个名为 group2 的消费组,0-0 表示从第一条消息开始读取
> XGROUP CREATE mymq group2 0-0
OK消费组读取消息:
# 消费组 group1 内的消费者 consumer1 从 mymq 消息队列中读取所有消息
# 其中 > 表示从第一条尚未被消费的消息开始读取。
> XREADGROUP GROUP group1 consumer1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1654254953808-0"
2) 1) "name"
2) "xiaolin"消息队列中的消息一旦被消费组中的一个消费者读取,就不能再被该消费组内的其他消费者读取,即:同一个消费组中的消费者不能消费同一条消息
但是,不同消费组的消费者可以消费同一条消息(前提条件:创建消息组时,不同消费组指定了相同位置开始读取消息)
# 相同消费组读取不到消息了
> XREADGROUP GROUP group1 consumer1 STREAMS mymq >
(nil)
# 另一个消费组还能读取同一条消息
> XREADGROUP GROUP group2 consumer1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1654254953808-0"
2) 1) "name"
2) "xiaolin"保证消息可靠性
如何保证消费者在发生故障或宕机再次重启后,仍然可以读取未处理完的消息?
消费确认机制:
- Stream 会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,直到消费者使用
XACK命令通知 Stream “消息已经处理完成” - 如果消费者没有成功处理消息,就不会给 Stream 发送
XACK命令,消息仍然会留存。此时,==消费者可以在重启后,用XPENDING命令查看已读取、但尚未确认处理完成的消息==
# 查看 group2 中各个消费者已读取、但尚未确认的消息
> XPENDING mymq group2
1) (integer) 3
2) "1654254953808-0" # 表示 group2 中所有消费者读取的消息最小 ID
3) "1654256271337-0" # 表示 group2 中所有消费者读取的消息最大 ID
4) 1) 1) "consumer1"
2) "1"
2) 1) "consumer2"
2) "1"
3) 1) "consumer3"
2) "1"
# 查看消费组中的某个消费者已读取、但尚未确认的消息
> XPENDING mymq group2 - + 10 consumer2
1) 1) "1654256265584-0"
2) "consumer2"
3) (integer) 410700
4) (integer) 1
# 处理完成后使用 XACK 命令通知 Stream,然后这条消息就会被删除
> XACK mymq group2 1654256265584-0
(integer) 1与专业消息队列的差距
一个专业的消息队列,需要做到:
- 消息不丢
- 消息可堆积
Redis Stream 消息会丢失吗?
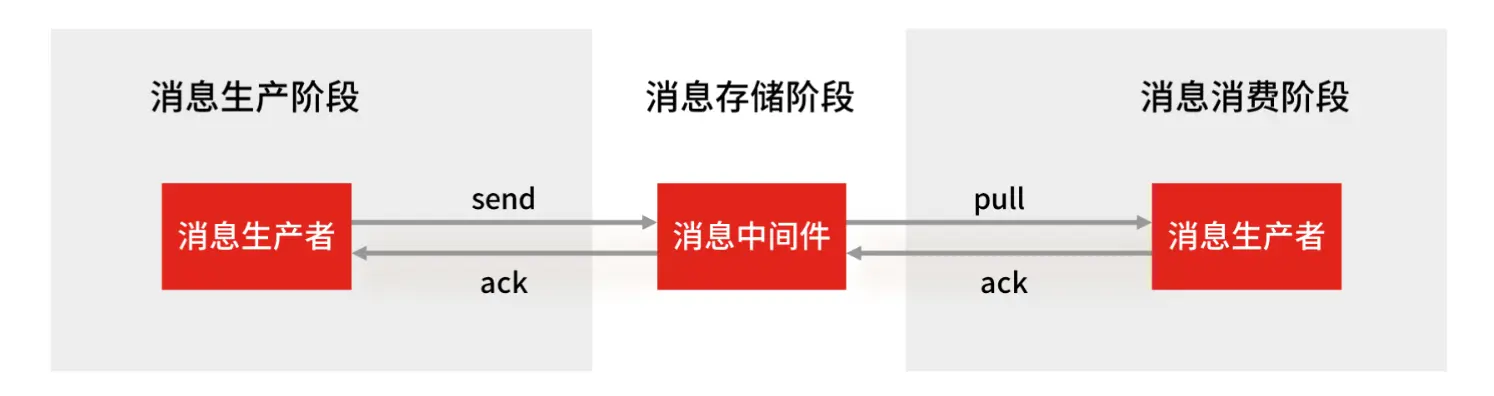
- 生产者:不会丢失消息
- 生产者发送数据给 Stream,Stream 收到消息会 ack 确认响应,只要能收到 ack 就表示发送成功
- 生产者程序只要处理好返回值和异常,如果返回异常则进行消息重发,就不会出现消息丢失
- 消费者:不会丢失消息
- Stream 会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,消费者没有 ack 则留存消息
- 消费者没有成功处理消息时,可以在重启后,用
XPENDING命令查看已读取、但尚未确认处理完成的消息 - 消费者正确执行完业务逻辑后,再发送 ack 确认,能保证消息不丢失
- 消息中间件(Stream):可能会丢失消息,2 种场景:
- AOF 持久化配置为每秒写盘,写盘过程是异步的,Redis 宕机时会存在数据丢失的可能
- 主从复制也是异步的,主从切换时,也存在丢失数据的可能
可以看到,Redis 在队列中间件环节无法保证消息不丢。像 RabbitMQ、Kafka 这类专业的消息队列中间件,在使用时是部署一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,也就是有多个副本,这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失
Redis Stream 消息可堆积吗?
Redis 的数据都存储在内存中,一旦发生消息积压,内存持续增长,如果超过机器内存上限,就会面临 OOM 风险
所以 Redis 的 Stream 提供了可以指定队列最大长度的功能,当指定队列最大长度时,超出时旧消息会被删除,只保留固定长度的新消息。这么来看,Stream 在消息积压时,有可能丢失消息
但 RabbitMQ、Kafka 专业消息队列的数据存储在磁盘上,当消息积压时,无非就是多占用一些磁盘空间,不会丢失消息