MoreKey
MoreKey:操作的 key 很多
keys * 这个指令没有 offset、 limit 参数,是要一次性吐出所有满足条件的 key,由于 Redis 是单线程的,keys 算法是遍历算法,复杂度是 O(n),如果实例中有千万级以上的 key,这个指令就会导致 Redis 服务卡顿,所有读写 Redis 的其它的指令都会被延后甚至会超时报错,可能会引起缓存雪崩甚至数据库宕机
生产上如何限制
keys *、flushdb、flushall等危险命令以防止误删误用?
// redis.conf
rename-command keys ""
rename-command flushdb ""
rename-command flushall ""不用
keys *,那该用什么?
SCAN <cursor> [MATCH <pattern>] [COUNT <count>]
- 基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程
- 以 0 作为游标开始一次新的迭代,直到命令返回游标 0 完成一次遍历
- 支持模糊查询
- 一次返回的数量不可控,只能大概符合
count - 返回包含两个元素的数组:
- 第一个元素:用于进行下一次迭代的新游标,如果新游标返回零表示迭代已结束
- 第二个元素:是一个数组,包含了所有被迭代的元素
- 遍历顺序:
- 不是从第一维数组的第 0 位一直遍历到末尾
- 而是采用了高位进位加法来遍历
- 考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏
BigKey
BigKey:数据量比较大的 key-value 键值对
多大算 Big?
参考《阿里云 Redis 开发规范》
- String:
>=10KB - List、Hash、Set、Zset:元素超过 5000
对持久化的影响
AOF 日志
Always写回策略:主线程执行fsync()函数阻塞的时间会比较久。因为当写入的数据量很大时,同步到硬盘的过程比较耗时Everysec写回策略:异步执行fsync()函数,不会影响主线程No写回策略:永不执行fsync()函数,不会影响主线程
当 AOF 日志写入大 key,文件会很快变大,就会触发 AOF 重写机制
AOF 重写和 RDB 快照
fork 调用
AOF 重写和 RDB 快照(bgsave),都会通过 fork() 函数创建一个子进程来处理任务
在通过 fork() 函数创建子进程时,虽然不会复制父进程的物理内存,但是内核会把父进程的页表复制一份给子进程,如果页表很大,复制过程是耗时的,那么在执行 fork() 函数时就会阻塞主进程
可以执行 info 命令获取到 latest_fork_usec 指标:
> info
...
latest_fork_usec: 315 # 最近一次 fork 操作耗时
...如果 fork 耗时很大,比如超过 1 秒,则需要做出优化调整:
- 单个实例的内存占用控制在 10 GB 以下,这样
fork就能很快返回 - 如果 Redis 只是当作纯缓存使用,不关心数据安全性问题,可以考虑关闭持久化,就不会调用
fork了 - 在主从架构中,要适当调大
repl-backlog-size,避免因为repl_backlog_buffer不够大,导致主节点频繁全量同步,全量同步时会创建 RDB 文件,也就是会调用fork
写时复制
创建完子进程后,父进程对共享内存中的大 key 进行了修改,内核就会发生写时复制,会把物理内存复制一份,比较耗时,父进程(主线程)就会发生阻塞
信号处理函数
子进程工作完成后,会向主进程发送一条信号(异步的),主进程收到该信号,会调用信号处理函数将 AOF 重写缓冲区中的所有内容追加到新的 AOF 的文件中,如果 AOF 重写缓冲区中有大 key,会比较耗时,阻塞主线程
如果 Linux 开启了内存大页,会影响 Redis 的性能
Linux 内核从 2.6.38 开始支持内存大页机制,该机制支持 2MB 大小的内存页分配,而常规的内存页分配是按 4KB 的粒度执行的
如果采用了内存大页,那么即使只修改 100B 的数据,在发生写时复制后,Redis 也需要拷贝 2MB 的大页;相反,如果是常规内存页机制,只用拷贝 4KB
禁用内存大页(默认就是禁用的):
echo never > /sys/kernel/mm/transparent_hugepage/enabled
其他影响
- 慢查询或工作线程阻塞、客户端阻塞:Redis 执行命令是单线程的,操作大 key 会比较耗时,从客户端视角看,就是很久没有响应
- 引发网络阻塞:传输大 key 产生的网络流量较大,如果一个 key 的大小是 1MB,每秒访问量为 1000,每秒就会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的
- 内存分布不均:集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大
解决大 BigKey
- 最好在设计阶段,就把 BigKey 拆分成一个一个小 key
- 或者,定时检查 Redis 是否存在 BigKey,如果 BigKey 可以删除则进行删除
查找 BigKey
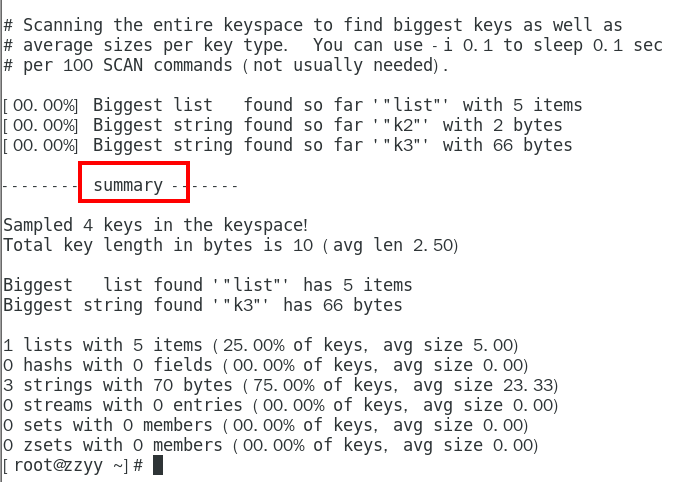
命令一:
redis-cli –-bigkeys
redis-cli –-bigkeys -i 0.1:每隔 100 条 scan 指令就休眠 0.1s,OPS 就不会剧烈抬升,但是扫描的时间会变长
返回:每种数据结构最大的 BigKey,同时给出每种数据类型的键值个数和平均大小
命令二:
MEMORY USAGE <key> [SAMPLES <count>]
返回:该 key-value 数据(及管理该 key)在内存空间所占的字节数
对于嵌套数据类型,可以使用 SAMPLES 指定抽样的元素个数,默认为 5。需要抽样所有元素时,设置为 0
删除 BigKey
- String:一般用
del,如果过于庞大用unlink(详见) - Hash:使用
hscan每次获取少量 field-value,再使用hdel删除每个 field - List:使用
ltrim渐进式逐步删除,直到全部删除完成 - Set:使用
sscan每次获取部分元素,再使用srem命令删除每个元素 - Zset:使用
zscan每次获取部分元素,再使用ZREMRANGEBYRANK命令删除每个元素