为什么要有哨兵机制?
在 Redis 主从架构中,由于主从模式是读写分离的,如果主节点挂了:
- 将没有主节点来服务客户端的写操作请求
- 也没有主节点给从节点进行数据同步
如果想恢复服务,需要人工介入:
- 选择一个「从节点」切换为「主节点」
- 然后让其他从节点指向新的主节点
- 同时还需要通知上游那些连接 Redis 主节点的客户端,将其配置中的主节点 IP 地址更新
Redis 在 2.8 提供的哨兵(Sentinel)机制,它的作用是实现主从节点故障转移:监测主节点是否存活,如果发现主节点挂了,就会选举一个从节点切换为主节点,并且把新主节点的相关信息通知给从节点和客户端
哨兵其实是一个运行在特殊模式下的 Redis 进程,它也是一个节点,主要负责三件事情:监控、选主、通知
如何判断主节点真的故障了?
哨兵会每隔 1 秒给所有主从节点发送 PING 命令,当主从节点收到 PING 命令后,会发送一个响应命令给哨兵,这样就可以判断它们是否在正常运行
如果主节点或从节点没有在规定的时间(配置项 down-after-milliseconds,单位是毫秒)内响应哨兵,哨兵就会将它们标记为「主观下线」
从节点只有「主观下线」;主节点除了「主观下线」还有「客观下线」
因为主节点可能其实并没有故障,只是因为主节点的系统压力比较大或网络发送了拥塞,导致没有在规定时间内响应哨兵的 PING 命令
所以,为了减少误判的情况,一般部署多个哨兵节点组成哨兵集群(最少 3 个,数量应该是奇数),通过多个哨兵节点一起判断,可以避免单个哨兵因为自身网络状况不好,而误判主节点下线的情况
具体怎么判定主节点为「客观下线」呢?
当一个哨兵判断主节点「主观下线」后,就会向其他哨兵发起 is-master-down-by-addr 命令,其他哨兵收到命令后,会根据自身和主节点的网络状况,做出赞成投票或拒绝投票的响应。当赞同票数达到设定值(配置项 quorum,推荐设为哨兵个数的二分之一加 1),主节点就会被该哨兵标记为「客观下线」
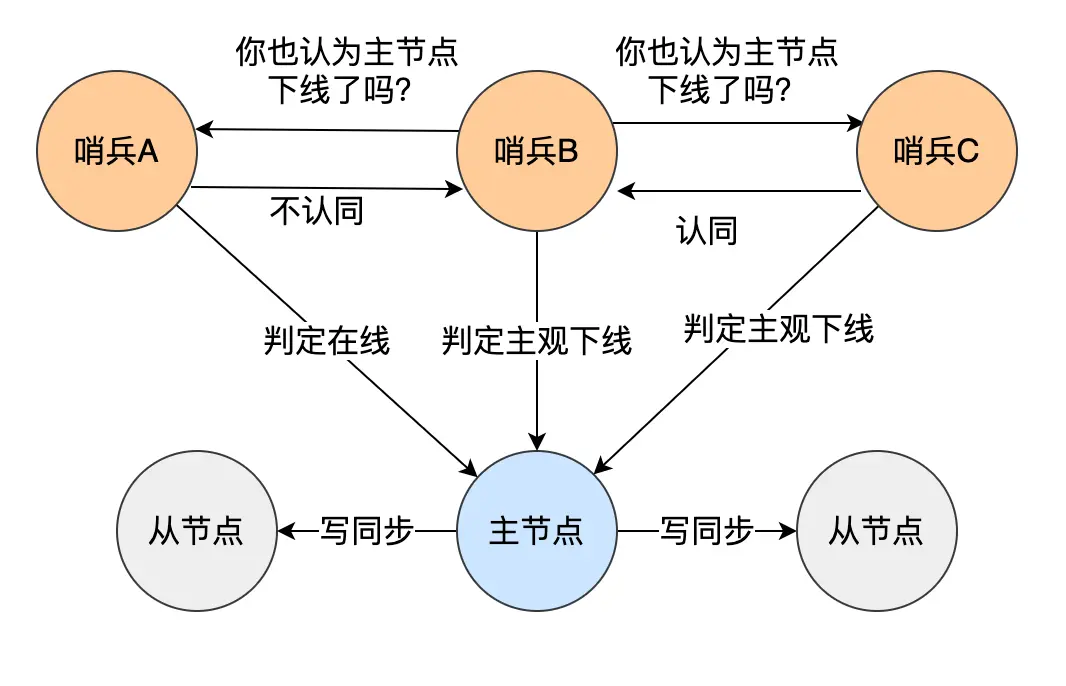
哨兵判断主节点客观下线后,就要开始在多个从节点中,选出一个来做新的主节点
由哪个哨兵进行主从故障转移?
需要在哨兵集群中选出一个 leader,让 leader 来执行主从切换
如何选举 leader?
- 确定候选者
- 哪个哨兵节点判断主节点「客观下线」,这个哨兵节点就是候选者
- 如果某个时间点,刚好有多个哨兵节点判断到主节点为客观下线,就会有多个候选者
- 所有哨兵节点投票决定哪个候选者成为 leader
- 投票规则:
- 每个哨兵节点都只有一票,不能弃票,不能多投
- 候选者哨兵节点可以投票给自己,也可以投票给其他一个候选者
- 非候选者哨兵节点只能投票给候选者之一
- 投票过程中,任何一个「候选者」同时满足两个条件就选举成功:
- 第一:拿到半数以上的赞成票
- 第二:拿到的票数大于等于哨兵配置文件中的
quorum值
- 如果没有满足条件,就需要重新进行选举
- 投票规则:
主从故障转移的过程是怎样的?
步骤一:选出新主节点
在已下线主节点(旧主节点)属下的所有从节点中挑选出一个从节点,将其转换为主节点(新主节点)
如何挑选出一个状态良好、数据完整的从节点?
首先:过滤掉网络连接状态不好的节点
- 配置项
down-after-milliseconds是主从节点断连的最大连接超时时间(单位为毫秒) - 如果在这个时间内,主从节点都没有通过网络联系上,就认为主从节点断连了
- 如果发生断连的次数超过 10 次,就说明这个从节点的网络状况不好,不适合作为新主节点
第一轮考察:优先级最高的从节点胜出
配置项 slave-priority 可以给从节点设置优先级,我们可以根据服务器性能配置来设置从节点的优先级
当有且仅有一个优先级最高的从节点,就将它选为新主节点
第二轮考察:复制进度最靠前的从节点胜出
如果在第一轮考察中,优先级最高的从节点不止一个,就在这几个节点中进行第二轮考察
如果其中某个从节点的 slave_repl_offset 最接近 master_repl_offset,说明它的复制进度是最靠前的,就将它选为新主节点
第三轮考察:ID 号小的从节点胜出
如果在第二轮考察中,还是有多个从节点优先级和复制进度都是一样的,就在这几个节点中进行第三轮考察
每个从节点都有一个 ID 编号,可以唯一标识从节点,选择 ID 号最小的成为新主节点
挑选完成后,哨兵 leader 向被选中的从节点发送 SLAVEOF no one 命令,让这个从节点解除从节点的身份,变为主节点
发送 SLAVEOF no one 命令之后,哨兵 leader 会以每秒一次的频率向被升级的从节点发送 INFO 命令(没进行故障转移之前,INFO 命令的频率是每十秒一次),并观察命令回复中的角色信息,当被升级节点的角色信息从原来的 slave 变为 master 时,哨兵 leader 就知道被选中的从节点已经顺利升级为主节点了
步骤二:将从节点指向新主节点
当新主节点出现后,哨兵 leader 下一步要做的就是,让已下线主节点属下的所有「从节点」指向「新主节点」,这一动作可以通过向「从节点」发送 SLAVEOF 命令实现
SLAVEOF <新主节点 IP> <新主节点 Redis 端口>步骤三:通知客户端主节点已更换
通过 Redis 的==发布订阅机制来实现==,哨兵节点几个常见的频道:
| 事件 | 相关频道 | 说明 |
|---|---|---|
| 主库下线事件 | +sdown | 主库进入“主观下线”状态 |
-sdown | 主库退出“主观下线”状态 | |
+odown | 主库进入“客观下线”状态 | |
-odown | 主库退出“客观下线”状态 | |
| 从库重新配置事件 | +slave-reconf-sent | 哨兵发送 SLAVEOF 命令重新配置从库 |
+slave-reconf-inprog | 从库配置了新主库,但尚未进行同步 | |
+slave-reconf-done | 从库配置了新主库,且和新主库完成同步 | |
| 新主库切换 | +switch-master | 主库地址发生改变 |
客户端和哨兵建立连接后,会订阅哨兵提供的频道。主从切换完成后,哨兵就会向 +switch-master 频道发布新主节点的 IP 地址和端口消息,客户端就可以收到这条信息,然后用新主节点的 IP 地址和端口进行通信
步骤四:将旧主节点变为从节点
最后要做的是,继续监视旧主节点,当旧主节点重新上线时,哨兵集群就会向它发送 SLAVEOF 命令,让它成为新主节点的从节点
哨兵集群是如何组成的?
# 配置哨兵节点
# 不需要填其他哨兵节点的信息
sentinel monitor <master-name> <master-ip> <master-redis-port> <quorum>哨兵节点之间如何相互发现?
==哨兵节点通过 Redis 的发布订阅机制相互发现==
在主从集群中,主节点上有一个名为 __sentinel__:hello 的频道,每当一个新哨兵加入集群,就会把自己的 IP 地址和端口信息发布到该频道,其他订阅了该频道的哨兵就可以拿到信息,和新加入的哨兵建立网络连接
哨兵集群会对「从节点」的运行状态进行监控,哨兵集群如何知道「从节点」的信息?
主节点知道所有从节点的信息,哨兵会以每 10 秒一次的频率向主节点发送 INFO 命令来获取所有从节点的信息
哨兵拿到信息就可以根据从节点列表中的连接信息,和每个从节点建立连接,并在这个连接上持续地对从节点进行监控
面试题
主从切换如何减少数据丢失?
主从切换过程中,产生数据丢失的情况有两种:
- 异步复制同步丢失
- 集群产生脑裂数据丢失
不可能保证数据完全不丢失,只能做到数据丢失尽量少
异步复制同步丢失
当客户端发送写请求给主节点时,主节点将写请求异步同步给各个从节点,如果此时主节点还没来得及同步就挂了,数据就丢失了
减少异步复制的数据丢失的方案
设置配置项 min-slaves-max-lag
假设将 min-slaves-max-lag 配置为 10s,当所有的从节点复制和同步数据的延迟都超过了 10s,就会认为 master 如果宕机后损失的数据会很多,master 就拒绝写入新请求。这样就能将 master 和 slave 数据差控制在 10s 内,即使 master 宕机也只是丢失这未复制的 10s 内的数据
当客户端发现 master 不可写后,可以采取降级措施:将数据暂时写入本地缓存和磁盘(或 kafka 消息队列等)中,一段时间(等 master 恢复正常)后重新写入 master
集群产生脑裂数据丢失
集群脑裂:有不止一个主节点可以写入数据
比如:
- 主节点(A)网络出现问题,与所有的从节点和哨兵节点失联,但主节点和客户端的网络是正常的
- 客户端正常进行写操作
- 哨兵节点发现主节点挂了,重新选举出了一个新主节点(B)—— 出现脑裂
- 当旧主节点(A)网络恢复,因为选举出了新主节点(B),这个旧的主节点就被降级成了从节点
- 第一次同步是全量同步,此时的从节点(A)会清空掉自己本地的数据,然后再做全量同步
- 所以,之前客户端在 A 写入的数据就丢失了
总结:由于网络问题,集群节点之间失去联系,主从数据不同步;重新选举,产生两个主节点。等网络恢复,旧主节点降级为从节点,再与新主节点进行同步复制时,会清空自己的缓冲区,导致之前客户端写入的数据丢失
减少脑裂数据丢失的方案
当主节点发现「从节点下线的数量太多」,或者「网络延迟太大」时,禁止写操作,直接把错误返回给客户端
在配置文件可以设置:
min-slaves-to-write n: 主节点必须要有至少 n 个从节点连接,否则主节点会禁止写数据min-slaves-max-lag t:主从数据复制和同步的延迟不能超过 t 秒,否则主节点会禁止写数据
同时设置这两个值,主节点出现假故障时禁止写数据